
Friendships are hard to maintain. So much energy is wasted maintaining friendships that might not actually provide any tangible returns. I find myself thinking "Sure I've known her since kindergarten, she introduced me to my wife, and let me crash at her place for 6 months when I was evicted, but is this really a worthwhile friendship?".
I need to decide which friends to ditch. But what's the criteria? Looks? Intelligence? Money?
Surely, the value of an individual is subjective. There's no way to benchmark it empirically, right? WRONG. There is one surefire way to way to measure the worth of a friend: the amount of emoji reactions received on Facebook Messenger.

More laughing reactions means that's the funny friend. The one with the most angry reactions is the controversial one. And so on. Simple!
Counting manually is out of the question; I need to automate this task.
Getting the data
Scraping the chats would be too slow. There's an API, but I don't know if it would work for this. It looks scary and the documentation has too many words! I eventually found a way to get the data I need:
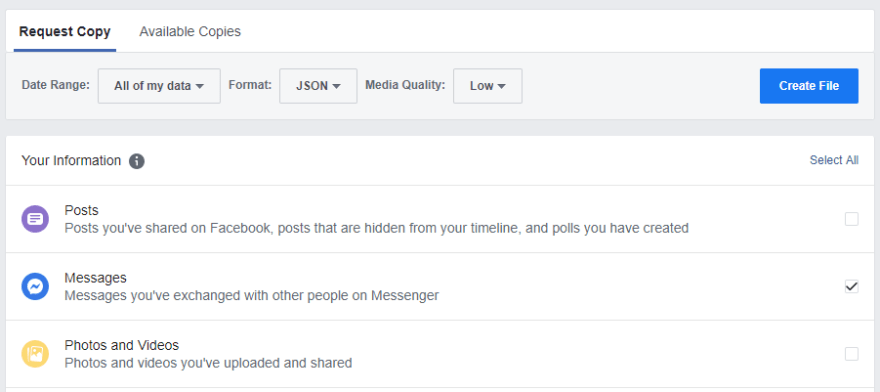
Facebook lets me download all the deeply personal information they collected on me over the years in an easily readable JSON format. So kind of them! I make sure to select only the data I need (messages), and select the lowest image quality, to keep the archive as small as possible. It can take hours or even days to generate.
The next day, I get an email notifying me that the archive is ready to download (all 8.6 GB of it) under the "Available Copies" tab. The zip file has the following structure:
messages
├── archived_threads
│ └── [chats]
├── filtered_threads
│ └── [chats]
├── inbox
│ └── [chats]
├── message_requests
│ └── [chats]
└── stickers_used
└── [bunch of PNGs]
The directory I am interested in is inbox. The [chats] directories have this structure:
[ChatTitle]_[uniqueid]
├── gifs
│ └── [shared gifs]
├── photos
│ └── [shared photos]
├── videos
│ └── [shared videos]
├── files
│ └── [other shared files]
└── message_1.json
The data I need is in message_1.json. No clue why the _1 suffix is needed. In my archive there was no message_2.json or any other variation.
For example, if the chat I want to use is called "Nude Volleyball Buddies", the full path would be something like messages/inbox/NudeVolleyballBuddies_5tujptrnrm/message_1.json.
These files can get pretty big, so don't be surprised if your fancy IDE faints at the sight of it. The chat I want to analyze is about 5 years old, which resulted in over a million lines of JSON.
The JSON file is structured like this:
{
"participants": [
{ "name": "Ricardo L" },
{ "name": "etc..." }
],
"messages": [
" (list of messages...) "
],
"title": "Nude Volleyball Buddies",
"is_still_participant": true,
"thread_type": "RegularGroup",
"thread_path": "inbox/NudeVolleyballBuddies_5tujptrnrm"
}
I want to focus on messages. Each message has this format:
{
"sender_name": "Ricardo L",
"timestamp_ms": 1565448249085,
"content": "is it ok if i wear a sock",
"reactions": [
{
"reaction": "\u00f0\u009f\u0098\u00a2",
"actor": "Samuel L"
},
{
"reaction": "\u00f0\u009f\u0098\u00a2",
"actor": "Carmen Franco"
}
],
"type": "Generic"
}
And I found what I was looking for! All the reactions listed right there.
Reading the JSON from JavaScript
For this task, I use the FileReader API:
<input type="file" accept=".json" onChange="handleChange(this)">
function handleChange(target) {
const reader = new FileReader();
reader.onload = handleReaderLoad;
reader.readAsText(target.files[0]);
}
function handleReaderLoad (event) {
const parsedObject = JSON.parse(event.target.result);
console.log('parsed object', parsedObject);
}
I see the file input field on my page, and the parsed JavaScript object is logged to the console when I select the JSON. It can take a few seconds due to the absurd length. Now I need to figure out how to read it.
Parsing the data
Let's start simple. My first goal is to take my messages_1.json as input, and something like this as the output:
output = [
{
name: 'Ricardo L',
counts: {
'😂': 10,
'😍': 3,
'😢': 4,
},
},
{
name: 'Samuel L',
counts: {
'😂': 4,
'😍': 5,
'😢': 12,
},
},
// etc for every participant
]
The participants object from the original JSON already has a similar format. Just need to add that counts field:
const output = parsedObject.participants.map(({ name }) => ({
name,
counts: {},
}))
Now I need to iterate the whole message list, and accumulate the reaction counts:
parsedObject.messages.forEach(message => {
// Find the correct participant in the output object
const outputParticipant = output.find(({ name }) => name === message.sender_name)
// Increment the reaction counts for that participant
message.reactions.forEach(({ reaction }) => {
if (!outputParticipant.counts[reaction]) {
outputParticipant.counts[reaction] = 1
} else {
outputParticipant.counts[reaction] += 1
}
})
})
This is how the logged output looks like:

I'm getting four weird symbols instead of emojis. What gives?
Decoding the reaction emoji
I grab one message as an example, and it only has one reaction: the crying emoji (😢). Checking the JSON file, this is what I find:
"reaction": "\u00f0\u009f\u0098\u00a2"
How does this character train relate to the crying emoji?
It may not look like it, but this string is four characters long:
\u00f0\u009f\u0098\u00a2
In JavaScript, \u is a prefix that denotes an escape sequence. This particular escape sequence starts with \u, followed by exactly four hexadecimal digits. It represents a Unicode character in UTF-16 format. Note: it's a bit more complicated than that, but for the purposes of this article we can consider everything as being UTF-16.
For instance, the Unicode hex code of the capital letter S is 0053. You can see how it works in JavaScript by typing "\u0053" in the console:

Looking at the Unicode table again, I see the hex code for the crying emoji is 1F622. This is longer than four digits, so simply using \u1F622 wouldn't work. There are two ways around this:
UFT-16 surrogate pairs. This splits the big hex number into two smaller 4-digit numbers. In this case, the crying emoji would be represented as
\ud83d\ude22.Use the Unicode code point directly, using a slightly different format:
\u{1F622}. Notice the curly brackets wrapping the code.
In the JSON, each reaction uses four character codes without curly brackets, and none of them can be surrogate pairs because they're not in the right range.
So what are they?
Let's take a look at a bunch of possible encodings for this emoji. Do any of these seem familiar?
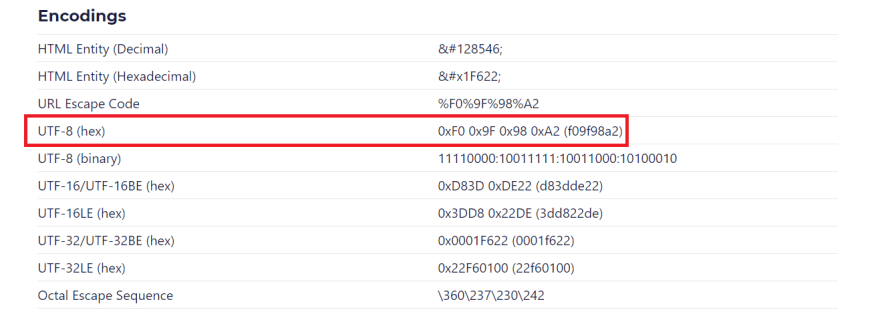
That's pretty close! Turns out this is a UTF-8 encoding, in hex format. But for some reason, each byte is written as a Unicode character in UTF-16 format.
Knowing this, how do I go from \u00f0\u009f\u0098\u00a2 to \uD83D\uDE22?
I extract each character as a byte, and then merge the bytes back together as a UTF-8 string:
function decodeFBEmoji (fbString) {
// Convert String to Array of hex codes
const codeArray = (
fbString // starts as '\u00f0\u009f\u0098\u00a2'
.split('')
.map(char => (
char.charCodeAt(0) // convert '\u00f0' to 0xf0
)
); // result is [0xf0, 0x9f, 0x98, 0xa2]
// Convert plain JavaScript array to Uint8Array
const byteArray = Uint8Array.from(codeArray);
// Decode byte array as a UTF-8 string
return new TextDecoder('utf-8').decode(byteArray); // '😢'
}
So now I have what I need to properly render the results:

Selecting a friend to ditch
I want to calculate a score based on the count of each type of reaction. I need some variables:
- Total message count for participant (T)
- Total reactions sent by participant (SR)
- Global average message count per participant (AVG)
And for the received reactions, I made some categories:
- 👍: Approval (A)
- 👎: Disapproval (D)
- 😆 and 😍: Positive emotion (PE)
- 😢 and 😠: Negative emotion (NE)
- 😮: Neutral, I'll chuck it
The final formula is:

The higher the resulting score, the better the person. Here is an explanation of how I reached this equation.
In JavaScript it would go something like this:
participants.forEach((participant) => {
const {
reactions,
sentReactionCount,
messageCount,
} = participant
const approval = reactions['👍']
const disapproval = reactions['👎']
const positiveEmotion = reactions['😆'] + reactions['😍']
const negativeEmotions = reactions['😢'] + reactions['😠']
const positiveFactor = (2 * approval + 3 * positiveEmotion + sentReactionCount)
const negativeFactor = (2 * disapproval + 3 * negativeEmotions)
const totalMessageFactor = Math.abs(messageCount - messageCountAverage) / (messageCountAverage)
participant.score = (positiveFactor - negativeFactor) / totalMessageFactor
})
Displaying the information in table form makes it easier to parse:
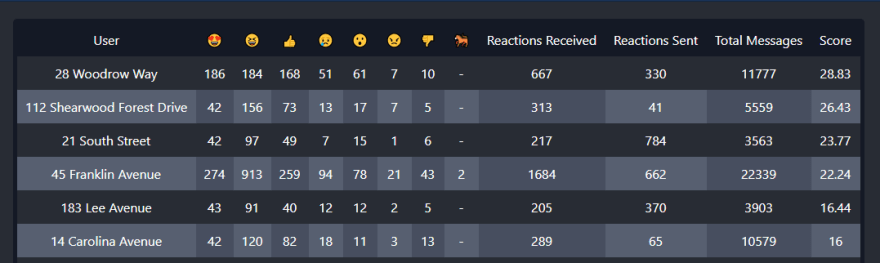
Note: Due to privacy concerns I replaced my friend's real names with their home addresses.
Goodbye
With a quick look at the table I can finally decide who I need to remove from my life.
Farewell, cousin Sam.

{kind=link}
Top comments (10)
"Due to privacy concerns I replaced my friend's real names with their home addresses" ROFL :D
The explanation for how you derived your formula is definitely top-tier Mathematics. 👌
This is both interesting and savangly funny, I might tinker with this soon
That was a nice piece of recreational programming, shared in the form of a story.
Thanks for sharing it with us :D \u{1F604}
W8 you had to do all of this and not automate the last part? 😫
You mean the unfriending? I thought about it, but I was already rushing the final part of the article as is 😅
This is really interesting. Learnt a lot from it. I am definitley trying this 100%😂😁
A developer wandering off can have destructive ideas. Loved your one.
Trying to unzip this on windows and getting invalid file errors. Can you tell me how you extracted the zip and on what os?
Both Windows and macOS with the default unzipper worked fine. I'm pretty sure your zip is corrupted, try downloading again.