ASCII Letters – Why They Are Used in English and Other Languages
In the world of computers, everything works with numbers. Computers understand only 0's and 1's.Computers do not understand letters like A, B, C or symbols directly. Instead, they use a special system called ASCII to represent characters.
What is ASCII?
ASCII stands for American Standard Code for Information Interchange.
It is a character encoding system that assigns a numeric value to each letter, number, and symbol so that computers can understand and process text.
How Computer Understands it
Step 1: ASCII given number
'A'-> 65
'B'-> 66
Step 2: Computer converts number to Binary
65-> 1000001
66-> 1000010
So when you type A on the keyboard, the computer actually stores the number 65 internally.
ASCII Range
Total Characters = 128
Range Description
0–31 Control characters(not Printable =we cannot use them)
0 for 'Null',8 for 'Backspace',9 for 'Tab',10 for 'New Line'
32 for 'space'
33–47 Symbols(!,&,%)
48–57 Numbers
58-64(:,;,<,>,=,?,@)
65–90 Uppercase letters
91-96 More Symbols([],^,-,')
97–122 Lowercase letters
123-126 More Symbols({'} ~)
127 Delete(Non Printable)
Why Other Languages Need More Than ASCII
Languages like:
Tamil
Hindi
Chinese
Japanese
Arabic
have many more characters than English.
Since ASCII supports only 128 characters, it cannot represent these languages properly.
To solve this problem, a new system called Unicode was introduced.
Unicode – The Modern Solution
UTF-8(Unicode Transformation Format 8-Bit)
Unicode is a universal character encoding system that supports almost all languages in the world.
~1.1 Million Characters
UTF-8 is a way computers understand and store text.
UTF-8 does not convert Binary later
It already gives Binary values directly.
Steps
Every Character has a Unicode code Point
Example
A-> ut0041
e->ut20AL
UTF-8 converts that Unicode number into a binary format(bytes)
These UTF-8 bytes are already in 0's and 1's ,so the computer stores them directly
7-Bit(7 Binary Digit)
A->65-1000001
B->66-1000010
2^7 = 128 Combinations(0-127)
1 Byte = 8Bits(01000001)
2 Bytes = 16 bits
3 Bytes = 24 bits
4 Bytes = 32 bits
UTF-8 is a modern encoding system that includes ASCII and supports many more characters from all languages.
Examples:
Character Unicode
A U+0041
தமிழ் Supported
हिंदी Supported
中文 Supported
Unicode can represent over 143,000 characters from different languages.
Where ASCII Is Still Used
Even today, ASCII is widely used in:
Programming languages
Text files
Network communication
Data encoding
File formats
Many modern systems like UTF-8 are actually based on ASCII compatibility.
Why ASCII Was Created
In the early days of computing, different computers used different systems to represent text. This created communication problems between machines.
ASCII was created to:
Standardize text representation
Allow computers to exchange information easily
Make programming and data processing simpler
Why ASCII Is Mainly Based on English
ASCII was developed in the United States, so it mainly supports:
English letters (A–Z, a–z)
Numbers (0–9)
Common punctuation marks
Basic control characters
Because of this, the original ASCII table contains 128 characters only.
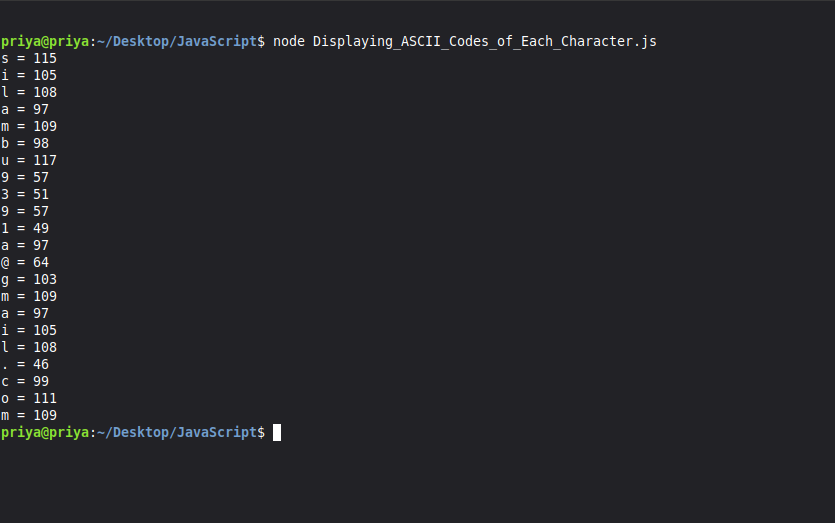
ASCII PROGRAM
In JavaScript,using While Loop
name="silambu9391a@gmail.com"
index=0
while (index < name.length) {
console.log(name[index]+ " = " + name.charCodeAt(index));
index+=1
}
Output
In JavaScript,using For Loop
let name = "silambu9391a@gmail.com"
for(let i = 0;i < name.length; i++){
console.log(name[i] + " " + name.charCodeAt(i));
}
In Python
name = "silambu9391a@gmail.com"
for ch in name:
print(ch,ord(ch))

Top comments (0)