
Git has a lot to offer, sometimes is overwhelming, for that reason it's good to have a practical approach and explanations along the way to grasp the essentials of this magnificent tool.
This is the first part of a series of articles to introduce you to Git and then to level up your working development workflow using git.
Content.
- Git history (brief).
- Git workflow.
- Hands-on Git.
Git history (brief)
git - the stupid content tracker —man page
The problem
A software is a piece of code that grows, in every new feature added a tag is placed in it and you get new versions. Eventually, the owner needs to share that code and allow contributions from other people to make that software better (or worst...). How to achieve this? for the first part, the answer is: Version Control System (VCS) to track the changes. For the second part we have two possible answers:
- having a centralized system that keeps track of all the changes in your code.
- having a distributed system where all the code is shared among contributors that work merging changes.
So, what Git is? is a Distributed Version Control System
Brief History
In April 2005, Linus Torvalds was working on the 2.6.12 version of his Linux operating system, not pleased with the current VCS available in the market to help him manage his code (BitKeeper as the main one), he decided that he needed to create it's own to keep track of changes of the Linux core. This system had to be:
- Distributed
- Fast
- Reliable
And... he did it. Git was created. Since then it has been growing almost universally to manage version control and team contributions.
For the sake of brevity, these are the main things to know.
Git, workflow
So, how does git works? There are key concepts surrounding Git.
Our files live in three areas or states, those are:
- Untracked or modified.
- Staging area.
- Committed.
Whenever we want to commit our changes on certain files we add those files to the staging area and then commit them. Once committed all your changes are saved in the Git history, so whatever you do you can come back to that point later if you need it.
Scenario:
- You are starting working in a project and you want to keep track of changes in your code, so what you do is creating a local repository and add your code to that repository. (git init).
- The second thing you want is to select the files that you want to keep track of and add them to the staging area for committing them later. (git add [file, ])
- Finally, after adding all the file that you changed you need to commit your work to create a commit in your Git history. (git commit -m "Initial commit").
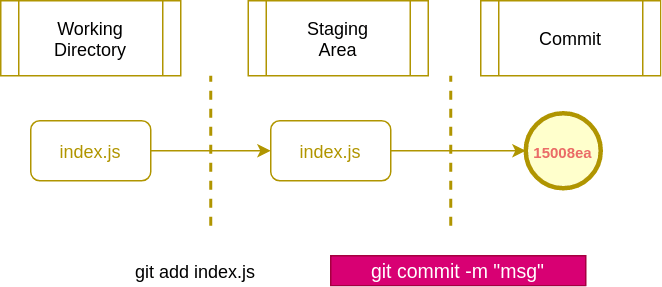
Up to this point, there is only one commit in Git history. This history is saved in the form of a tree, in this case, there is only one node. This node is the starting point of a mainline of development (branch) that is being tracked by default, that is called the "master branch".
Hands-on Git
Initial configuration
Open a terminal.
Install git first.
$ sudo apt install git-all
Let us tell git who we are so our signature is in all our commits.
$ git config --global user.name "Your Name"
$ git config --global user.email "youremail@yourdomain.com"
Great! now the basics.
Basics
Create a local repository
In a project create a Git repository using git init.
$ mkdir awesome-project && cd awesome-project
$ git init
Initialized empty Git repository in /home/user/awesome-project/.git/
Congratulations! you have created your first repository. You can actually see it... in the .git folder. If by any reason you want to get rid of it you just have to delete that folder (rm -rf .git).
$ ls -a
. .. .git
At this point there is nothing in your history, you can check it out with git status.
$ git status
On branch master
No commits yet
nothing to commit (create/copy files and use "git add" to track)
As you can see you are in the master branch. Let us create two files, put something on them and then make our first commit:
$ echo "console.log('hello')" > hello.js
$ echo "console.log('hello')" > world.js
$ cat hello.js
console.log('hello')
If we check the status again we will see that our files are not being tracked yet.
$ git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
hello.js
world.js
nothing added to commit but untracked files present (use "git add" to track)
Staging your files
Git is telling us is not tracking those files. Let us add only one of them to the staging area and check the status once more.
$ git add hello.js
$ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: hello.js
Untracked files:
(use "git add <file>..." to include in what will be committed)
world.js
Perfect, not we are ready for committing index.js to the Git history.
Commiting
As you can see now hello.js is in the staging area about to be committed and world.js is being untracked. Now, let us commit the hello.js file and add it to the git history.
$ git commit -m "Initial commit, add hello.js"
[master (root-commit) 15008ea] Initial commit, add hello.js
1 file changed, 1 insertion(+)
create mode 100644 hello.js
$ git status
On branch master
Untracked files:
(use "git add <file>..." to include in what will be committed)
world.js
nothing added to commit but untracked files present (use "git add" to track)
Congratulations, your first commit! The -m option is short for --message= to add a message while committing.
As you can see the file hello.js is not seen anymore when running git status, this is because has already been committed. We can check the Git history using git log.
$ git log
commit 15008ea3f281f95a4b3649e7383eb0334565b415 (HEAD -> master)
Author: sespinoza <espinoza.jimenez@gmail.com>
Date: Tue Aug 4 21:22:07 2020 -0400
Initial commit, add hello.js
And there it is, our commit. Here you see plenty of information related to that commit: Hash, Author, Date of commit and the Git message. The hash is an identifier of a commit and with it, you can come back to that state of your code whenever you need to, using the HEAD pointer.
HEAD pointer
To explain what (HEAD -> master) means you have to understand how git saves history. It uses a tree structure, where every commit is a node. Let us add another commit and check how our history would look like.
$ echo "console.log('la la la')" >> hello.js
$ cat hello.js
console.log('hello')
console.log('la la la')
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: hello.js
Untracked files:
(use "git add <file>..." to include in what will be committed)
world.js
no changes added to commit (use "git add" and/or "git commit -a")
$ git add hello.js
$ git commit -m "[Update] index.js add another console log"
[master f99f2fe] [Update] index.js add another console log
1 file changed, 1 insertion(+)
$ git log
commit f99f2fe2a3a4c783c6658a591cf69903666bca17 (HEAD -> master)
Author: sespinoza <espinoza.jimenez@gmail.com>
Date: Tue Aug 4 22:02:37 2020 -0400
[Update] index.js add another console log
commit 15008ea3f281f95a4b3649e7383eb0334565b415
Author: sespinoza <espinoza.jimenez@gmail.com>
Date: Tue Aug 4 21:22:07 2020 -0400
Initial commit, add hello.js
Here we have two commits already, and our tree looks like the following diagram.
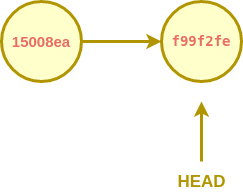
Here
HEAD is an alias for the tip of the current branch
And you can see where is pointing using git branch.
$ git branch
* master
Here HEAD is pointing to the master branch. Also, you can see what HEAD actually looks like:
$ cat .git/HEAD
ref: refs/heads/master
To show you a little how it works, we can go back in time in the Git history and see our first commit by passing the hash of the commit to the checkout option.
(master)$ git checkout 15008ea3f281f95a4b3649e7383eb0334565b415
Note: checking out '15008ea3f281f95a4b3649e7383eb0334565b415'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by performing another checkout.
If you want to create a new branch to retain commits you to create, you may
do so (now or later) by using -b with the checkout command again. Example:
git checkout -b <new-branch-name>
HEAD is now at 15008ea Initial commit, add hello.js
((HEAD detached at 15008ea))$ cat hello.js
console.log('hello')
The checkout command helps us to navigate through commits. We now see that HEAD is pointing to the first commit, so now our file only has the first change that we did, that is console.log('hello').

We can come back to the latest state by referring to the branch.
$ git checkout master
Previous HEAD position was 15008ea Initial commit, add hello.js
Switched to branch 'master'
To end this article we'll see how to undo the last commit keeping the changes in our working directory and also the option of removing the commit and the changes from our working directory.
Undo the last commit --soft
If you want to remove the last commit but keep those changes in your working directory use:
$ git reset --soft HEAD^1
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: hello.js
Untracked files:
(use "git add <file>..." to include in what will be committed)
world.js
As you can see your files of the last commit are now in your staging area, you can edit your file now and commit again later. Here HEAD^1 makes a reference to the immediate "parent" of the current commit. The current commit is the last commit, so here we are telling git "go and reset everything until the previous commit".
Undo the last commit --hard
If you want to get rid of the last commit and all the changes introduced in the last commit.
$ git reset --hard HEAD^1
HEAD is now at 15008ea Initial commit, add hello.js
$ git status
On branch master
Untracked files:
(use "git add <file>..." to include in what will be committed)
world.js
nothing added to commit but untracked files present (use "git add" to track)
$ cat hello.js
console.log('hello')
Using --hard removes the las commit and it's changes and place HEAD pointing to the first commit.
That's it for this Article, in the next one I'll talk about how to make better Git commit messages, the workflow for a single developer and more. I hope this helped you understanding and using git better.
References
About me
I’m a Software Engineer, writer, tech enthusiast, pianist, origami lover, amateur photographer. In my spare time, I go trekking, play the piano and learn history.
My tech: JavaScript, Node.js, React, Ruby, Crystal, Bash, Docker.
You can follow me on Twitter, LinkedIn or visit my page to contact me.
Originally posted in: sespinoza.me

Top comments (3)
Good. I use everyday git (Gitlab) for my work, but i never use in console. I'll try to use console because with console you understand more the commands. I like software like fork, gitkraken, eclipse o visual studio code to help me.
Greetings!
I'm glad this was helpful to you! During this week I'll write more in deep features that are super helpful to my daily work, like checking the changes from one commit to another, listing the files that changed, using tags and more.
A college of mine also use those tools, they are great! it's good to know how to surf in the terminal when things get more complex though.
Cheers!
That's great. I thinks when you work with other programmers, the main activities that you do are:
commit,push,pull,merge request,blame,diff,stash. I hope you could talk about this.Regards