
What will be scraped

Full code
If you don't need an explanation, have a look at the full code example in the online IDE
const puppeteer = require("puppeteer-extra");
const StealthPlugin = require("puppeteer-extra-plugin-stealth");
puppeteer.use(StealthPlugin());
const searchString = "javascript developer"; // what we want to search
const encodedString = encodeURI(searchString); // what we want to search for in URI encoding
const requestParams = {
q: encodedString, // our encoded search string
hl: "en", // parameter defines the language to use for the Google search
uule: "w+CAIQICIKY2FsaWZvcm5pYQ", // encoded location
};
const domain = `https://www.google.com`;
async function scrollPage(page, scrollContainer) {
let lastHeight = await page.evaluate(`document.querySelector("${scrollContainer}").scrollHeight`);
while (true) {
await page.evaluate(`document.querySelector("${scrollContainer}").scrollTo(0, document.querySelector("${scrollContainer}").scrollHeight)`);
await page.waitForTimeout(2000);
let newHeight = await page.evaluate(`document.querySelector("${scrollContainer}").scrollHeight`);
if (newHeight === lastHeight) {
break;
}
lastHeight = newHeight;
}
}
async function fillInfoFromPage(page) {
return await page.evaluate(async () => {
return Array.from(document.querySelectorAll(".iFjolb")).map((el) => ({
title: el.querySelector(".BjJfJf").textContent.trim(),
companyName: el.querySelector(".vNEEBe").textContent.trim(),
location: el.querySelectorAll(".Qk80Jf")[0].textContent.trim(),
via: el.querySelectorAll(".Qk80Jf")[1].textContent.trim(),
thumbnail: el.querySelector(".pJ3Uqf img")?.getAttribute("src"),
extensions: Array.from(el.querySelectorAll(".oNwCmf .I2Cbhb .LL4CDc")).map((el) => el.textContent.trim()),
}));
});
}
async function getJobsInfo() {
const browser = await puppeteer.launch({
headless: false,
args: ["--no-sandbox", "--disable-setuid-sandbox"],
});
const page = await browser.newPage();
const URL = `${domain}/search?ibp=htl;jobs&hl=${requestParams.hl}&q=${requestParams.q}&uule=${requestParams.uule}`;
await page.setDefaultNavigationTimeout(60000);
await page.goto(URL);
await page.waitForSelector(".iFjolb");
await page.waitForTimeout(1000);
await scrollPage(page, ".zxU94d");
const jobs = await fillInfoFromPage(page);
await browser.close();
return jobs;
}
getJobsInfo().then((result) => console.dir(result, { depth: null }));
Preparation
First, we need to create a Node.js* project and add npm packages puppeteer, puppeteer-extra and puppeteer-extra-plugin-stealth to control Chromium (or Chrome, or Firefox, but now we work only with Chromium which is used by default) over the DevTools Protocol in headless or non-headless mode.
To do this, in the directory with our project, open the command line and enter npm init -y, and then npm i puppeteer puppeteer-extra puppeteer-extra-plugin-stealth.
*If you don't have Node.js installed, you can download it from nodejs.org and follow the installation documentation.
📌Note: also, you can use puppeteer without any extensions, but I strongly recommended use it with puppeteer-extra with puppeteer-extra-plugin-stealth to prevent website detection that you are using headless Chromium or that you are using web driver. You can check it on Chrome headless tests website. The screenshot below shows you a difference.

Process
First of all, we need to scroll through all job listings until there are no more listings loading which is the difficult part described below.
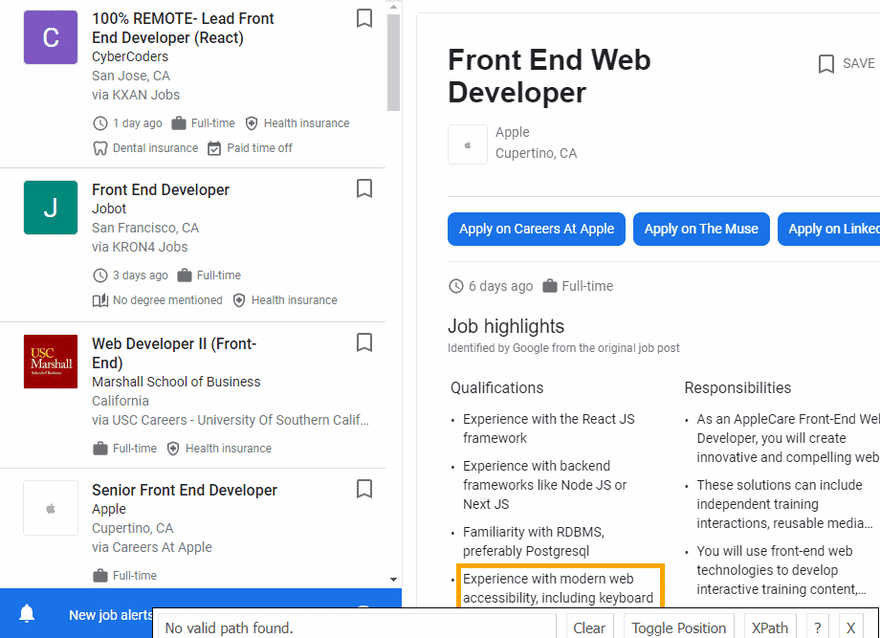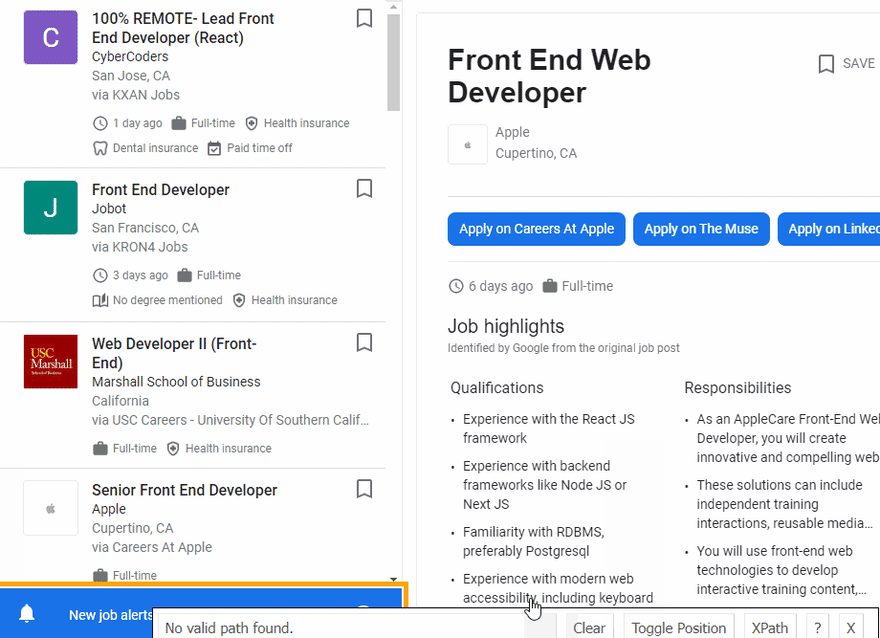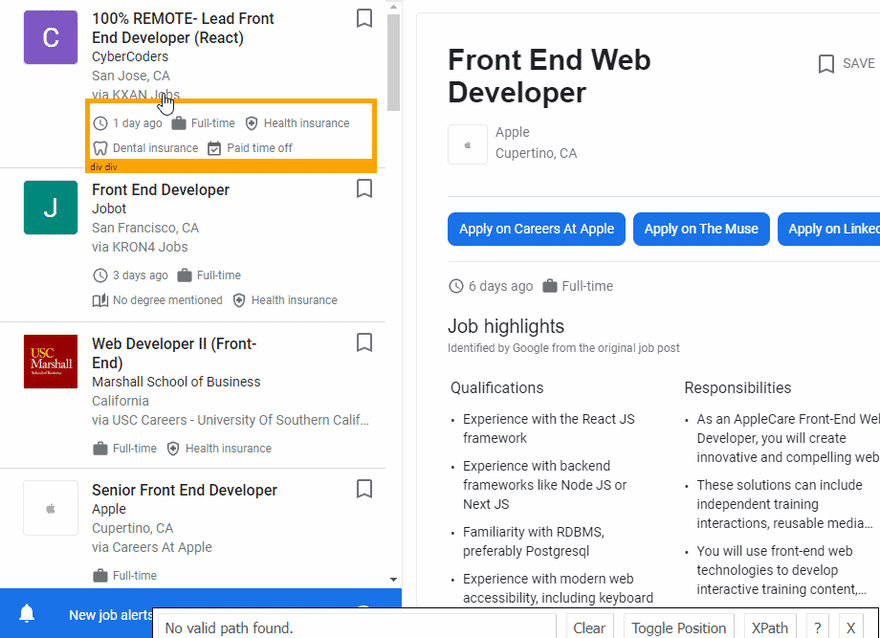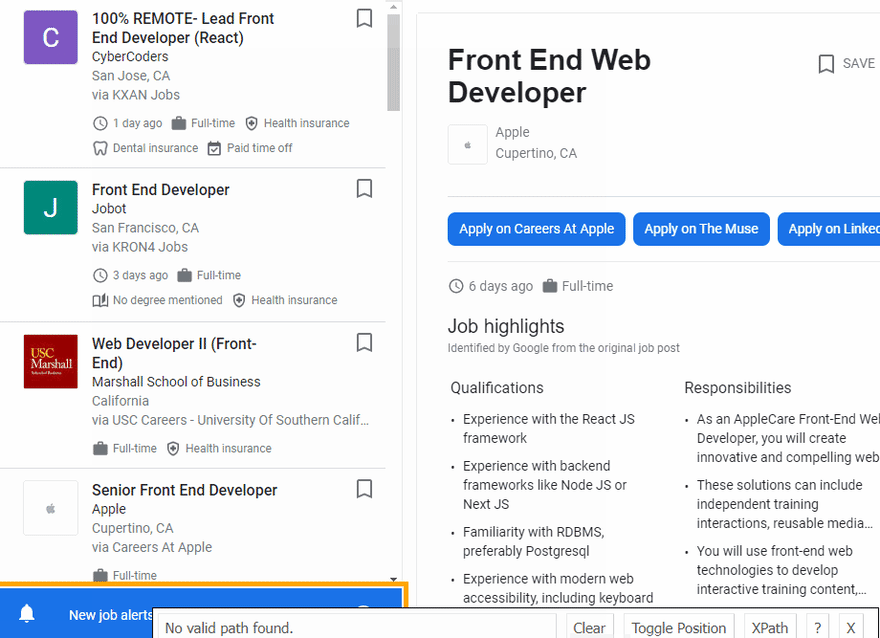
The next step is to extract data from HTML elements after scrolling is finished. The process of getting the right CSS selectors is fairly easy via SelectorGadget Chrome extension which able us to grab CSS selectors by clicking on the desired element in the browser. However, it is not always working perfectly, especially when the website is heavily used by JavaScript.
We have a dedicated web Scraping with CSS Selectors blog post at SerpApi if you want to know a little bit more about them.
The Gif below illustrates the approach of selecting different parts of the results.
Code explanation
Declare puppeteer to control Chromium browser from puppeteer-extra library and StealthPlugin to prevent website detection that you are using web driver from puppeteer-extra-plugin-stealth library:
const puppeteer = require("puppeteer-extra");
const StealthPlugin = require("puppeteer-extra-plugin-stealth");
Next, we "say" to puppeteer use StealthPlugin, write what we want to search and encode it into URI string:
puppeteer.use(StealthPlugin());
const searchString = "javascript developer"; // what we want to search
const encodedString = encodeURI(searchString); // what we want to search for in URI encoding
Next, we write the necessary request parameters and Google domain URL:
📌Note: the uule parameter is an encoded location parameter. You can make it using UULE Generator for Google.
const requestParams = {
q: encodedString, // our encoded search string
hl: "en", // parameter defines the language to use for the Google search
uule: "w+CAIQICIKY2FsaWZvcm5pYQ", // encoded location
};
const domain = `https://www.google.com`;
Next, we write a function to scroll the page to load all the articles:
async function scrollPage(page, scrollContainer) {
...
}
In this function, first, we need to get scrollContainer height (using evaluate() method). Then we use while loop in which we scroll down scrollContainer, wait 2 seconds (using waitForTimeout method), and get a new scrollContainer height.
Next, we check if newHeight is equal to lastHeight we stop the loop. Otherwise, we define newHeight value to lastHeight variable and repeat again until the page was not scrolled down to the end:
let lastHeight = await page.evaluate(`document.querySelector("${scrollContainer}").scrollHeight`);
while (true) {
await page.evaluate(`document.querySelector("${scrollContainer}").scrollTo(0, document.querySelector("${scrollContainer}").scrollHeight)`);
await page.waitForTimeout(2000);
let newHeight = await page.evaluate(`document.querySelector("${scrollContainer}").scrollHeight`);
if (newHeight === lastHeight) {
break;
}
lastHeight = newHeight;
}
Next, we write a function to get jobs data from the page:
async function fillInfoFromPage(page) {
...
}
In this function, we get information from the page context and save it in the returned array. First, we need to get all the jobs results available on the page (querySelectorAll() method) and make the new array from got NodeList (Array.from()):
return await page.evaluate(async () => {
return Array.from(document.querySelectorAll(".iFjolb")).map((el) => ({
Next, we assign the necessary data to each object's key. We can do this with textContent and trim() methods, which get the raw text and removes white space from both sides of the string. If we need to get links, we use getAttribute() method to get "src" HTML element attributes:
title: el.querySelector(".BjJfJf").textContent.trim(),
companyName: el.querySelector(".vNEEBe").textContent.trim(),
location: el.querySelectorAll(".Qk80Jf")[0].textContent.trim(),
via: el.querySelectorAll(".Qk80Jf")[1].textContent.trim(),
thumbnail: el.querySelector(".pJ3Uqf img")?.getAttribute("src"),
extensions: Array.from(el.querySelectorAll(".oNwCmf .I2Cbhb .LL4CDc")).map((el) => el.textContent.trim()),
Next, write a function to control the browser, and get information:
async function getJobsInfo() {
...
}
In this function first we need to define browser using puppeteer.launch({options}) method with current options, such as headless: false and args: ["--no-sandbox", "--disable-setuid-sandbox"].
These options mean that we use headless mode and array with arguments which we use to allow the launch of the browser process in the online IDE. And then we open a new page:
const browser = await puppeteer.launch({
headless: false,
args: ["--no-sandbox", "--disable-setuid-sandbox"],
});
const page = await browser.newPage();
Next, we define the full request URL, change default (30 sec) time for waiting for selectors to 60000 ms (1 min) for slow internet connection with .setDefaultNavigationTimeout() method, go to URL with .goto() method and use .waitForSelector() method to wait until the selector is load:
const URL = `${domain}/search?ibp=htl;jobs&hl=${requestParams.hl}&q=${requestParams.q}&uule=${requestParams.uule}`;
await page.setDefaultNavigationTimeout(60000);
await page.goto(URL);
await page.waitForSelector(".iFjolb");
And finally, we wait until the page was scrolled, save jobs data from the page in the jobs constant, close the browser, and return the received data:
await scrollPage(page, ".zxU94d");
const jobs = await fillInfoFromPage(page);
await browser.close();
return jobs;
Now we can launch our parser:
$ node YOUR_FILE_NAME # YOUR_FILE_NAME is the name of your .js file
Output
[
{
"title":"Python Developer Python-JavaScript and vue.js",
"companyName":"Dice",
"location":"San Francisco, CA",
"via":"via LinkedIn",
"thumbnail":"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQKlgydP7sElaJC9qPrtNHwBhyTMHYgii1RPWsy&s=0",
"extensions":[
"5 days ago",
"Contractor"
]
},
{
"title":"Remote Senior JavaScript Developer",
"companyName":"Jobot",
"location":"Las Vegas, NV",
"via":"via Central Illinois Proud Jobs",
"extensions":[
"4 days ago",
"Full-time",
"No degree mentioned"
]
},
... and other results
]
Using Google Jobs API from SerpApi
This section is to show the comparison between the DIY solution and our solution.
The biggest difference is that you don't need to use browser automation to scrape results, create the parser from scratch and maintain it.
There's also a chance that the request might be blocked at some point from Google, we handle it on our backend so there's no need to figure out how to do it yourself or figure out which CAPTCHA, proxy provider to use.
First, we need to install google-search-results-nodejs:
npm i google-search-results-nodejs
Here's the full code example, if you don't need an explanation:
const SerpApi = require("google-search-results-nodejs");
const search = new SerpApi.GoogleSearch(process.env.API_KEY);
const searchString = "javascript developer"; // what we want to search
const params = {
engine: "google_jobs", // search engine
q: searchString, // search query
hl: "en", // Parameter defines the language to use for the Google search
uule: "w+CAIQICIKY2FsaWZvcm5pYQ", // encoded location
};
const getJson = () => {
return new Promise((resolve) => {
search.json(params, resolve);
});
};
const getResults = async () => {
const organicResults = [];
while (true) {
const json = await getJson();
if (json.search_information?.jobs_results_state === "Fully empty") break;
organicResults.push(...json.jobs_results);
params.start ? (params.start += 10) : (params.start = 10);
}
return organicResults;
};
getResults().then((result) => console.dir(result, { depth: null }));
Code explanation
First, we need to declare SerpApi from google-search-results-nodejs library and define new search instance with your API key from SerpApi:
const SerpApi = require("google-search-results-nodejs");
const search = new SerpApi.GoogleSearch(API_KEY);
Next, we write a search query and the necessary parameters for making a request:
📌Note: the uule parameter is an encoded location parameter. You can make it using UULE Generator for Google.
const searchString = "javascript developer"; // what we want to search
const params = {
engine: "google_jobs", // search engine
q: searchString, // search query
hl: "en", // Parameter defines the language to use for the Google search
uule: "w+CAIQICIKY2FsaWZvcm5pYQ", // encoded location
};
Next, we wrap the search method from the SerpApi library in a promise to further work with the search results:
const getJson = () => {
return new Promise((resolve) => {
search.json(params, resolve);
});
};
And finally, we declare the function getResult that gets data from the page and return it:
const getResults = async () => {
...
};
In this function first, we declare an array organicResults with results data:
const organicResults = [];
Next, we need to use while loop. In this loop we get json with results, check if results are present on the page (jobs_results_state isn't "Fully empty"), push results to organicResults array, define the start number on the results page, and repeat the loop until results aren't present on the page:
while (true) {
const json = await getJson();
if (json.search_information?.jobs_results_state === "Fully empty") break;
organicResults.push(...json.jobs_results);
params.start ? (params.start += 10) : (params.start = 10);
}
return organicResults;
After, we run the getResults function and print all the received information in the console with the console.dir method, which allows you to use an object with the necessary parameters to change default output options:
getResults().then((result) => console.dir(result, { depth: null }));
Output
[
{
"title": "Python Developer Python-JavaScript and vue.js",
"company_name": "Dice",
"location": "San Francisco, CA",
"via": "via LinkedIn",
"description": "Dice is the leading career destination for tech experts at every stage of their careers. Our client, Mitchell Martin, Inc., is seeking the following. Apply via Dice today!\\n\\nPython Developer Python-JavaScript and vue.js...\\n\\nPosition Type: Contract\\n\\nJob responsibilities:\\n\\nAs a member of the Company Bioinformatics team, you will work closely with other Bioinformatics developers and laboratory staff to provide technical leadership, and develop & deploy workflows for our laboratory LIMS that enable automated high throughput workflows for our DNA sequencing laboratories.\\n• Develop and deploy software that manages the operational activities in our specialty genetics laboratories\\n• Ensure availability, performance, and scalability of workflows\\n• Work closely with product owners, software engineers and R&D scientists to gather and implement requirements\\n• Build and maintain code that interacts with a 3rd party vendor application\\n• Guide and mentors other engineers and project team members\\n\\nRequired Skills and Qualifications 5+ years of experience Python, JavaScript and vue.js\\n• Proficient in Python, JavaScript and Vue.js Experience in using version control tools, e.g., Gitlab\\n• B.S. in Bioengineering, Computer Science, MS/PhD preferred\\n• 3+ years of experience working in a regulated industrial life sciences environment or equivalent\\n• 5+ years of experience Python, JavaScript and vue.js\\n• Experienced in using version control tools, e.g., Gitlab\\n• Familiar with working in a Linux environment\\n• Familiar with writing unit tests\\n• Familiarity with typical laboratory workflows and robotic automation used by DNA sequencing laboratories is a plus\\n• Knowledge of L7 ESP LIMS is a plus\\n• Demonstrated ability to work with vendor APIs (or file-based communication) for integration and development\\n• Experience to develop APIs in MuleSoft is a plus\\n• Experience supporting and maintaining applications that interact with 3rd party Vendor software\\n• Demonstrated ability to work in a team and communicate effectively with laboratory personal and R&D scientists\\n• Proficient in Python, JavaScript and Vue.js Experience in using version control tools, e.g., Gitlab\\n• provided by Dice",
"thumbnail": "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTchgwk0qIvqPnMlAcqO5451PRYsMDccWFDcD5pGeE&s",
"extensions": ["5 days ago", "Contractor"],
"detected_extensions": {
"posted_at": "5 days ago",
"schedule_type": "Contractor"
},
"job_id": "eyJqb2JfdGl0bGUiOiJQeXRob24gRGV2ZWxvcGVyIFB5dGhvbi1KYXZhU2NyaXB0IGFuZCB2dWUuanMiLCJodGlkb2NpZCI6InVvWXpSMGhPWjZvQUFBQUFBQUFBQUE9PSIsInV1bGUiOiJ3K0NBSVFJQ0lLWTJGc2FXWnZjbTVwWVEiLCJobCI6ImVuIiwiZmMiOiJFcUlDQ3VJQlFVRjBWbXhpUVV0V1kyZFRiWGszZWxwcmNHWnBjVmswTVhCUk9EQkVUems1VkVocWJFWmtWRXBFWHpNNVIzSjFVMkZCZVZoU1FVNTFSVmhDTUhZd2NGZFpRVTVvTTFGWWVtUk5WbnBmZDFOTWJUazBVblJqV21OcVlXb3RVMUpFU0VSck5GWnNWV0l6TjA1NE5XMWhiMnQyUmpWd1UxODViR042YVV0QmJsUTVTalJ2YzFWaFMwSlVNM2xHUWpFdGNGcEllVkpzUWpWeVRGQlRSbDl2Y1VsMlh6TlNkaTFIZFZCWU9WVm1SaTFNV0hkMlpTMDJjVGRqWWxaaU16Rk9jakl0YVZvMVJISnhla2hXWkZkT1dGOVdjRkpGZVRCNlkzUlNSMVF6VHpadVFSSVhNelYzVlZrMVlsWkVjbGN4Y1hSelVHdFBkVTF0UVVrYUlrRkVWWGxGUjJSdE5FUlVNaTFxUkdWbmRHbHBObWhZY1VOcmNYQXdOSGhhVmxFIiwiZmN2IjoiMyIsImZjX2lkIjoiZmNfMSIsImFwcGx5X2xpbmsiOnsidGl0bGUiOiIubkZnMmVie2ZvbnQtd2VpZ2h0OjUwMH0uQmk2RGRje2ZvbnQtd2VpZ2h0OjUwMH1BcHBseSBvbiBMaW5rZWRJbiIsImxpbmsiOiJodHRwczovL3d3dy5saW5rZWRpbi5jb20vam9icy92aWV3L3B5dGhvbi1kZXZlbG9wZXItcHl0aG9uLWphdmFzY3JpcHQtYW5kLXZ1ZS1qcy1hdC1kaWNlLTMyNDU2NzQxMTU/dXRtX2NhbXBhaWduPWdvb2dsZV9qb2JzX2FwcGx5XHUwMDI2dXRtX3NvdXJjZT1nb29nbGVfam9ic19hcHBseVx1MDAyNnV0bV9tZWRpdW09b3JnYW5pYyJ9fQ=="
},
{
"title": "Staff JavaScript Developer - 50% REMOTE",
"company_name": "Jobot",
"location": "Los Angeles, CA",
"via": "via KTLA Jobs",
"description": "Growing technology company in Cambridge, MA looking for a sharp Senior JavaScript Developer to join their growing team!\\n\\nThis Jobot Job is hosted by Roxy Kupfert...\\n\\nAre you a fit? Easy Apply now by clicking the Apply button and sending us your resume.\\n\\nSalary $120,000 - $220,000 per year\\n\\nA Bit About Us\\n\\nLocated in Cambridge, MA we are a rapidly growing company in the internet technology space. We are looking for a sharp Senior JavaScript Developer to join our team and hit the ground running!\\n\\nWhy join us?\\n\\nWe offer a comprehensive compensation package including but not limited to\\n• A highly competitive base salary ranging from $120K-$220K + EQUITY + BONUSES!\\n• Full benefits (Medical, Dental, Vision)\\n• 401K with match\\n• Great work/life balance - ability to work partially remote / partially in the office\\n• Opportunity to work alongside other brilliant engineers\\n• Flexible work schedule\\n• Catered lunches\\n• Paid gym membership\\n• Foosball and Ping Pong tables\\nJob Details\\n• Integrating user components on server-side JavaScript\\n• Building performant applications with high availability and low latency\\n• Ensuring security, accessibility, and privacy concerns are handled\\n• Writing maintainable code with extensive test coverage, including load tests\\nMUST HAVE, experience with\\n• Modern JavaScript\\n• React and/or Redux\\n• Developing well-structured, performant web applications with component-based architectures\\nNICE TO HAVE, experience with\\n• Security and data concerns such as privacy, data integrity, etc.\\n• Node.js\\n• Containerization / cloud environments\\n• REST, JSON, API design and micro-services\\n• Common UX patterns, accessibility, and cross-browser, cross-device implementations.\\n• Understanding of algorithms, data structures and design patterns\\n• CI/CD pipelines\\nIf this sounds like you, please apply through the link or email your resume directly to roxy.kupfert@!\\n\\nInterested in hearing more? Easy Apply now by clicking the Apply button",
"extensions": ["4 days ago", "Full-time", "No degree mentioned", "Health insurance", "Dental insurance"],
"detected_extensions": {
"posted_at": "4 days ago",
"schedule_type": "Full-time"
},
"job_id": "eyJqb2JfdGl0bGUiOiJTdGFmZiBKYXZhU2NyaXB0IERldmVsb3BlciAtIDUwJSBSRU1PVEUiLCJodGlkb2NpZCI6InZsVmN0d2s5RklFQUFBQUFBQUFBQUE9PSIsInV1bGUiOiJ3K0NBSVFJQ0lLWTJGc2FXWnZjbTVwWVEiLCJobCI6ImVuIiwiZmMiOiJFb3dDQ3N3QlFVRjBWbXhpUTJoYVYwMUhiWHB6Y1hwYVNrZDRTRzVUZVdaUkxVNUpRWFZvUTJGV01XZFNRMVZ1V0cxcVJETjZjVGMwZURsMVMyaEhZM2x3ZFVSaVRXZDVjREJGVmt4TU9GQklhR050ZFVzNFFtODFTWEJJVDNwcVJGRndkSE5aVGkxVmRuZzVaRU5UU0RaWVJsaEpZVXB4Tm5WTWJURllUbTF2Wm1WMmFGQkxURjlZVTFCeVNISkRUVFZ1TjA1UE9FeHliWFZ2Ym1acmR6TlplblpzVWpJd2NXZExaVzVhY2xrMFVrSlVheTAzZFY5T1ZFcGhSMDh4WjFkSmFWWmtUMkZGYlVaNFVVVkpZblZCRWhjek5YZFZXVFZpVmtSeVZ6RnhkSE5RYTA5MVRXMUJTUm9pUVVSVmVVVkhabDlNZFZSb2RrZ3dRek56Y0ZaSFkxQTFiek5sZW13eE9IUldVUSIsImZjdiI6IjMiLCJmY19pZCI6ImZjXzMiLCJhcHBseV9saW5rIjp7InRpdGxlIjoiQXBwbHkgb24gS1RMQSBKb2JzIiwibGluayI6Imh0dHBzOi8vam9icy5rdGxhLmNvbS9qb2JzL3N0YWZmLWphdmFzY3JpcHQtZGV2ZWxvcGVyLTUwLXJlbW90ZS1sb3MtYW5nZWxlcy1jYWxpZm9ybmlhLzY5OTIyMTQ2My0yLz91dG1fY2FtcGFpZ249Z29vZ2xlX2pvYnNfYXBwbHlcdTAwMjZ1dG1fc291cmNlPWdvb2dsZV9qb2JzX2FwcGx5XHUwMDI2dXRtX21lZGl1bT1vcmdhbmljIn19"
}
]
Links
If you want to see some projects made with SerpApi, please write me a message.
Add a Feature Request💫 or a Bug🐞

Top comments (0)