
Continuing with the Kubernetes: monitoring with Prometheus — exporters, a Service Discovery, and its roles, where we configured Prometheus manually to see how it’s working — now, let’s try to use Prometheus Operator installed via Helm chart.
So, the task is to spin up a Prometheus server and all necessary exporter in an AWS Elastic Kubernetes Cluster and then via /federation pass metrics to our "central" Prometheus server with Alertmanager alerts and Grafana dashboards.
A bit confusing is the whole set of such Helm charts — there is a “simple” Prometheus chart, and kube-prometheus, and prometheus-operator:
- Bitnami Prometheus Operator — https://github.com/bitnami/charts/tree/master/bitnami/prometheus-operator/
- CoreOS Prometheus Operator — https://github.com/coreos/prometheus-operator
- Helm Community Prometheus Operator — https://github.com/helm/charts/tree/master/stable/prometheus-operator
- CoreOS kube-prometheus - https://github.com/coreos/kube-prometheus
- And “just a Prometheus” — https://github.com/helm/charts/tree/master/stable/prometheus
Although if look for it via helm search — it returns the only one prometheus-operator:
$ helm search repo stable/prometheus-operator -o yaml
- app_version: 0.38.1
description: Provides easy monitoring definitions for Kubernetes services, and deployment
and management of Prometheus instances.
name: stable/prometheus-operator
version: 8.14.0
The difference between the stable/prometheus and stable/prometheus-operator is that Operator has built-in Grafana with a set of ready for use dashboards and set of ServiceMonitors to collect metrics from a cluster's services such as the CoreDNS, API Server, Scheduler, etc.
So, as mentioned — we will use the stable/prometheus-operator.
Prometheus Operator deployment
Deploy it with Helm:
$ helm install — namespace monitoring — create-namespace prometheus stable/prometheus-operator
manifest\_sorter.go:192: info: skipping unknown hook: “crd-install”
manifest\_sorter.go:192: info: skipping unknown hook: “crd-install”
manifest\_sorter.go:192: info: skipping unknown hook: “crd-install”
manifest\_sorter.go:192: info: skipping unknown hook: “crd-install”
manifest\_sorter.go:192: info: skipping unknown hook: “crd-install”
manifest\_sorter.go:192: info: skipping unknown hook: “crd-install”
NAME: prometheus
LAST DEPLOYED: Mon Jun 15 17:54:27 2020
NAMESPACE: monitoring
STATUS: deployed
REVISION: 1
NOTES:
The Prometheus Operator has been installed. Check its status by running:
kubectl — namespace monitoring get pods -l “release=prometheus”
Visit [https://github.com/coreos/prometheus-operator](https://github.com/coreos/prometheus-operator) for instructions on how to create & configure Alertmanager and Prometheus instances using the Operator.
Check pods:
$ kk -n monitoring get pod
NAME READY STATUS RESTARTS AGE
alertmanager-prometheus-prometheus-oper-alertmanager-0 2/2 Running 0 41s
prometheus-grafana-85c9fbc85c-ll58c 2/2 Running 0 46s
prometheus-kube-state-metrics-66d969ff69–6b7t8 1/1 Running 0 46s
prometheus-prometheus-node-exporter-89mf4 1/1 Running 0 46s
prometheus-prometheus-node-exporter-bpn67 1/1 Running 0 46s
prometheus-prometheus-node-exporter-l9wjm 1/1 Running 0 46s
prometheus-prometheus-node-exporter-zk4cm 1/1 Running 0 46s
prometheus-prometheus-oper-operator-7d5f8ff449-fl6x4 2/2 Running 0 46s
prometheus-prometheus-prometheus-oper-prometheus-0 3/3 Running 1 31
Note: alias kk="kubectl" >> ~/.bashrc
So, the Prometheus Operator’s Helm chart created a whole bunch of services — Prometheus itself, Alertmanager, Grafana, plus a set of ServiceMonitors:
$ kk -n monitoring get servicemonitor
NAME AGE
prometheus-prometheus-oper-alertmanager 3m53s
prometheus-prometheus-oper-apiserver 3m53s
prometheus-prometheus-oper-coredns 3m53s
prometheus-prometheus-oper-grafana 3m53s
prometheus-prometheus-oper-kube-controller-manager 3m53s
prometheus-prometheus-oper-kube-etcd 3m53s
prometheus-prometheus-oper-kube-proxy 3m53s
prometheus-prometheus-oper-kube-scheduler 3m53s
prometheus-prometheus-oper-kube-state-metrics 3m53s
prometheus-prometheus-oper-kubelet 3m53s
prometheus-prometheus-oper-node-exporter 3m53s
prometheus-prometheus-oper-operator 3m53s
prometheus-prometheus-oper-prometheus 3m53s
The ServiceMonitors role will be reviewed in this post later in the Adding Kubernetes ServiceMonitor part.
Grafana access
Let’s go to see which dashboards are shipped with Grafana.
Find Grafana’s pod:
$ kk -n monitoring get pod
NAME READY STATUS RESTARTS AGE
alertmanager-prometheus-prometheus-oper-alertmanager-0 2/2 Running 0 103s
prometheus-grafana-85c9fbc85c-wl856 2/2 Running 0 107s
…
Run port-forward:
$ kk -n monitoring port-forward prometheus-grafana-85c9fbc85c-wl856 3000:3000
Forwarding from 127.0.0.1:3000 -> 3000
Forwarding from [::1]:3000 -> 3000
Open localhost:3000, log in with the admin username and prom-operator password and you’ll see a lot of ready for user graphs:

At the time of writing Prometheus Operator is shipped with Grafana version 7.0.3.
Actually, we don’t need Grafana and Alertmanager here, as they are used on our “central” monitoring server, so let’s remove them from here.
Prometheus Operator configuration
Prometheus Operator uses Custom Resource Definitions which describes all its components:
$ kk -n monitoring get crd
NAME CREATED AT
alertmanagers.monitoring.coreos.com 2020–06–15T14:47:44Z
eniconfigs.crd.k8s.amazonaws.com 2020–04–10T07:21:20Z
podmonitors.monitoring.coreos.com 2020–06–15T14:47:45Z
prometheuses.monitoring.coreos.com 2020–06–15T14:47:46Z
prometheusrules.monitoring.coreos.com 2020–06–15T14:47:47Z
servicemonitors.monitoring.coreos.com 2020–06–15T14:47:47Z
thanosrulers.monitoring.coreos.com 2020–06–15T14:47:48Z
For example, the prometheuses.monitoring.coreos.com CRD describes a Custom Resource named Prometheus:
$ kk -n monitoring get crd prometheuses.monitoring.coreos.com -o yaml
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
…
spec:
…
names:
kind: Prometheus
listKind: PrometheusList
plural: prometheuses
singular: prometheus
…
And then you can use this name as a common Kubernetes object like pods, nodes, volumes, etc by using its name from the names field:
$ kk -n monitoring get prometheus -o yaml
apiVersion: v1
items:
- apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
annotations:
meta.helm.sh/release-name: prometheus
meta.helm.sh/release-namespace: monitoring
…
spec:
alerting:
alertmanagers:
- apiVersion: v2
name: prometheus-prometheus-oper-alertmanager
namespace: monitoring
pathPrefix: /
port: web
baseImage: quay.io/prometheus/prometheus
enableAdminAPI: false
externalUrl: [http://prometheus-prometheus-oper-prometheus.monitoring:9090](http://prometheus-prometheus-oper-prometheus.monitoring:9090)
listenLocal: false
logFormat: logfmt
logLevel: info
paused: false
podMonitorNamespaceSelector: {}
podMonitorSelector:
matchLabels:
release: prometheus
portName: web
replicas: 1
retention: 10d
routePrefix: /
ruleNamespaceSelector: {}
ruleSelector:
matchLabels:
app: prometheus-operator
release: prometheus
securityContext:
fsGroup: 2000
runAsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: prometheus-prometheus-oper-prometheus
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector:
matchLabels:
release: prometheus
version: v2.18.1
…
For now, we are interested in the serviceMonitorSelector record:
...
serviceMonitorSelector:
matchLabels:
release: prometheus
Which defines which ServiceMonitors will be added under the observation of the Prometheus server in the cluster.
Adding a new application under monitoring
Now, let’s try to add an additional service under monitoring:
- spin up a Redis server
- and
redis_exporter - will add ServiceMonitor
- and eventually, we will configure Prometheus Operator to use the ServiceMonitor to collect metrics from the
redis_exporter
Redis server launch
Create a namespace to make this setup more realistic, when a monitored application is located in one namespace, while monitorings services are living in an another:
$ kk create ns redis-test
namespace/redis-test created
Run Redis:
$ kk -n redis-test run redis — image=redis
deployment.apps/redis created
Create a Service object for Redis network communication:
$ kk -n redis-test expose deploy redis — type=ClusterIP — name redis-svc — port 6379
service/redis-svc exposed
Check it:
$ kk -n redis-test get svc redis-svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
redis-svc ClusterIP 172.20.237.116 <none> 6379/TCP 25s
Okay — our Redis is working, now let’s add its Prometheus exporter.
The redis_exporter launch
Install it with Helm:
$ helm install -n monitoring redis-exporter — set “redisAddress=redis://redis-svc.redis-test.svc.cluster.local:6379” stable/prometheus-redis-exporter
Check its Service:
$ kk -n monitoring get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 89m
…
redis-exporter-prometheus-redis-exporter ClusterIP 172.20.239.67 <none> 9121/TCP 84s
And its endpoint:
$ kk -n monitoring get endpoints redis-exporter-prometheus-redis-exporter -o yaml
apiVersion: v1
kind: Endpoints
metadata:
…
labels:
app: prometheus-redis-exporter
app.kubernetes.io/managed-by: Helm
chart: prometheus-redis-exporter-3.4.1
heritage: Helm
release: redis-exporter
name: redis-exporter-prometheus-redis-exporter
namespace: monitoring
…
ports:
- name: redis-exporter
port: 9121
protocol: TCP
Go to check metrics — spin up a new pod, for example with Debian, and install curl:
$ kk -n monitoring run — rm -ti debug — image=debian — restart=Never bash
If you don’t see a command prompt, try pressing enter.
root@debug:/# apt update && apt -y install curl
And make a request to the redis_exporter:
root@debug:/# curl redis-exporter-prometheus-redis-exporter:9121/metrics
…
HELP redis\_up Information about the Redis instance
TYPE redis\_up gauge
redis\_up 1
HELP redis\_uptime\_in\_seconds uptime\_in\_seconds metric
TYPE redis\_uptime\_in\_seconds gauge
redis\_uptime\_in\_seconds 2793
Or without an additional port — just by running port-forward to the redis-svc:
$ kk -n monitoring port-forward svc/redis-exporter-prometheus-redis-exporter 9121:9121
Forwarding from 127.0.0.1:9121 -> 9121
Forwarding from [::1]:9121 -> 9121
And run from your local PC:
$ curl localhost:9121/metrics
…
redis\_up 1
HELP redis\_uptime\_in\_seconds uptime\_in\_seconds metric
TYPE redis\_uptime\_in\_seconds gauge
redis\_uptime\_in\_seconds 8818
Okay — we’ve got our Redis Server application and its Prometheus exporter with metrics available via the /metrics URI and 9121 port.
The next thing is t configure Prometheus Operator to collect those metrics to its database so later they are pulled by the “central” monitoring via the Prometheus federation.
Adding Kubernetes ServiceMonitor
Check our redis_exporter's labels:
$ kk -n monitoring get deploy redis-exporter-prometheus-redis-exporter -o yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
…
generation: 1
labels:
app: prometheus-redis-exporter
app.kubernetes.io/managed-by: Helm
chart: prometheus-redis-exporter-3.4.1
heritage: Helm
release: redis-exporter
…
And check serviceMonitorSelector's Selector of the prometheus resource created above:
$ kk -n monitoring get prometheus -o yaml
At the end of output find the following lines:
...
serviceMonitorSelector:
matchLabels:
release: prometheus
So, Prometheus will look for ServiceMonitors with the release tag with the prometheus value.
Create an additional ServiceMonitor:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
serviceapp: redis-servicemonitor
release: prometheus
name: redis-servicemonitor
namespace: monitoring
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 15s
port: redis-exporter
namespaceSelector:
matchNames:
- monitoring
selector:
matchLabels:
release: redis-exporter
In its labels we've set the release: prometheus so Prometheus can find it, and in the selector.matchLabels - specified to look for any Service tagged as release: redis-exporter.
Apply it:
$ kk -n monitoring apply -f redis-service-monitor.yaml
servicemonitor.monitoring.coreos.com/redis-servicemonitor created
Check Prometheus’ Targets:

Redis Server metrics:

Great — “It works!” ©
What is next?
And the next thing to do is to remove Alertmanager and Grafana from our Prometheus Operator stack.
Prometheus Operator Helm deployment and its services configuration
Actually, why need to remove Grafana? It has really useful dashboards ready, so let’s leave it there.
The better way seems to be:
- on each EKS we will have Prometheus Operator with Grafana but without Alertmanager
- on cluster’s local Prometheus servers let’s leave the default retention period to store metrics set to 2 weeks
- will remove the Alertmanager from there — will use our “central” monitoring’s Alertmanager with already defined routs and alerts (see the Prometheus: Alertmanager’s alerts receivers and routing based on severity level and tags post for details about routing)
- and on the central monitoring server — we will keep our metrics for one year and will have some Grafana dashboards there
So, we need to add two LoadBalacners — one with the internet-facing type for the Grafana service and another one — internal — for the Prometheus, because it will communicate with our central monitoring host via AWS VPC Peering.
And later well need to add this to our automation — AWS Elastic Kubernetes Service: a cluster creation automation, part 2 — Ansible, eksctl.
But for now, let’s do it manually.
Well, what do we need to change in Prometheus Operator’s default deployment?
- drop Alertmanager
- add settings for:
- Prometheus and Grafana — they must be deployed behind an AWS LoadBalancer
- set a login:pass for Grafana
All available options can be found in the documentation — https://github.com/helm/charts/tree/master/stable/prometheus-operator.
At his moment, let’s start with removing Alertmanager.
To do so need to pass the alertmanager.enabled parameter.
Check its pod now:
$ kk -n monitoring get pod
NAME READY STATUS RESTARTS AGE
alertmanager-prometheus-prometheus-oper-alertmanager-0 2/2 Running 0 24h
…
Redeploy it and via the --set specify the alertmanager.enabled=false:
$ helm upgrade — install — namespace monitoring — create-namespace prometheus stable/prometheus-operator — set “alertmanager.enabled=false”
Check pods again — no Alertmanager must be present now in the stack.
An AWS LoadBalancer configuration
To make our Grafana available externally from the Internet we need to add an Ingress resource for Grafana and a dedicated Ingress for the Prometheus.
What do we have in the documentation:
-
grafana.ingress.enabledEnables Ingress for Grafana false -grafana.ingress.hostsIngress accepted hostnames for Grafana []
Add the Ingress for Grafana:
$ helm upgrade — install — namespace monitoring — create-namespace prometheus stable/prometheus-operator — set “alertmanager.enabled=false” — set grafana.ingress.enabled=true
…
Error: UPGRADE FAILED: failed to create resource: Ingress.extensions “prometheus-grafana” is invalid: spec: Invalid value: []networking.IngressRule(nil): either `backend` or `rules` must be specified
Er…
The documentation says nothing about LoadBalancers configuration, but I googled some in the Jupyter’s docs here.
Let’s try it - now via the values.yaml file to avoid a bunch of --set.
Add the hosts to the file:
grafana:
ingress:
enabled: true
annotations:
kubernetes.io/ingress.class: "alb"
alb.ingress.kubernetes.io/scheme: "internet-facing"
hosts:
- "dev-0.eks.monitor.example.com"
Deploy:
$ helm upgrade — install — namespace monitoring — create-namespace prometheus stable/prometheus-operator -f oper.yaml
Check the Kubernetes ALB Controller logs:
I0617 11:37:48.272749 1 tags.go:43] monitoring/prometheus-grafana: modifying tags { ingress.k8s.aws/cluster: “bttrm-eks-dev-0”, ingress.k8s.aws/stack: “monitoring/prometheus-grafana”, kubernetes.io/service-name: “prometheus-grafa
na”, kubernetes.io/service-port: “80”, ingress.k8s.aws/resource: “monitoring/prometheus-grafana-prometheus-grafana:80”, kubernetes.io/cluster/bttrm-eks-dev-0: “owned”, kubernetes.io/namespace: “monitoring”, kubernetes.io/ingress-name
: “prometheus-grafana”} on arn:aws:elasticloadbalancing:us-east-2:534***385:targetgroup/96759da8-e0b8253ac04c7ceacd7/35de144cca011059
E0617 11:37:48.310083 1 controller.go:217] kubebuilder/controller “msg”=”Reconciler error” “error”=”failed to reconcile targetGroups due to failed to reconcile targetGroup targets due to prometheus-grafana service is not of type NodePort or LoadBalancer and target-type is instance ” “controller”=”alb-ingress-controller” “request”={“Namespace”:”monitoring”,”Name”:”prometheus-grafana”}
Okay — add the /target-type: "ip" so AWS ALB will send traffic directly to the Grafana's pod instead of WorkerNodes port and let's add valid HTTP codes:
grafana:
ingress:
enabled: true
annotations:
kubernetes.io/ingress.class: "alb"
alb.ingress.kubernetes.io/scheme: "internet-facing"
alb.ingress.kubernetes.io/target-type: "ip"
alb.ingress.kubernetes.io/success-codes: 200,302
hosts:
- "dev-0.eks.monitor.example.com"
Or another way — reconfigure the Grafana’s Service to use the NodePort:
grafana:
service:
type: NodePort
port: 80
annotations: {}
labels: {}
ingress:
enabled: true
annotations:
kubernetes.io/ingress.class: "alb"
alb.ingress.kubernetes.io/scheme: "internet-facing"
alb.ingress.kubernetes.io/success-codes: 200,302
hosts:
- "dev-0.eks.monitor.example.com"
Redeploy Operator’s stack:
$ helm upgrade — install — namespace monitoring — create-namespace prometheus stable/prometheus-operator -f oper.yaml
Wait for a minute and check AWS LoadBalancer again:
$ kk -n monitoring get ingress
NAME HOSTS ADDRESS PORTS AGE
prometheus-grafana dev-0.eks.monitor.example.com 96759da8-monitoring-promet-\*\*\*.us-east-2.elb.amazonaws.com 80 30m
But now dev-0.eks.monitor.example.com will return the 404 code from our LoadBalancer:
$ curl -vL dev-0.eks.monitor.example.com
\* Trying 3.\*\*\*.\*\*\*.247:80…
\* Connected to dev-0.eks.monitor.example.com (3.\*\*\*.\*\*\*.247) port 80 (#0)
> GET / HTTP/1.1
> Host: dev-0.eks.monitor.example.com
> User-Agent: curl/7.70.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 302 Found
…
< Location: /login
…
* Connection #0 to host dev-0.eks.monitor.example.com left intact
* Issue another request to this URL: ‘http://dev-0.eks.monitor.example.com/login'
…
> GET /login HTTP/1.1
…
< HTTP/1.1 404 Not Found
< Server: awselb/2.0
Why does this happen?
- the ALB accepts a request to the dev-0.eks.monitor.example.com URL and redirects it to the WorkerNodes TargetGroup with Grafana’s pod(s)
- Grafana returns the 302 redirect code to the
/loginURI - the request is going back to the ALB but at this time with the
/loginURI
Check the ALB’s Listener rules:

Well, here it is — we will return 404 code for any URI requests excepting the /. Accordingly, the /login request also will be dropped with the 404.
I’d like to see any comments from developers, who set this as the default behavior for the path.
Go back to our values.yaml, replace the path from the / to the /*.
And update the hosts field to avoid the "Invalid value: []networking.IngressRule(nil): either backend or rules must be specified" error.
To not tie yourself to any specific domain name - you can set it to the "" value:
grafana:
ingress:
enabled: true
annotations:
kubernetes.io/ingress.class: "alb"
alb.ingress.kubernetes.io/target-type: "ip"
alb.ingress.kubernetes.io/scheme: "internet-facing"
alb.ingress.kubernetes.io/success-codes: 200,302
hosts:
- ""
path: /*
Redeploy, check:
$ kk -n monitoring get ingress
NAME HOSTS ADDRESS PORTS AGE
prometheus-grafana * 96759da8-monitoring-promet-bb6c-2076436438.us-east-2.elb.amazonaws.com 80 15m
Open in a browser:

Great!
And even more — now we are able to see all graphs in the Lens utility used by our developers — earlier they got the “ Metrics are not available due to missing or invalid Prometheus configuration ” и “ Metrics not available at the moment ” error messages:
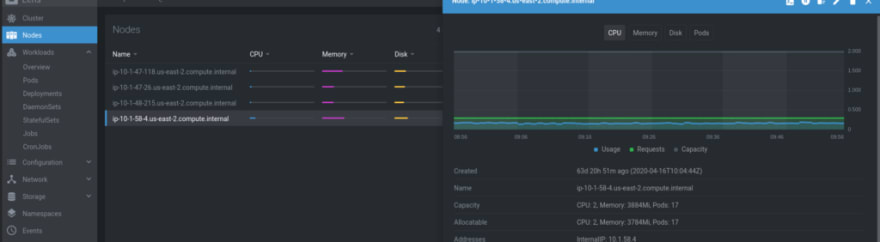
Actually, that’s all to start using Prometheus Operator to monitor Your Kubernetes cluster
Useful links
- Kubernetes monitoring with Prometheus — Prometheus operator tutorial
- Prometheus Operator — Installing Prometheus Monitoring Within The Kubernetes Environment
- Quick Start with Prometheus Monitoring
- Prometheus Operator — How to monitor an external service
- How to Set Up DigitalOcean Kubernetes Cluster Monitoring with Helm and Prometheus Operator
- Configuring prometheus-operator helm chart with AWS EKS
- Zero to JupyterHub with Kubernetes
- Howto expose prometheus, grafana and alertmanager with nginx ingress
- Howto expose prometheus, grafana and alertmanager with nginx ingressEKS: failed to reconcile targetGroups due to failed to load serviceAnnotation due to no object matching key
Originally published at RTFM: Linux, DevOps, and system administration.

Top comments (1)
it is not working in helm3