
Apache Beam is an open source framework that is useful for cleaning and processing data at scale. It is also useful for processing streaming data in real time. In fact, you can even develop in Apache Beam on your laptop and deploy it to Google Cloud for processing (the Google Cloud version is called DataFlow).
Beyond this, Beam touches into the world of artificial intelligence. More formally, it is used as a part of a machine learning pipelines or in automated deployments of machine learning models ( MLOps ). As a specific example, Beam could be used to clean up spelling errors or punctuation from a Twitter data before the data is sent to a machine learning model that determines if the tweet represents emotion that is happy or sad.
One of the challenges though when working with Beam is how to approach debugging the Python that is used to create data pipelines and how to debug basic functionality on your laptop. In this blog post, I am going to show you 4 ways that can help you improve your debugging.
QUICK NOTE: This blog gives a high level overview of how to debug data pipelines. For a deeper dive you may want to check out this video which talks about unittests with Apache Beam and this video which walks you through the debugging process for a basic data pipeline.
1) Only run time-consuming unit tests if dependent libraries are installed
try:
from apitools.base.py.exceptions import HttpError
except ImportError:
HttpError = None
@unittest.skipIf(HttpError is None,
'GCP dependencies are not installed')
class TestBeam(unittest.TestCase):
If you are using unittest, it is helpful to have a test that only runs if the correct libraries are installed. In the above Python example, I have a try block which looks for a class within a Google Cloud library. If the class isn’t found, the unit test is skipped, and a message is displayed that says 'GCP dependencies are not installed.'
2) Use TestPipeline when running local unit tests
Apache Beam uses a Pipeline object in order to help construct a directed acyclic graph (DAG) of transformations. If you are running tests, you could also use apache_beam.testing.TestPipeline.
Example of a directed acyclic graph
3) Parentheses are helpful
The reference beam documentation talks about using a "With" loop so that each time you transform your data, you are doing it within the context of a pipeline. Example Python pseudo-code might look like the following:
With beam.Pipeline(…)as p:
emails = p | 'CreateEmails' >> beam.Create(self.emails_list)
phones = p | 'CreatePhones' >> beam.Create(self.phones_list)
...
It may also be helpful to construct the transformation without the 'With Block'. The modified pseudo-code would then look like this:
emails_list = [
('amy', 'amy@example.com'),
('carl', 'carl@example.com'),
('julia', 'julia@example.com'),
('carl', 'carl@email.com'),
]
phones_list = [
('amy', '111-222-3333'),
('james', '222-333-4444'),
('amy', '333-444-5555'),
('carl', '444-555-6666'),
]
p = beam.Pipeline(...)
def list_to_pcollection(a_pipeline, a_list_in_memory, a_label):
# () are required to span multiple lines
return ( a_pipeline | a_label >> beam.Create(a_list_in_memory) )
emails = list_to_pcollection(p, emails_list, 'CreateEmails')
phones = list_to_pcollection(p, phones_list, 'CreatePhones')
In either case ('using the with block' or skipping the block), parentheses ARE YOUR FRIEND.
Because Beam can do 'composite transforms' where one transformation 'chains' to the next, multiple lines for transformations are quite likely. As seen in the above example, when you have multiple lines you need to either have parentheses or have the line continuation character ('\').
4) Using labels is recommended but each label MUST be unique
Beam can use labels in order to keep track of transformations. As you can see in the beam pipeline on Google Cloud below, labels make it VERY easy for you to identify different stages of processing.
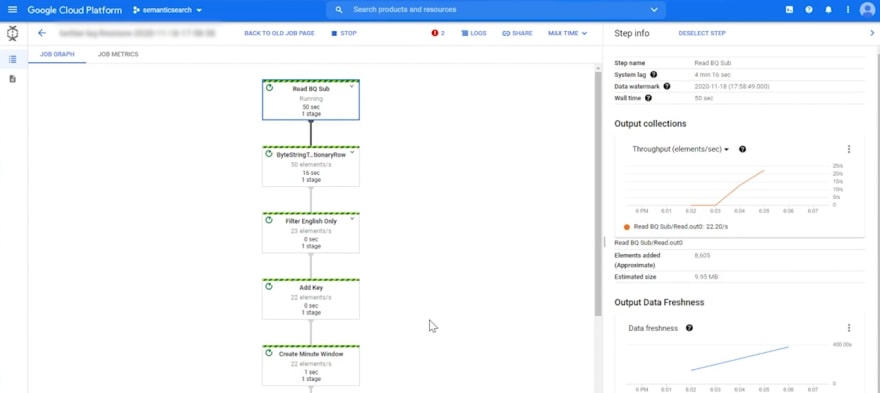
Different Stages of Processing in DataFlow
The main caveat here is that EACH LABEL must be unique. Going back to our example above, the following pseudo-code would fail:
p = beam.Pipeline(...)
def list_to_pcollection(a_pipeline, a_list_in_memory, a_label):
# () are required when there is no WITH loop
return ( a_pipeline | a_label >> beam.Create(a_list_in_memory) )
emails = list_to_pcollection(p, emails_list, 'CreateEmails')
# The line below would cause a failure because labels must be unique
phones = list_to_pcollection(p, phones_list, 'CreateEmails')
However, the following code would work:
index = 1
a_label = “create” + str(index)
emails = list_to_pcollection(p, emails_list, a_label)
index = index + 1
a_label = “create” + str(index)
phones = list_to_pcollection(p, phones_list, a_label)
The bottom line is that if you are programmatically creating labels, you need to make sure they are unique.
SUMMARY
In this post, we reviewed 4 ways that should help you with debugging. To put everything in context, consider the following:
1. Test to see that your dependent libraries are installed:
If you test this first, then you can save time that would be wasted if half of your unit tests run before this error is detected. When you think about how many times tests are run, the time savings in the long run can be significant.
2. Use TestPipeline when running local tests:
Unlike apache_beam.Pipeline, TestPipeline can handle setting PipelineOptions internally. This means that there is less configuration involved in order to get your unit test coded, and less configuration typically means time saved.
3. Parentheses are helpful :
Since PCollections can do multiple transformations all at once ('a composite transform'), it is quite likely that transformations will span multiple lines. When parentheses are used with these multiple lines, you don’t you don't have to worry about forgetting line continuation characters.
4. Using labels is recommended but each label MUST be unique:
Using labels for steps within your pipeline is critical. When you deploy your beam pipeline to Google Cloud, you may notice a step that doesn’t meet performance requirements, and the label will help you QUICKLY identify the problematic code.
As your pipeline grows, it is likely that different transformations of data will be constructed based on functions with different parameters. This is a good thing – it means you are reusing code as opposed to creating something new every time you need to transform data. The main warning here though is that each label MUST be unique; just make sure you adjust your code to reflect this.
NEXT STEPS
Ok – those are 4 steps that hopefully should improve your debugging experience. For more information on how to process data in real-time and for information on how to deploy machine learning models into production, I encourage you to take a look at the new Machine Learning Mastery course that White Owl Education is putting together.

Latest comments (0)