
By Matt Sarrel, Director of Technical Marketing, MinIO
Delta Lake is an open-source storage framework that is used to build data lakes on top of object storage in a Lakehouse architecture. Delta Lake supports ACID transactions, scalable metadata handling and unified streaming and batch data processing. Delta Lake is commonly used to provide reliability, consistency, and scalability to Apache Spark applications. Delta Lake runs on the top of the existing data lake storage, such as MinIO, and is compatible with Apache Spark APIs.
The original Delta Lake paper (Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores) describes how it was built for cloud object storage. When Vertica tested the use of Delta Lake for external tables, they relied on MinIO. HPE Ezmeral Runtime Enterprise customers run Delta Lake on MinIO. MinIO supports Delta Lake’s requirements for durability because MinIO follows strict read-after-write and list-after-write consistency models for all i/o operations both in distributed and standalone modes and is widely acknowledged to run Delta Lake workloads.
Many organizations rely on cloud native object stores such as MinIO and AWS S3 to house large structured, semi-structured and unstructured datasets. Each table is stored as a set of objects that are Parquet or ORC, and arranged into partitions. Queries over large files are basically scans that execute quickly.
Without Delta Lake, more complex Spark workloads, particularly those that modify, add or remove data, face challenges to performance and correctness under heavy multi-user/multi-app loads. Multi-object updates are not atomic and queries are not isolated, meaning that if a delete is conducted in one query then other concurrent queries will get partial results as the original query updates each object. Rolling back writes is tricky, and a crash in the middle of an update can result in a corrupted table. The real performance killer is metadata – for massive tables with millions of objects that are Parquet files holding billions or trillions of records, metadata operations can bring the applications built on a data lake to a dead stop.

Delta Lake was designed to combine the transactional reliability of databases with the horizontal scalability of data lakes. Delta Lake was built to support OLAP-style workloads with an ACID table storage layer over cloud native object stores such as MinIO. As described in the paper Delta lake: high-performance ACID table storage over cloud object stores, “the core idea of Delta Lake is simple: we maintain information about which objects are part of a Delta table in an ACID manner, using a write-ahead log that is itself stored in the cloud object store.” Objects are encoded in Parquet and can be read by an engine that understands Parquet. Multiple objects can be updated at once “in a serialized manner while still achieving high parallel read and write performance”. The log contains metadata such as min/max statistics for each file, “enabling order of magnitude faster metadata searches” than searching files in the object store directly.
Delta Lake provides the following:
ACID guarantees: Delta Lake ensures that all changes to data are written to storage and committed for durability while being available to users and apps atomically. There are no partial or corrupted files sitting in your data lake anymore.
Scalable data and metadata handling: All reads and writes using Spark (or another distributed processing engine) can scale to petabytes. Unlike most other storage formats and query engines, Delta Lake leverages Spark to scale out all the metadata processing and can efficiently handle metadata of billions of files for petabyte-scale tables.
Audit history and time travel: The Delta Lake transaction log records details about every modification made to data, including a full audit trail of the changes. Data snapshots enable developers to access and revert to earlier versions of data for audits, rollbacks or for any other reason.
Schema enforcement and schema evolution: Delta Lake automatically prevents the insertion of data that does not match the existing table schema. However, the table schema can be explicitly and safely evolved to accommodate changes to data structure and format.
Support for deletes, updates and merges: Most distributed processing frameworks do not support atomic data modification operations on data lakes. In contrast, Delta Lake supports merge, update and delete operations for complex use cases such as change-data-capture, slowly-changing-dimension operations and streaming upserts.
Streaming and batch unification: A Delta Lake table has the ability to work in batch mode and as a streaming source and sink. Delta Lake works across a wide variety of latencies including streaming data ingest and batch historic backfill to provide real-time interactive queries. Streaming jobs write small objects into the table at low latency, later transactionally combining them into larger objects for better performance.
Caching: Relying on object storage means that the objects in a Delta table and its log are immutable and can be safely cached locally - wherever across the multicloud locally is.
Lakehouse architecture, Delta Lake in particular, brings key new functionality to data lakes built on object storage. Delta Lake works with a large and growing list of applications and compute engines such as Spark, Starburst, Trino, Flink, and Hive, and also includes APIs for Scala, Java, Rust, Ruby and Python. Built for the cloud, Kubernetes-native MinIO enables performant, resilient and secure data lake applications everywhere - at the edge, in the data center and in the public/private cloud.

Delta Lake Files
A Delta table is a collection of files that are stored together in a directory (for a file system) or bucket (for MinIO and other object storage). To read and write from object storage, Delta Lake uses the scheme of the path to dynamically identify the storage system and use the corresponding LogStore implementation to provide ACID guarantees. For MinIO, you will use S3A, see Storage configuration — Delta Lake Documentation. It is critical that the underlying storage system used for Delta Lake is capable of concurrent atomic reads/writes, as is MinIO.
Creating Delta tables is really writing files to a directory or bucket. Delta tables are created (opened) by writing (reading) a Spark DataFrame and specifying the delta format and path. In Scala, for example:
// Create a Delta table on MinIO:
spark.range(5).write.format("delta").save("s3a://<your-minio-bucket>/<path-to-delta-table>")
// Read a Delta table on S3:
spark.read.format("delta").load("s3a://<your-mnio-bucket>/<path-to-delta-table>").show()
Delta Lake relies on a bucket per table, and buckets are commonly modeled after file system paths. A Delta Lake table is a bucket that contains data, metadata and a transaction log. The table is stored in Parquet format. Tables can be partitioned into multiple files. MinIO supports S3 LIST to efficiently list objects using file-system-style paths. MinIO also supports byte-range requests in order to more efficiently read a subset of a large Parquet file.

MinIO makes an excellent home for Delta Lake tables due to industry-leading performance. MinIO’s combination of scalability and high-performance puts every workload, no matter how demanding, within reach. MinIO is capable of tremendous performance - a recent benchmark achieved 325 GiB/s (349 GB/s) on GETs and 165 GiB/s (177 GB/s) on PUTs with just 32 nodes of off-the-shelf NVMe SSDs. MinIO more than delivers the performance needed to power the most demanding workloads on Delta Lake.
It’s likely that Delta Lake buckets will contain many Parquet and JSON files, which aligns really well with all of the small file optimizations we’ve built into MinIO for use as a data lake. Small objects are saved inline with metadata, reducing the IOPS needed both to read and write small files like Delta Lake transactions.
Most enterprises require multi-cloud functionality for Delta Lake. MinIO includes active-active replication to synchronize data between locations - on-premise, in the public/private cloud and at the edge. Active-active replication enables enterprises to architect for multi-geo resiliency and fast hot-hot failover. Each bucket, or Delta Lake table, can be configured for replication separately for greatest security and availability.
ACID Transactions with Delta Lake
Adding ACID (Atomicity, Consistency, Isolation and Durability) transactions to data lakes is a pretty big deal because now organizations have greater control over, and therefore greater trust, in the mass of data stored in the data lake. Previously, enterprises that relied on Spark to work with data lakes lacked atomic APIs and ACID transactions, but now Delta Lake makes it possible. Data can be updated after it is captured and written, and with support for ACID, data won’t be lost if the application fails during the operation. Delta Lake accomplishes this by acting as an intermediary between Spark and MinIO for reading and writing data.
Central to Delta Lake is the DeltaLog, an ordered record of transactions conducted by users and applications. Every operation (like an UPDATE or an INSERT) performed on a Delta Lake table by a user is an atomic commit composed of multiple actions or jobs. When every action completes successfully, then the commit is recorded as an entry in the DeltaLog. If any job fails, then the commit is not recorded in the DeltaLog. Without atomicity, data could be corrupted in the event of hardware or software failure that resulted in data only being partially written.
Delta Lake breaks operations into one or more of the following actions:
Add file - adds a file
Remove file - removes a file
Update metadata - records changes to the table’s name, schema or partitioning
Set transaction - records that a streaming job has committed data
Commit info - information about the commit including the operation, user and time
Change protocol - updates DeltaLog to the newest software protocol
It’s not as complicated as it appears. For example, if a user adds a new column to a table and adds data to it, then Delta Lake breaks that down into its component actions - update metadata to add the column and add file for each new file added - and adds them to the DeltaLog when they complete.
Delta Lake relies on optimistic concurrency control to allow multiple readers and writers of a given table to work on the table at the same time. Optimistic concurrency control assumes that changes to a table made by different users can complete without conflicting. As the volume of data grows so does the likelihood that users will be working on different tables. Delta Lake serializes commits and follows a rule of mutual exclusion should two or more commits take place at the same time. In doing so, Delta Lake achieves the isolation required for ACID and the table will look the same after multiple concurrent writes as it would if those writes had occurred serially and separately from each other.
When a user runs a new query on an open table that has been modified since the last time it was read, Spark consults the DeltaLog to determine if new transactions have posted to the table and updates the user’s table with those new changes. This ensures that a user’s version of a table is synchronized with the master table in Delta Lake to the most recent operation and that users cannot make conflicting updates to a table.
DeltaLog, optimistic concurrency control and schema enforcement (combined with the ability to evolve schema) ensure both atomicity and consistency.
Digging into DeltaLog
When a user creates a Delta Lake table, that table’s transaction log is automatically created in the _delta_log subdirectory. As the user modifies the table, each commit is written as a JSON file into the _delta_log subdirectory in ascending order, ie 000000.json, 000001.json, 000002.json and on.

Let’s say we add new records to our table from the data files 1.parquet and 2.parquet. That transaction is added to the DeltaLog and saved as the file 000000.json. Later, we remove those files and add a new file 3.parquet instead. Those actions are recorded as a new file, 000001.json.
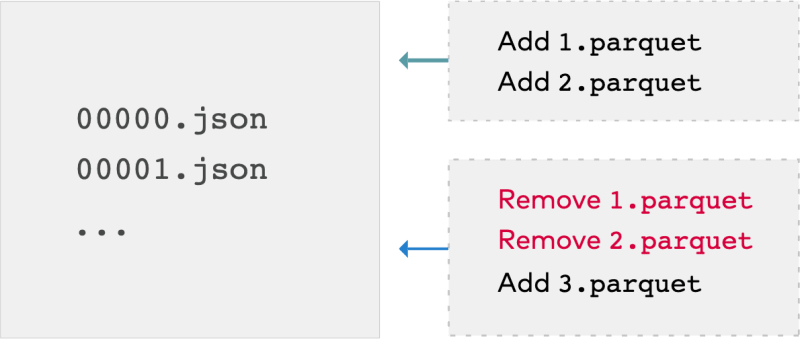
After 1.parquet and 2.parquet were added, they were removed. The transaction log contains both of the operations even though they negate each other. Delta Lake retains all atomic commits to enable complete audit history and time travel features that show users how a table looked at a specific point in time. Furthermore, the files are not quickly removed from storage until a VACUUM job is run. MinIO versioning provides another layer of assurance against accidental deletion.
Durability with Delta Lake and MinIO
Delta Lake achieves durability by storing tables and transaction logs on persistent media. Files are never overwritten and must be actively removed. All data changes written to storage are available to users atomically as they occur. Partial and corrupt files become a thing of the past. Delta Lake does not hold tables and logs in RAM for very long and writes them directly to MinIO. As long as commit data was recorded in the DeltaLog and the JSON files were written to the bucket, data is durable in the event of a system or job crash.
MinIO guarantees durability after a table and its components are written through multiple mechanisms:
Erasure Coding splits data files into data and parity blocks and encodes it so that the primary data is recoverable even if part of the encoded data is not available. Horizontally scalable distributed storage systems rely on erasure coding to provide data protection by saving encoded data across multiple drives and nodes. If a drive or node fails or data becomes corrupted, the original data can be reconstructed from the blocks saved on other drives and nodes.
Bit Rot Protection captures and heals corrupted objects on the fly to remove this silent threat to data durability
Bucket and Object Immutability protects data saved to MinIO from deletion or modification using a combination of object locking, retention and other governance mechanisms. Objects written to MinIO are never overwritten.
Bucket and Object Versioning further protect objects. MinIO maintains a record of every version of every object, even if it is deleted, enabling you to step back in time (much like Delta Lake’s time travel). Versioning is a key component of Data Lifecycle Management that allows administrators to move buckets between tiers, for example to use NVMe for performance intensive workloads, and to set an expiration date on versions so they are purged from the system to improve storage efficiency.
MinIO secures Delta Lake tables using encryption and regulates access to them using a combination of IAM and policy based access controls. MinIO encrypts data in transit with TLS and data on drives with granular object-level encryption using modern, industry-standard encryption algorithms, such as AES-256-GCM, ChaCha20-Poly1305, and AES-CBC. MinIO integrates with external identity providers such as ActiveDirectory/LDAP, Okta and Keycloak for IAM. Users and groups are then subject to AWS IAM-compatible PBAC as they attempt to access Delta Lake tables.
Delta Lake and MinIO Tutorial
This section explains how to quickly start reading and writing Delta tables on MinIO using single-cluster mode.
Prerequisites
Download and install Apache Spark.
Download and install MinIO. Record the IP address, TCP port, access key and secret key.
Download and install MinIO Client.
The following jar files are required. You can copy the jars in any required location on the Spark machine, for example /home/spark.
Hadoop - hadoop-aws-2.6.5.jar - Delta Lake needs the org.apache.hadoop.fs.s3a.S3AFileSystem class from the hadoop-aws package, which implements Hadoop’s FileSystem API for S3. Make sure the version of this package matches the Hadoop version with which Spark was built.
AWS - aws-java-sdk-1.7.4.jar
Set Up Apache Spark with Delta Lake
Start the Spark shell (Scala or Python) with Delta Lake and run code snippets interactively.
In Scala:
bin/spark-shell --packages io.delta:delta-core_2.12:1.2.1 --conf "spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension" --conf "spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog"
Configure Delta Lake and AWS S3 on Apache Spark
Run the following command to launch a Spark shell with Delta Lake and S3 support for MinIO:
bin/spark-shell \
--packages io.delta:delta-core_2.12:1.2.1,org.apache.hadoop:hadoop-aws:3.3.1 \
--conf spark.hadoop.fs.s3a.access.key=<your-MinIO-access-key> \
--conf spark.hadoop.fs.s3a.secret.key=<your-MinIO-secret-key>
--conf "spark.hadoop.fs.s3a.endpoint=<your-MinIO-IP:port> \
--conf "spark.databricks.delta.retentionDurationCheck.enabled=false" \
--conf "spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension" \
--conf "spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog"
Create a Bucket in MinIO
Use the MinIO Client to create a bucket for Delta Lake:
mc alias set minio http://<your-MinIO-IP:port> <your-MinIO-access-key> <your-MinIO-secret-key>
mc mb minio\delta-lake
Create a test Delta Lake table on MinIO
Try it out and create a simple Delta Lake table using Scala:
// Create a Delta table on MinIO:
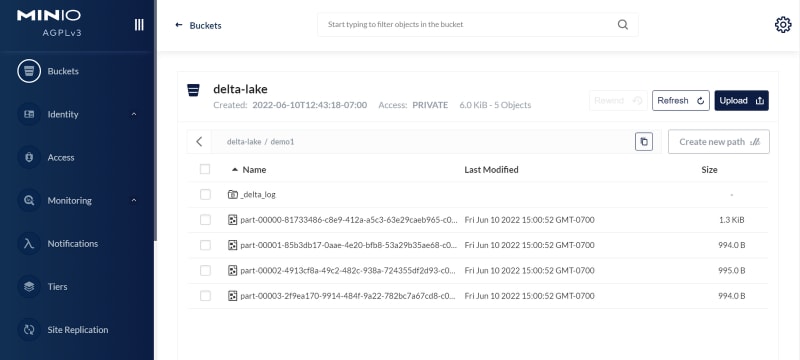
spark.range(500).write.format("delta").save("s3a://delta-lake/demo1")
You will see something output indicating that Spark wrote the table successfully.
Open a browser to log into MinIO at http://your-MinIO-IP:9001 with your access key and secret key. You’ll see the Delta Lake table in the bucket:
MinIO and Delta Lake for High-Performance ACID Transactions on Data Lakes
The combination of MinIO and Delta Lake enables enterprises to have a multi-cloud data lake that serves as a consolidated single source of truth. The ability to query and update Delta Lake tables provides enterprises with rich insights into their businesses and customers. Various groups access Delta Lake tables for their own analytics or machine learning initiatives, knowing that their work is secure and the data timely.
To go deeper, download MinIO and see for yourself or spin up a marketplace instance on any public cloud. Do you have questions? Ask away on Slack or via hello@min.io.

Top comments (0)