
What was the Problem
When AlexNet won the ImageNet 2012 competition, every one started using more layers in a deep neural network to reduce the error rate. This works for less number of layers, but when we increase the number of layers, there is a common problem arises with it called Vanishing/Exploding gradient. This causes the gradient to become 0 or too large. Thus when we increases number of layers, the training rate decreases only upto a limit and than start increasing.
However in theory, with increase in number of layers, performance of neural network should increase.

*How ResNet solved the Problem*
ResNet used the concept of "Skip Connections" and obviously it worked ;)
For example, consider there are two neural networks as shown in image.
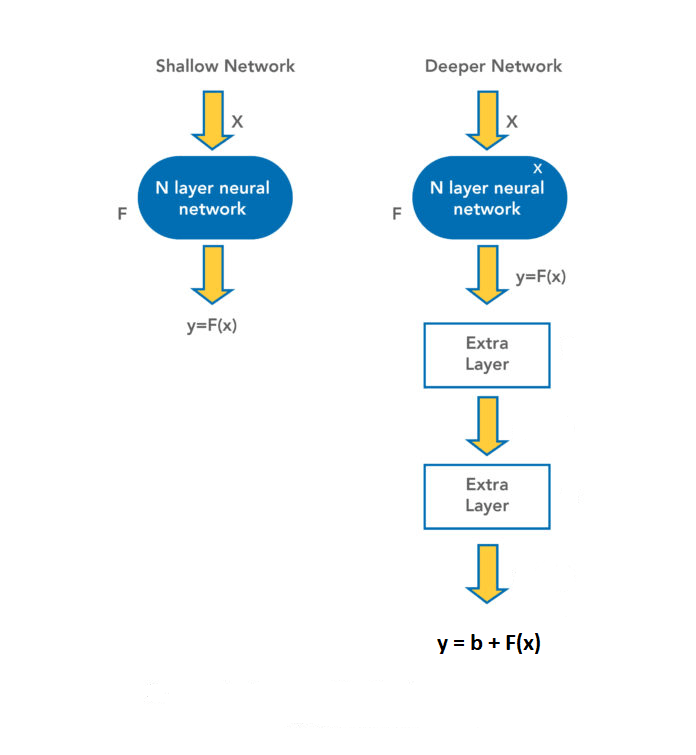
In the first neural network, output is f(x) and there is no problem of vanishing or exploding gradient as the number of layers are less.
And we know that when we will increase the number of layers, output will be changed and this output will not be efficient due to the exploding and vanishing gradient.
Now, in the second neural network (which is deeper, as shown in image), we have added some more layers and due to these layers our output is changed to y = b + f(x) from f(x)
In the second output, if somehow we would be able to make b = 0, than
**y = 0 + f(x)**
In this way, we would be able to make the neural network more deeper, hence we will get more efficient model and also as we are getting the same output(as of shallow network) so there is no effect of vanishing or exploding gradient.
Or in other words, we can say that if input(of the extra layers which we have added to convert shallow network into deeper network) == output than we will get the desired results.
Main idea behind Residual Network is to make b = 0 , so that y=f(x), for deeper neural networks
In shallow network: y = f(x)
In deeper network:
If operations of extra layers = b,
than :
y = f(x) + b
y = f(x) + 0 [b = 0]
Input of extra layers = Output of Extra Layers (b = 0)
ResNet Architecture

How to read ResNet 50 : Convolution operation is done on input image with the filter of size 7*7 and 64 such Filters with stride of 2 and padding of 3.
And than MaxPooling Layer is applied with filter size of 3*3 and stride of 2 and then other operations are applied as shown in image.
Dotted line shows the Convolution Block in Skip Connections.
There are two types of Blocks in ResNet :
a. Identity Block : where input size == output size. Hence there will be no Convolution Layer in Skip Connection.
Example : input image = 56*56*3 --> output image = 56*56*3
b. Convolution Block : where input size of image != output size. Hence there will be a Convolution Layer in the skip connection.
Example : input image = 56*56*3 --> output image = 28*28*128
To make the input == output, we can do two operations. Padding or 1*1 Convolution.
(Convolution of 1*1): (n+2p-f/s)+1 : Padding = 0, hence we get image of size : 28*28
And that's how after performing 1*1 Convolution, input == output.
What's Next :
Coding ResNet
ResNext : https://arxiv.org/abs/1611.05431v2
SeResNext : https://arxiv.org/abs/1709.01507v4
Original ResNet Paper : [https://arxiv.org/pdf/1512.03385v1.pdf]
That's all folks.
If you have any doubt ask me in the comments section and I'll try to answer as soon as possible.
If you love the article follow me on Twitter: [https://twitter.com/guptarohit_kota]
If you are the Linkedin type, let's connect: www.linkedin.com/in/rohitgupta24
Have an awesome day ahead 😀!

Top comments (0)