
Photo by Marius Masalar on Unsplash
In our last episode we covered a brief introduction about the value of SQL and how it has remained popular for decades.
With that out of the way, we really wanted to focus on how you can improve you SQL.
In today's episode we wanted to discuss a very popular tool in SQL called a common table expression. Also known as CTEs.
CTEs have some similarities to subqueries, although how CTEs are treated does depend on the SQL engine you use (some SQL engines pre-run and store CTEs, others treat them like subqueries).
The can help reduce duplicated sub-queries and logic as well as simplify your query.
However, there is a dark-side to CTEs. They go from helpful to hurtful and many don't realize it.
Let me explain( Video Explanation Here ).
Please Stop Using So Many CTEs
The goal of CTEs is to make code easier to read and reduce repetitive sub-queries.
Let's say you have a table called eligibility that looks like this.

Now you would like it to look like this where every month is normalized out like below.
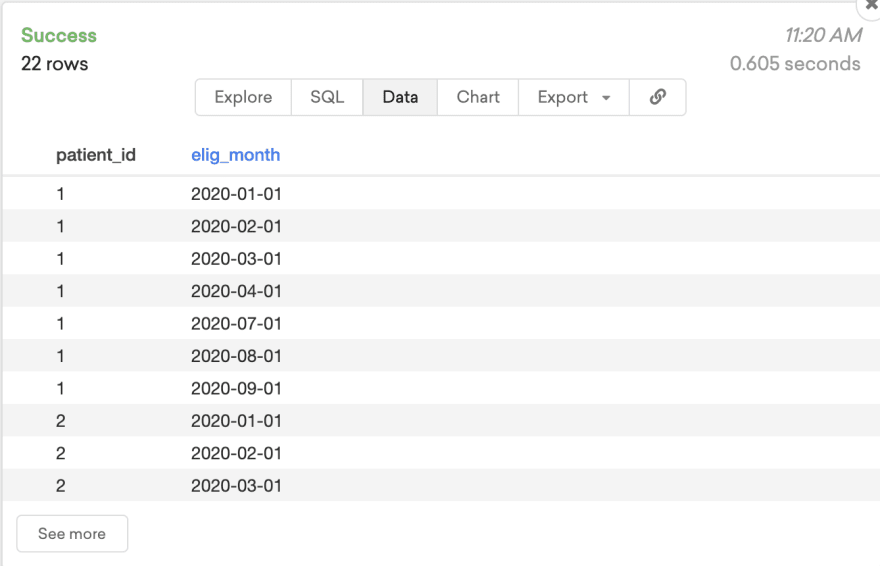
Let's say we would like to then take that data and answer the question, which patients have at least 9 months of eligibility?
One way to do so is to use a date table like in the example below.
with elig_months as
(
SELECT e.patient_id
,count( distinct d.first_date ) total_elig_month
FROM eligibility e
JOIN dim_date d ON d.first_date BETWEEN e.start_date
AND e.end_date
GROUP BY e.patient_id
)
select *
from elig_months
where total_elig_month >=9
Looking at the code above, we will see the CTE that uses a between clause to join on the dates between the start and the end date for the first of the month.
This will normalize the data as in the table above.
Then we can reference the CTE elig_months again in the select and filter on months.
This is a clean way of using a CTE because both bits of logic are clear and would be easy to test.
However, at the same time, CTEs can also make SQL harder to read.
CTEs can be used to separate out a query or reduce redundant select statements.
The problem is that some SQL developers, analysts, and engineers put way too many CTEs in one SQL statement.
This can become very difficult to maintain. For two main reasons.
One it is hard to keep track of all the logic of every column and CTE.
Two it is hard to debug data issues because you don't know which CTE caused the problem.
When you have lots of CTEs stacked on top of each other, it can be difficult to tell where an issue is occurring.
Also, it's very hard to test and see what the result is because each of those sub-queries could be causing a problem.
Especially if you have a CTE, based on a CTE, based on a CTE with columns being altered at every step.
So you can look at the end result of your data, but it will be unclear where the issue happened.
Let's go over an example.
WITH elig_months
AS (
SELECT DISTINCT e.patient_id
,d.first_of_month elig_month
FROM eligibility e
JOIN dim_dates d ON d.DATE BETWEEN e.start_date
AND e.end_date
)
,elig_9_months
AS (
SELECT patient_id
FROM (
SELECT patient_id
,count(DISTINCT elig_month) total_months
FROM elig_months
WHERE year(elig_month) = 2019
GROUP BY patient_id
) t1
WHERE total_months >= 9
)
,category_A
AS (
SELECT min(claim_date) first_claim_date
,patient_id
FROM claims c
JOIN elig_9_months em ON em c.patient_id = em.patient_id
WHERE procedure_code BETWEEN '9990'
AND '10001'
AND age BETWEEN 40
AND 50
GROUP BY patient_id
)
,category_B
AS (
SELECT *
FROM category_A
WHERE date_diff('day', first_claim_date, claim_date) > 30
AND procedure_code BETWEEN '10002'
AND '10301'
)
,category_C
AS (
SELECT max(CASE
WHEN a.patient_id IS NULL
THEN 1
ELSE 0
END) is_category_A
,patient_id
FROM claims c
JOIN elig_9_months em ON em c.patient_id = em.patient_id
LEFT JOIN category_A a ON a.patient_id = em.patient_id
WHERE procedure_code BETWEEN '9950'
AND '9970'
AND age BETWEEN 40
AND 50
)
select case when total_patient_c != 0 then
total_patient_b*1.0/total_patient_c
else total_patient_b
end,
county, state
from
(SELECT count(DISTINCT b.patient_id) total_patient_b
,sum(case when is_category_a then 1 else 0 end) total_patient_c county
,STATE
FROM category_B b
FULL JOIN c ON c.patient_id = b.patient_id
JOIN patient p ON p.patient_id = c.patient_id
JOIN county cc ON p.zipcode = cc.zipcode
)
Let's say you built the query above, and you had an error in the in somewhere. It could be in the data, it could be in the code to load one of the tables, it could be in the SQL.
But it only shows up after you have run all the various logics and are selecting the output.
So how would you find the error(Also, this query is pretty tame, compared to some of the 1500 line SQL statements we have seen)?
In addition, you have nested so much logic on top of each other, basing different CTEs on other CTEs that it can be hard to follow what each field really means.
When you are in the flow state of SQL it's really easy to write this kind of query.
Lot's of logic, going in every which direction, almost creating a spaghetti style SQL clause.
But in the future, you or another developer will struggle.
Solution
There are a few solutions that we can think of.
First, you can start by assessing your CTEs and figuring out if you repeat the same join a lot. One of the obvious places you will find repeat CTEs is around fact tables. Fact tables are tables that are usually at the center of data warehouses and thus have joined to lots of tables like in the image below.
Generally, when you have a fact table, you'll find yourself joining all the dimension tables over and over again.
Instead of using CTEs to do this, you should create a pre-joined table or view this fact table with all the dimensions. This probably solves 70% of this problem. There's still another 30% of more specific queries, where perhaps building an individual table is not conducive.
Another solution is to create temporary tables. Not all SQL engines allow this, but personally, I enjoy the ability to create local temporary tables. Creating temporary tables makes it easy to figure out where your queries went wrong.
We'll talk a little more about QA later, but essentially, if you look at the example below, you can see that it's easy to create unit tests.
Unlike CTEs, where all the logic is spread out and each stage of the data transformation is hard to get to, temporary tables make it easy to analyze what the data looks like at each step.
So when you do have an issue, it's easy to pinpoint where it is.
CTEs Are Great, But Use Them Carefully
Just to clarify, CTEs have their place. They do make code easier to read. If you take a moment and think about what you are writing, it's probably fine.
However, if you go to deep into the flow state of code, you might make a very difficult query to test, maintain and update.
Good luck with your future queries and thanks for reading episode 2!
If you would like to read more, then here are some other great articles and videos.
SQL And Relational Databases Are Dead In 2020, Long Live SQL - CTO TV Episode. 1
Hadoop vs HDFS vs HBase vs Hive - What Is The Difference?
4 Simple Python Ideas To Automate Your Workflow
Automate Data Extracts From Google Sheets With Python
Data Engineering 101: An Introduction To Data Engineering
What Are The Different Kinds Of Cloud Computing

Top comments (1)
Yes 100000000000000% this.
CTE’s in some environments are actually extremely taxing on the resources. Distributed processing platforms like Redshift are forced to copy the CTE to every node involved the query which when you are dealing with hundreds of millions of rows of data SLOWS the query down.
I ban the use of CTE in our production code and only allow them when people are querying away.
Great article !!