Since the birth of Hadoop, the open-source ecosystem of big data systems has gone through nearly 15 years. In the past 15 years, various computing and storage frameworks have emerged in big data, but they still haven't reached a convergence state. Under the general trend of cloud-native, stream and batch integration, lake and lakehouse integration, there are still many problems to be solved in big data.
LakeSoul is a streaming batch integrated table storage framework developed by DMetaSoul, which has made a lot of design optimization around the new trend of big data architecture systems. This paper explains the core concept and design principle of LakeSoul, the Open-source Project, in detail.
1.Evolution trend of big data system architecture
In recent years, several new computing and storage frameworks have emerged in the field of big data. For example, a common computing engine represented by Spark, Flink, and an OLAP system represented by Clickhouse emerged as computing frameworks. Object storage has become a new storage standard storage, representing an essential base for integrating data lake and lakehouse. At the same time, Alluxio, JuiceFS, and other local cache acceleration layers have emerged. t is not hard to see several key evolution directions in the field of big data:
1. Cloud-native. Public and private clouds provide computing and storage hardware abstraction, abstracting the traditional IaaS management operation and maintenance. An important feature of cloud-native is that both computing and storage provide elastic capabilities. Making good use of elastic capabilities and reducing costs while improving resource utilization is an issue that both computing and storage frameworks need to consider.
2. Real-time. Traditional Hive is an offline data warehouse that provides T+1 data processing. It cannot meet new service requirements. The traditional LAMBDA architecture introduces complexity and data inconsistencies that fail to meet business requirements. So how to build an efficient real-time data warehouse system and realize real-time or quasi-real-time write updates and analysis on a low-cost cloud storage are new challenges for computing and storage frameworks.
3. Diversified computing engines. Big data computing engines are blooming, and while MapReduce is dying out, Spark, Flink, and various OLAP frameworks are still thriving. Each framework has its design focus, some deep in vertical scenarios, others with converging features, and the selection of big data frameworks are becoming more and more diverse.
_4. Data Lakehouse. _Wikipedia does not give a specific definition of Data Lakehouse. In this regard, LakeSoul believes that Data Lakehouse considers the advantages of both data lake and data warehouse. Based on low-cost cloud storage in an open format, functions similar to data structure and data management functions in the data warehouse are realized. It includes the following features: concurrent data reads and writes, architecture support with data governance mechanism, direct access to source data, separation of storage and computing resources, open storage formats, support for structured and semi-structured data (audio and video), and end-to-end streaming.
From the perspective of technology maturity development, the Data Lake is in a period of steady rise and recovery, while the Data Lakehouse is still in the period of expectation expansion, and the technology has not been completely converged. There are still many problems in specific business scenarios.

Considering the latest evolution direction of big data, how to connect various engines and storage in the cloud-native architecture system and adapt to the requirements of the rapidly changing data intelligence services of the upper layer is a problem that needs to be solved in the current big data platform architecture. In order to decode the above issues, first of all, it is necessary to have a set of perfect storage frameworks which can provide high data concurrency, high throughput reading, and writing ability and complete data warehouse management ability on the cloud, and expose such storage ability to multiple computing engines in a common way. That's why LakeSoul was developed and made open-source.
2.Detailed explanation of LakeSoul's design concept
LakeSoul is a unified streaming and batch table storage framework. LakeSoul has the following core features in design:
1.Efficient and scalable metadata management. With the rapid growth of data volumes, data warehouses need to be able to handle the rapid increase in partitions and files. LakeSoul dramatically improves metadata scalability by using a distributed, decentralized database to store Catalog information.
2. Supports concurrent writing. LakeSoul implements concurrency control through metadata services supports concurrent updates for multiple jobs in the same partition, and controls merge or rollback mechanisms by intelligently differentiating write types.
3. Supports incremental writing and Upsert. LakeSoul provides incremental Append and line-level Upsert capabilities and supports Merge on Reading mode to improve data intake flexibility and performance. LakeSoul implements Merge on Read for many update types, which provides high write performance without the need to Read and Merge data while writing. The highly optimized Merge Reader ensures read performance.
4. Real-time Data Warehouses function. LakeSoul supports streaming and batching writes, concurrent updates at the row or column level, framework-independent CDC, SCD, multi-version backtracking, and other common data warehouse features. Combined with the ability of streaming and batch integration, it can support the common real-time data warehouse construction requirements.
The overall architecture of LakeSoul is as follows:
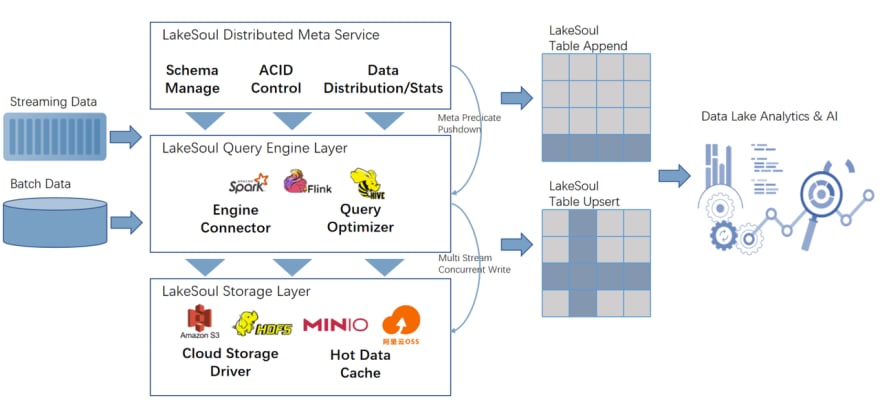
Next, Let's learn more details about the above design points and implementation mechanism.
2.1 Highly extensible Catalog metadata service
LakeSoul supports multi-level partition management, multiple range partitions, and one hash partition at the table partition level. In a real business scenario, a large data warehouse will submit a large amount of partition information to the metadata layer after a long update. For real-time or quasi-real-time update scenarios, submiting is more frequent. In this case, metadata inflation is often encountered, resulting in the low efficiency of metadata access. The metadata performance greatly impacts query performance because partition information and other basic information of data distribution in metadata need to be accessed during data query. Therefore, a high-performance, highly extensible metadata service is important for a data warehouse.
LakeSoul uses the Cassandra distributed database to improve metadata performance and scalability to manage metadata. Cassandra is a decentralized distributed NoSQL database that provides rich data modeling methods, and high read/write throughput. Cassandra can also be easily scaled out. Using Cassandra as storage for metadata services also offers adjustable levels of Availability and consistency, enabling easy concurrency control and ACID for metadata operations.
LakeSoul organizes the primary key and index of the metadata layer table. Only one primary key operation is required for a leaf level partition to obtain all the information for that partition, read and write the snapshot of the current version, and so on. The snapshot of a partition contains the full file path and commit type for full write and incremental updates. This partition read plan can be built by sequential traversing of file commits in the snapshot. On the one hand, partition information access is efficient. On the other hand, it avoids the traversal of files and directories, a required optimization method for object storage systems such as S3 and OSS. Partition management mechanism of LakeSoul:
In contrast, Hive uses MySQL as the metadata storage layer. In addition to scalability problems, Hive also has a bottleneck in the efficiency of querying partition information. Managing more than thousands of partitions in a single table isn't easy. LakeSoul also supports many partitions than Iceberg and Delta Lake, which use file systems to store metadata.
2.2 ACID transactions and concurrent writes
To ensure consistency of concurrent writing and reading of data, LakeSoul supports ACID transactions and concurrent updates. Unlike the OLTP scenario, lakehouse updates are file-level granular.LakeSoul uses Cassandra's Light Weight Transaction to implement partition level updates. Cassandra is not a complete relational transaction database, but it can provide updated atomicity and isolation through LWT. On the other hand, Availability and consistency can be controlled by Cassandra's consistency level. Consistency levels can be selected based on the needs of the business scenario, providing greater flexibility.
Specifically, when the computing engine produces files for each partition to commit, it first commits the partition file update information, such as full Update or incremental Update, and then updates the reader-visible version via LWT. In scenarios where concurrent updates are detected, LakeSoul will automatically distinguish between write types to determine whether there is a conflict and decide whether to resubmit the data directly or roll back the calculation.
2.3 Incremental Update and Upsert
With the support of an efficient metadata layer, LakeSoul can quickly implement an incremental update mechanism. LakeSoul supports multiple update mechanisms, including Append, Overwrite, and Upsert. Common log streaming writes are usually in Append. In this case, the metadata layer only needs to record the file paths appended by each partition. At the same time, the Read data job reads all appended files in the partition uniformly to complete the Merge on read. For Overwrite situations, when an Update/Delete occurs under arbitrary conditions, or when a Compaction occurs, LakeSoul uses a Copy on Write mechanism to Update.
LakeSoul supports a more efficient Upsert mechanism in the case of hash partitions and Upsert operations on hash keys. Within each hash bucket, LakeSoul sorts the files by the hash key. After executing Upsert multiple times, you have multiple ordered files. Merge on Reading for a Read operation by simply merging these ordered files. Upsert is shown as follows:
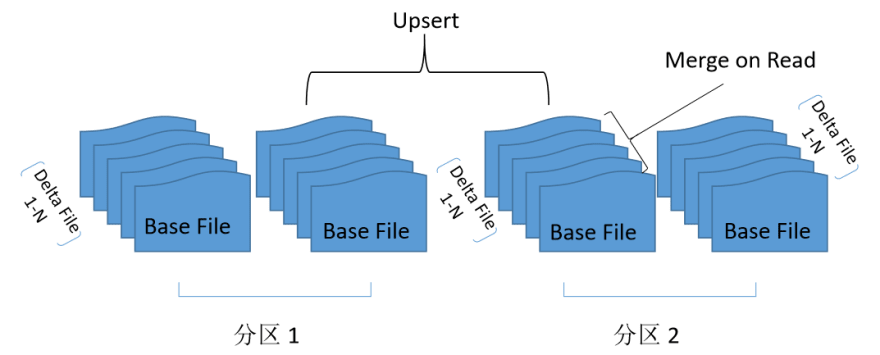
In this way, LakeSoul achieves high write throughput while maintaining read speed through highly optimized ordered file merging.
2.4 Real-time counting function
LakeSoul is committed to simplifying the landing application of big data lakehouse, hoping to provide concise and efficient real-time data warehouse capability for data development. For this purpose, LakeSoul has specially developed and optimized several practical functions, including CDC, SCD, TimeTravel, etc., for the common business scenarios of the real-time data warehouse.
LakeSoul CDC provides a separate set of CDC semantic expressions. LakeSoul can interconnect with various CDC acquisition sources such as Debezium, Flink, and Canal by specifying an operation column in the CDC undertake table as the CDC semantic column. Convert the action column of the collection source to the LakeSoul CDC action column. In the case of online OLTP database synchronization to LakeSoul, LakeSoul's accepting table can also adopt the hashing bucket method and write CDC into Upsert for hashed keys, achieving a very high CDC synchronization speed.
3. LakeSoul application scenario Example
3.1 CDC Real-time Large-screen Report Synchronization
To analyze the data in the online database in real-time, it is usually necessary to synchronize the online data to the data warehouses and then perform data analysis, create BI reports and display large screens in the data warehouse. For example, during the e-commerce promotion festival, it is better to reveal the consumption amount, order number, and inventory number of provinces, regions, and groups on a large screen. However, these transaction data come from the online transaction database, so it is necessary to import the data into the data warehouse for multidimensional report analysis. If a periodic dump database is used in such scenarios, the delay and storage overhead is too high to meet the timeliness requirements. Besides, real-time calculation of Flink has the problem of cumbersome development operation and maintenance.
Using LakeSoul CDC real-time synchronization and converting to Upsert in case of the primary key operation, extremely high write throughput can be achieved. Data changes in the online database can be synchronized to the data warehouse in a near real-time manner, and then BI analysis of online data can be carried out quickly through SQL query. Through Debezium can support a variety of online databases, including MySQL, Oracle, and so on. The application of CDC into the data lake can greatly simplify the data lakehouse real-time intake update architecture.
LakeSoul provides a LakeSoul CDC MVP validation document: https://github.com/meta-soul/LakeSoul/blob/main/examples/cdc_ingestion_debezium/README-CN.md, which contains a complete real-time with the CDC into the example of the lake, Interested can refer to.
3.2 Real-time sample database construction of recommendation algorithm system
A common requirement in the recommendation algorithm scenario is to combine multiple tables, including user features, product features, exposure labels, and click labels, to build a sample library for model training. Offline Join also has problems of low timeliness and high consumption of computing resources. However, many previous schemes use Flink to carry out multi-stream Join through the real-time stream. However, in the case of a large time window, Flink also occupies high resources.
In this case, LakeSoul can be used to build a real-time sample library to convert a multi-stream Join into a multi-stream concurrent Upsert. Since different streams have the same primary key, you can set that primary key to a hash partition key for efficient Upsert. This approach can support Upsert with large-time Windows while ensuring high write throughput.
Above is the design concept and application case of LakeSoul. It can be seen from these that LakeSoul is very innovative and has advantages in performance. This is also the reason why I choose to use LakeSoul, although it is only an open-source project with the star of only 500.

Top comments (0)