
Once I encountered a problem with the manipulation of a huge amount of rows in DataBase, which resulted in a really untypical and interesting solution. The challenge: organizing the simultaneous execution of up to several million tasks within one minute. To be precise, I needed to initiate x (extremely large number) of tasks within a minute. Moreover, I needed the ability to manage these tasks, including the ability to add, remove, or change them, while maintaining a reliable storage solution.
The initial approach involved the utilization of an SQL database structured as follows:

The fundamental concept here was to treat each task as an entity, facilitating its management. The precise moment for task execution could be determined within a designated global timeframe. For our purposes, this timeframe would be a maximum repeatable period, capped at a year. It appeared that our tasks would be scheduled yearly at most. In cases where a task didn't necessitate yearly execution, it could be confined to a monthly timeframe.
Calculating the precise minute for task execution was remarkably straightforward. For instance, if a task was slated for 3rd January at 14:05, the calculation would be: 24 hours * 60 minutes * 3 (day in the year) + 14 (hours) * 60 + 5. This computation yielded an integer representing the exact moment for task execution. The 'time_to_run' field stored a list of these calculated integers. In essence, this was a collection of moments when the task needed to be executed, computed at the point of task creation. This approach seemed quite manageable.
However, I encountered a significant performance bottleneck when it came to querying a field containing an array. With a dataset of 10-20 thousand rows, performance was acceptable. Yet, when the dataset extended into the millions, the query process became notably sluggish. Retrieving data alone consumed a considerable amount of time. This solution, unfortunately, proved inadequate for my needs.
To evaluate this, I constructed a table and populated it with mock objects. One such object example is:

Though the numbers are placeholders, they sufficed for the test. Notably, the main distinctions from actual objects were the values within the 'time_to_run' array and the 'trigger_to_run' field, which, in my case, pointed to SQS/SNS topics. I inserted approximately 3.5 million rows into this table, and the query operation took 57 seconds on my laptop(MacBook Pro 2019 yr). While I acknowledge that performance may vary based on hardware capabilities, these figures were substantial. Thus, this solution did not align with my requirements.
A different way how to organize tasks
This prompted a shift in my data structure paradigm. Instead of building an extensive query structure around each task, I envisioned time as the foundational axis. The maximum timeframe for scheduling tasks was firmly established at a year, a constant within the database realm. The new schema adopted this form:
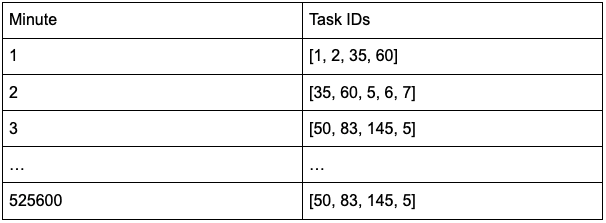
Adopting this approach, the query time is reduced to less than a second, swiftly furnishing a comprehensive list of tasks. Subsequently, detailed task information can be seamlessly retrieved from an in-memory cache database.
For instance, from the provided example of 3.5 million rows, I extracted roughly 100,000 tasks. I meticulously stored detailed information about each one in Redis. Retrieving them from this in-memory database proved to be a breeze. Following this, there are various avenues for executing tasks, contingent on the specific requirements. In my scenario, I only had six distinct SQS destinations to which I needed to dispatch payloads from tasks. Hence, I efficiently grouped them by their respective SQS queues and dispatched them in batches.
However, in instances where an assortment of triggers is in play, all tasks can be directed to an alternate queue. Then, you can attach as many workers as necessary to consume and execute them. This is fundamentally a matter of horizontal scaling.
Nevertheless, this method does come with a particular constraint: task management. It becomes evident that if you intend to add or remove a task, a thorough pass through all rows corresponding to the designated execution time is imperative. This process, while resource-intensive, is a price we willingly pay for the tremendous performance gains and virtually boundless scalability it affords.

Top comments (0)