
A map can be implemented using hashing. Now you understand the concept of hashing. You know how to design a good hash function to map a key to an index in a hash table, how to measure performance using the load factor, and how to increase the table size and rehash to maintain the performance. This section demonstrates how to implement a map using separate chaining.
We design our custom Map interface to mirror java.util.Map and name the interface MyMap and a concrete class MyHashMap, as shown in Figure below.
How do you implement MyHashMap? If you use an ArrayList and store a new entry at the end of the list, the search time will be O(n). If you implement MyHashMap using a binary tree, the search time will be O(log n) if the tree is well balanced. Nevertheless, you can implement MyHashMap using hashing to obtain an O(1) time search algorithm. The code below shows the MyMap interface.
package demo;
public interface MyMap<K, V> {
/** Remove all of the entries from this map */
public void clear();
/** Return true if the specified key is in the map */
public boolean containsKey(K key);
/** Return true if this map contains the specified value */
public boolean containsValue(V value);
/** Return a set of entries in the map */
public java.util.Set<Entry<K, V>> entrySet();
/** Return the value that matches the specified key */
public V get(K key);
/** Return true if this map doesn't contain any entries */
public boolean isEmpty();
/** Return a set consisting of the keys in this map */
public java.util.Set<K> keySet();
/** Add an entry (key, value) into the map */
public V put(K key, V value);
/** Remove an entry for the specified key */
public void remove(K key);
/** Return the number of mappings in this map */
public int size();
/** Return a set consisting of the values in this map */
public java.util.Set<V> values();
/** Define an inner class for Entry */
public static class Entry<K, V> {
K key;
V value;
public Entry(K key, V value) {
this.key = key;
this.value = value;
}
public K getKey() {
return key;
}
public V getValue() {
return value;
}
@Override
public String toString() {
return "[" + key + ", " + value + "]";
}
}
}
The code below implements MyHashMap using separate chaining.
package demo;
import java.util.LinkedList;
public class MyHashMap<K, V> implements MyMap<K, V> {
// Define the default hash-table size. Must be a power of 2
private static int DEFAULT_INITIAL_CAPACITY = 4;
// Define the maximum hash-table size. 1 << 30 is same as 2^30
private static int MAXIMUM_CAPACITY = 1 << 30;
// Current hash-table capacity. Capacity is a power of 2
private int capacity;
// Define default load factor
private static float DEFAULT_MAX_LOAD_FACTOR = 0.75f;
// Specify a load factor used in the hash table
private float loadFactorThreshold;
// The number of entries in the map
private int size = 0;
// Hash table is an array with each cell being a linked list
LinkedList<MyMap.Entry<K, V>>[] table;
/** Construct a map with the default capacity and load factor */
public MyHashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_MAX_LOAD_FACTOR);
}
/** Construct a map with the specified initial capacity and
* default load factor */
public MyHashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_MAX_LOAD_FACTOR);
}
/** Construct a map with the specified initial capacity
* and load factor */
public MyHashMap(int initialCapacity, float loadFactorThreshold) {
if(initialCapacity > MAXIMUM_CAPACITY)
this.capacity = MAXIMUM_CAPACITY;
else
this.capacity = trimToPowerOf2(initialCapacity);
this.loadFactorThreshold = loadFactorThreshold;
table = new LinkedList[capacity];
}
@Override /** Remove all of the entries from this map */
public void clear() {
size = 0;
removeEntries();
}
@Override /** Return true if the specified key is in the map */
public boolean containsKey(K key) {
if(get(key) != null)
return true;
else
return false;
}
@Override /** Return true if this map contains the value */
public boolean containsValue(V value) {
for(int i = 0; i < capacity; i++) {
if(table[i] != null) {
LinkedList<Entry<K ,V>> bucket = table[i];
for(Entry<K, V> entry: bucket)
if(entry.getValue().equals(value))
return true;
}
}
return false;
}
@Override /** Return a set of entries in the map */
public java.util.Set<MyMap.Entry<K, V>> entrySet() {
java.util.Set<MyMap.Entry<K, V>> set = new java.util.HashSet<>();
for(int i = 0; i < capacity; i++) {
if(table[i] != null) {
LinkedList<Entry<K, V>> bucket = table[i];
for(Entry<K, V> entry: bucket)
set.add(entry);
}
}
return set;
}
@Override /** Return the value that matches the specified key */
public V get(K key) {
int bucketIndex = hash(key.hashCode());
if(table[bucketIndex] != null) {
LinkedList<Entry<K, V>> bucket = table[bucketIndex];
for(Entry<K, V> entry: bucket)
if(entry.getKey().equals(key))
return entry.getValue();
}
return null;
}
@Override /** Return true if this map contains no entries */
public boolean isEmpty() {
return size == 0;
}
@Override /** Return a set consisting of the keys in this map */
public java.util.Set<K> keySet() {
java.util.Set<K> set = new java.util.HashSet<K>();
for(int i = 0; i < capacity; i++) {
if(table[i] != null) {
LinkedList<Entry<K, V>> bucket = table[i];
for(Entry<K, V> entry: bucket)
set.add(entry.getKey());
}
}
return set;
}
@Override /** Add an entry (key, value) into the map */
public V put(K key, V value) {
if(get(key) != null) { // The key is already in the map
int bucketIndex = hash(key.hashCode());
LinkedList<Entry<K, V>> bucket = table[bucketIndex];
for(Entry<K, V> entry: bucket)
if(entry.getKey().equals(key)) {
V oldValue = entry.getValue();
// Replace old value with new value
entry.value = value;
// Return the old value for the key
return oldValue;
}
}
// Check load factor
if(size >= capacity * loadFactorThreshold) {
if(capacity == MAXIMUM_CAPACITY)
throw new RuntimeException("Exceeding maximum capacity");
rehash();
}
int bucketIndex = hash(key.hashCode());
// Create a linked list for the bucket if not already created
if(table[bucketIndex] == null) {
table[bucketIndex] = new LinkedList<Entry<K, V>>();
}
// Add a new entry (key, value) to hashTable[index]
table[bucketIndex].add(new MyMap.Entry<K, V>(key, value));
size++; // Increase size
return value;
}
@Override /** Remove the entries for the specified key */
public void remove(K key) {
int bucketIndex = hash(key.hashCode());
// Remove the first entry that matches the key from a bucket
if(table[bucketIndex] != null) {
LinkedList<Entry<K, V>> bucket = table[bucketIndex];
for(Entry<K, V> entry: bucket)
if(entry.getKey().equals(key)) {
bucket.remove(entry);
size--; // Decrease size
break; // Remove just one entry that matches the key
}
}
}
@Override /** Return the number of entries in this map */
public int size() {
return size;
}
@Override /** Return a set consisting of the values in this map */
public java.util.Set<V> values() {
java.util.Set<V> set = new java.util.HashSet<>();
for(int i = 0; i < capacity; i++) {
if(table[i] != null) {
LinkedList<Entry<K, V>> bucket = table[i];
for(Entry<K, V> entry: bucket)
set.add(entry.getValue());
}
}
return set;
}
/** Hash function */
private int hash(int hashCode) {
return supplementalHash(hashCode) & (capacity - 1);
}
/** Ensure the hashing is evenly distributed */
private static int supplementalHash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
/** Return a power of 2 for initialCapacity */
private int trimToPowerOf2(int initialCapacity) {
int capacity = 1;
while(capacity < initialCapacity) {
capacity <<= 1; // Same as capacity *= 2. <= is more efficient
}
return capacity;
}
/** Remove all entries from each bucket */
private void removeEntries() {
for(int i = 0; i < capacity; i++) {
if(table[i] != null) {
table[i].clear();
}
}
}
/** Rehash the map */
private void rehash() {
java.util.Set<Entry<K, V>> set = entrySet(); // Get entries
capacity <<= 1; // Same as capacity *= 2. <= is more efficient
table = new LinkedList[capacity]; // Create a new hash table
size = 0; // Reset size to 0
for(Entry<K, V> entry: set) {
put(entry.getKey(), entry.getValue()); // Store to new table
}
}
@Override /** Return a string representation for this map */
public String toString() {
StringBuilder builder = new StringBuilder("[");
for(int i = 0; i < capacity; i++) {
if(table[i] != null && table[i].size() > 0)
for(Entry<K, V> entry: table[i])
builder.append(entry);
}
builder.append("]");
return builder.toString();
}
}
The MyHashMap class implements the MyMap interface using separate chaining. The parameters that determine the hash-table size and load factors are defined in the class. The default initial capacity is 4 (line 5) and the maximum capacity is 2^30 (line 8). The current hash-table
capacity is designed as a value of the power of 2 (line 11). The default load-factor threshold is 0.75f (line 14). You can specify a custom load-factor threshold when constructing a map. The custom load-factor threshold is stored in loadFactorThreshold (line 17). The data field size denotes the number of entries in the map (line 20). The hash table is an array. Each cell in the array is a linked list (line 23).
Three constructors are provided to construct a map. You can construct a default map with the default capacity and load-factor threshold using the no-arg constructor (lines 26–28), a map with the specified capacity and a default load-factor threshold (lines 32–34), and a map with the specified capacity and load-factor threshold (lines 38–46).
The clear method removes all entries from the map (lines 49–52). It invokes removeEntries(), which deletes all entries in the buckets (lines 221–227). The removeEntries() method takes O(capacity) time to clear all entries in the table.
The containsKey(key) method checks whether the specified key is in the map by invoking the get method (lines 55–60). Since the get method takes O(1) time, the containsKey(key) method takes O(1) time.
The containsValue(value) method checks whether the value is in the map (lines 63–74). This method takes O(capacity + size) time. It is actually O(capacity), since capacity 7 size.
The entrySet() method returns a set that contains all entries in the map (lines 77–90). This method takes O(capacity) time.
The get(key) method returns the value of the first entry with the specified key (lines 93–103). This method takes O(1) time.
The isEmpty() method simply returns true if the map is empty (lines 106–108). This method takes O(1) time.
The keySet() method returns all keys in the map as a set. The method finds the keys from each bucket and adds them to a set (lines 111–123). This method takes O(capacity) time.
The put(key, value) method adds a new entry into the map. The method first tests if the key is already in the map (line 127), if so, it locates the entry and replaces the old value with the new value in the entry for the key (line 134) and the old value is returned (line 136). If the key is new in the map, the new entry is created in the map (line 156). Before inserting the new entry, the method checks whether the size exceeds the load-factor threshold (line 141). If so, the program invokes rehash() (line 145) to increase the capacity and store entries into the new larger hash table.
The rehash() method first copies all entries in a set (line 231), doubles the capacity (line 232), creates a new hash table (line 233), and resets the size to 0 (line 234). The method then copies the entries into the new hash table (lines 236–238). The rehash method takes O(capacity) time. If no rehash is performed, the put method takes O(1) time to add a new entry.
The remove(key) method removes the entry with the specified key in the map (lines 164–177). This method takes O(1) time.
The size() method simply returns the size of the map (lines 180–182). This method takes O(1) time.
The values() method returns all values in the map. The method examines each entry from all buckets and adds it to a set (lines 185–197). This method takes O(capacity) time.
The hash() method invokes the supplementalHash to ensure that the hashing is evenly distributed to produce an index for the hash table (lines 200–208). This method takes O(1) time.
Table below summarizes the time complexities of the methods in MyHashMap.

Since rehashing does not happen very often, the time complexity for the put method is O(1). Note that the complexities of the clear, entrySet, keySet, values, and rehash methods depend on capacity, so to avoid poor performance for these methods you should choose an initial capacity carefully.
The code below gives a test program that uses MyHashMap.
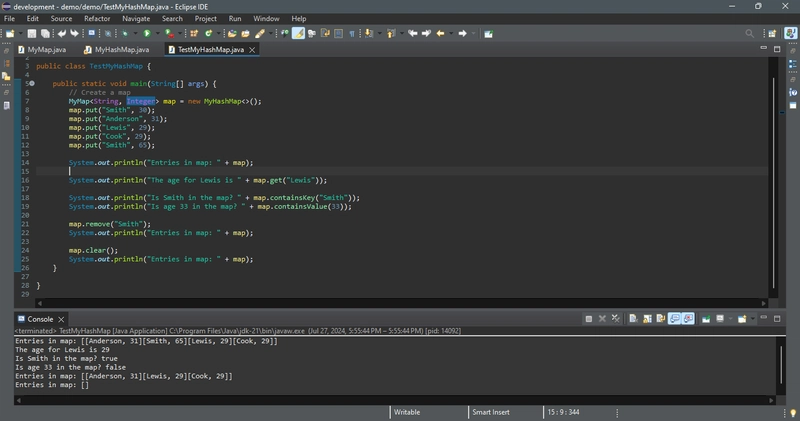
The program creates a map using MyHashMap (line 7) and adds five entries into the map (lines 8–12). Line 5 adds key Smith with value 30 and line 9 adds Smith with value 65. The latter value replaces the former value. The map actually has only four entries. The program displays the entries in the map (line 14), gets a value for a key (line 16), checks whether the map contains the key (line 18) and a value (line 19), removes an entry with the key Smith (line 21), and redisplays the entries in the map (line 22). Finally, the program clears the map (line 24) and displays an empty map (line 25).

Top comments (0)