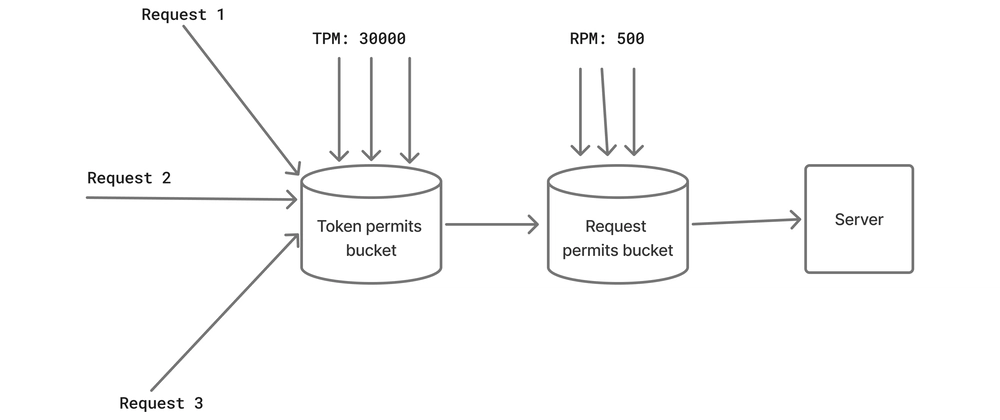
Handling rate limited APIs optimally is important for faster execution of parallel requests. OpenAI imposes two kinds of limits:
- Request rate limit: This is a limit on the number of requests that can be a made in a certain time period.
- Token rate limit: This is a limit on the number of tokens that can be consumed in a certain time period.
We use the GPT-4o model in this case but this can be reproduced using other models in the same way. The rate limits are mentioned as tokens per minute (TPM) and requests per minute (RPM) respectively. The limits for GPT-4o under Tier 1 are as follows:
TPM : 30000, RPM: 500
It is important to understand certain topics before we move forward.
Exponential Backoff
Exponential Backoff is a method to deal with failed requests. When a request fails, we retry the request again after a period of time, let's say 30s. If the request fails again, we retry it after 60s and so on. We terminate this process when the request fails a certain number of times so as not to continue this forever and investigate the cause of failure. We can additionally add a random jitter before trying so that multiple failed requests are not retried at the same time.
Token bucket algorithm
Imagine a bucket that is filled at a constant rate of 1 token per sec and the bucket capacity is 60 tokens. Suppose every request needs to acquire a certain number of tokens before it can be sent to the server.
We set the following restrictions on requests:
If a request acquires the required number of tokens, it is sent to the server.
If a request fails to acquire the required number of tokens, it is blocked until the bucket is filled with the requirement.
The token bucket algorithm ensures that once the bucket is full, we no longer add additional tokens.
How it works
Tokenize the input and estimate output tokens
Suppose we send a prompt "What is tokenization in large language models?" to the OpenAI Responses API. Since the number of output tokens cannot be known beforehand, making multiple parallel requests requires certain approximations.
Assume that I want an answer that is no longer than 400 tokens. So I set the "max_tokens" field in the API request to 400. Our prompt is tokenized using the JTokkit library using the appropriate encoding to count the number of input tokens. GPT-4o uses o200k_base algorithm for tokenization. The number of tokens in our prompt is 9. The TPM limit is on the total number of tokens which includes both input and output tokens. The total number of tokens for this request is estimated to be 409 (output 400 + input 9).
EncodingRegistry encodingRegistry = Encodings.newDefaultEncodingRegistry();
Encoding encoding = encodingRegistry.getEncodingForModel(ModelType.GPT_4O);
String query = "What is tokenization in large language models?";
ResponseCreateParams params = ResponseCreateParams.builder()
.input(query)
.model(ChatModel.GPT_4O)
.maxOutputTokens(400)
.build();
int estimatedTokensForRequest = encoding.countTokens(query) + 400; // Approximation as the count of input tokens and max output tokens field in params
Initialize the rate limiters for tokens and requests
Suppose every request that we send is the same. We can send a maximum of 30000/409 = 73 requests in a minute.
Let us an initialize a bucket that fills at a constant rate of 30000 tokens per minute. If we need to send more than 73 requests, the other requests will have to wait in a queue until the bucket is filled with more tokens. Once the bucket is filled with the required number of tokens, these requests can proceed to the server.
We achieve this using the RateLimiter class from Guava library.
double tokensPerMinute = 30000;
double requestsPerMinute = 500;
RateLimiter tokenRateLimiter = RateLimiter.create(tokensPerMinute/60);
RateLimiter requestRateLimiter = RateLimiter.create(requestsPerMinute/60);
tokenRateLimiter.acquire(estimatedTokensForRequest);
requestRateLimiter.acquire(1);
The create method has to be initialized with the amount of tokens (called permits in this case) that the bucket should be filled with per second. The acquire method will first try to acquire the required number of permits from the bucket. If it can, the execution proceeds forward otherwise the thread(request) is blocked until the permits are available.
Backoff and retry failed requests after sometime
Even though our buckets are the first way to avoid overloading the OpenAI API, there can be a case where our requests still fail when the limit of 30000 that is promised is not achieved or the API throws a RateLimitException. We wait and retry the request in this case.
int maxTries = 2;
int backOffTime = 60;
try {
// Make the request
}
catch (RateLimitException e) {
System.out.println(e.getMessage());
failedAttempts.addAndGet(1);
if(currentTry == maxTries) {
failedRequests.addAndGet(1);
System.out.printf("Request failed %d times. Stopping retry%n", maxTries);
} else {
System.out.printf("Request failed %d times. Retrying in %d sec%n", currentTry, backOffTime);
try {
Thread.sleep(backOffTime * 1000L);
backOffTime *= 2;
}
catch (InterruptedException e1) {
Thread.currentThread().interrupt();
}
}
}
Code
We simulate this using the same request for simplicity. We use the openai-java library for making the request using the Responses API (the Chat Completions API can be used as well). We use the JTokkit library for tokenizing the prompt. The Guava library is used for implementing the token bucket algorithm. They can be imported using Maven as follows:
<dependencies>
<dependency>
<groupId>com.openai</groupId>
<artifactId>openai-java</artifactId>
<version>0.36.0</version>
</dependency>
<dependency>
<groupId>com.knuddels</groupId>
<artifactId>jtokkit</artifactId>
<version>1.1.0</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>33.4.5-jre</version>
</dependency>
</dependencies>
The code for this example can be found here
Handling rate limits for OpenAI models
Play around by changing the total number of requests, setting a lower token and request limit so that some requests fail and are retried etc.
Other resources:-
openai-java library
OpenAI guide to rate limits
JTokkit library
Guava RateLimiter class
Token bucket algorithm
OpenAI Responses API

Top comments (1)
Good callout on treating request and token limits separately. The teams I compare usually instrument only one of those, then misread bursts as random model instability. When you used this in practice, what did the last few real rate-limit incidents look like: quota or billing drift, RPM or TPM bursts, or backoff logic failing under concurrency? I’m comparing incident patterns across small AI products and would value your breakdown.