
When building machine learning (ML) models for highly complex automation tasks it is not only essential to identify the right models for the right job but also to select the suitable datasets for training, testing and validation. While dataset selection is typically easier for ML problems based on structured data, there are massive challenges to use data-driven technologies with unstructured data. Typical examples of such applications are robotics, automated driving and computer vision. While the content of structured data can be easily accessed and queried, dealing with unstructured data typically requires immense amounts of manual work for data selection, annotation and dataset balancing. Even tasks that seem simple, like better understanding the content of whole datasets, become extremely challenging as the typical information depth is very low as little to no additional knowledge about the content and context of the underlying unstructured data is present.
Data selection is a crucial factor for all data-driven applications. It is of great importance to ensure that no biases are introduced by the data, to avoid correlation between the training and test data, and to cover the whole spectrum of possible input data as models are typically bad at extrapolating. This requires deep insights into the data which are typically hard to get, especially on a large scale (several 1000s of hours of recordings). Handling the data becomes tricky and manual labor cannot provide the necessary insights at this scale.
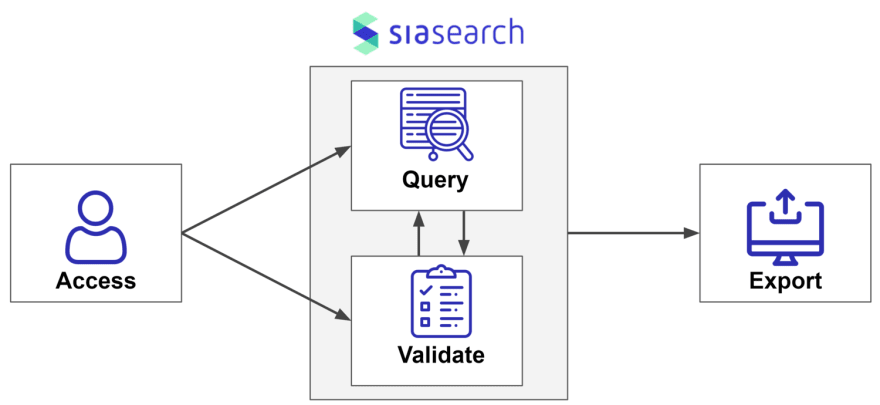
With SiaSearch we provide the tools that enable users to identify the desired data within seconds. As a large amount of content information and metadata is automatically extracted during data ingestion, the data is easily searchable for the end user -- even on a petabyte scale of data.
Using the SiaSearch API to balance datasets
In order to illustrate how to work with the SiaSearch API and SDK, we will walk you through the simple process of identifying data for model training and testing, for example. Let’s assume for now that the AV engineers identified problems in the object detection module while conducting lane changes. Therefore they want to improve their models to address the problem and investigate if new data can be added to the existing training and test sets. In this case, SiaSearch can be used to crawl through previously unlabeled data and identify additional lane changes.
We will illustrate the following functionalities in this post:
- Querying the large underlying dataset for specific situations
- Conducting a visual sanity check of the data
- Generating subsets of data and comparing the underlying data content
- Exporting data to a common format
In the following we’ll provide a few steps on how to work with our API and the Python SDK. Please note that only an excerpt of the functionalities can be shown in this post. If you are interested in obtaining full access to SiaSearch and its API, please reach out to us at hi@siasearch.com or request a demo here.
Authenticate with the API
The first step is to use the login credentials to log into SiaSearch.
>>> from siasearch import auth
>>> sia = auth(username='foo', password='bar', "https://some-endpoint.com")
>>> sia
Siasearch object with user `foo` connected to `https://some-endpoint.com
Querying for desired data
Queries can be constructed with an SQL-like DSL (domain specific language). For our simple example where we want to find lane changes in our own “mxa” dataset, the query looks like this:
>>> results = sia.query("dataset_name = 'mxa' AND is_lane_change = 'True'")
>>> len(results.segments)
56
The API returns a results object which consists of segments that match the query attributes. Those segments are defined by the dataset, the underlying drive IDs and the start and end time of each segment and have various methods relating to how a user can interact with a segment.
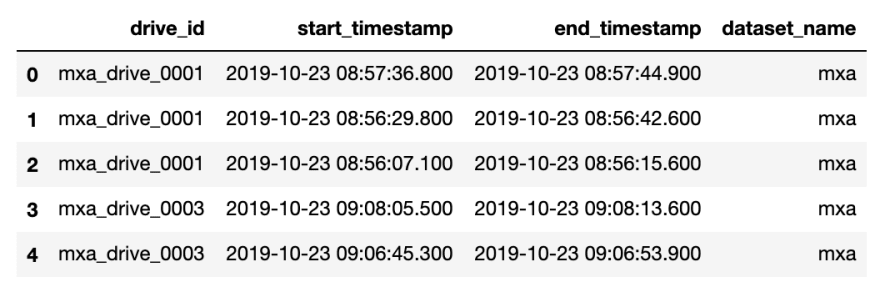
The results can also be obtained as a Pandas DataFrame.
>>> results.df_segments.head()
Validation of results
It's critical to validate the query results. The query we previously constructed may have been too narrow, or vague. In either case, we can iterate and tweak the query until we are satisfied with the resulting set of events.
The easiest way to visually inspect the query results is by accessing them in the SiaSearch web interface. Giving you an overview of all segments, and allowing you to inspect a single segment in more detail.
This can be achieved with the following command:
>>> results.url()
https://demo.sia-search.com/search?query=dataset_name+=+%27mxa%27+AND+is_lane_change+=+%27True%27&submit=true
This then provides you with an overview of the segments and a statistical aggregation of the results:
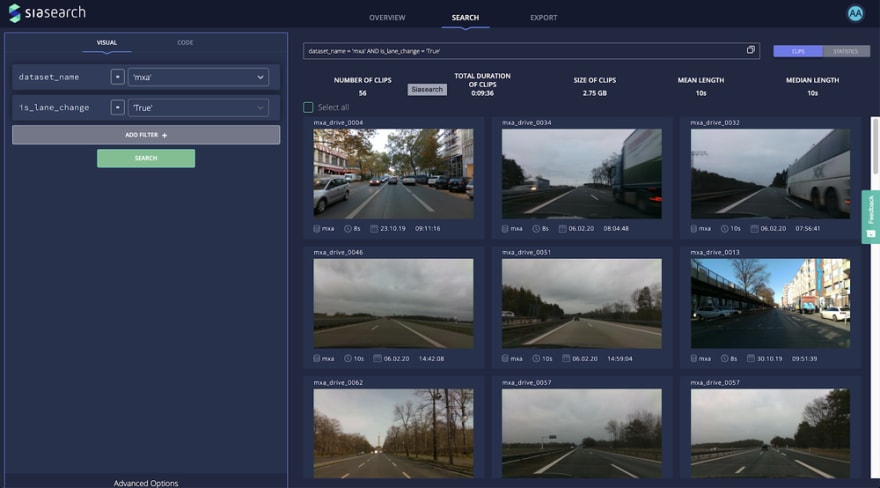
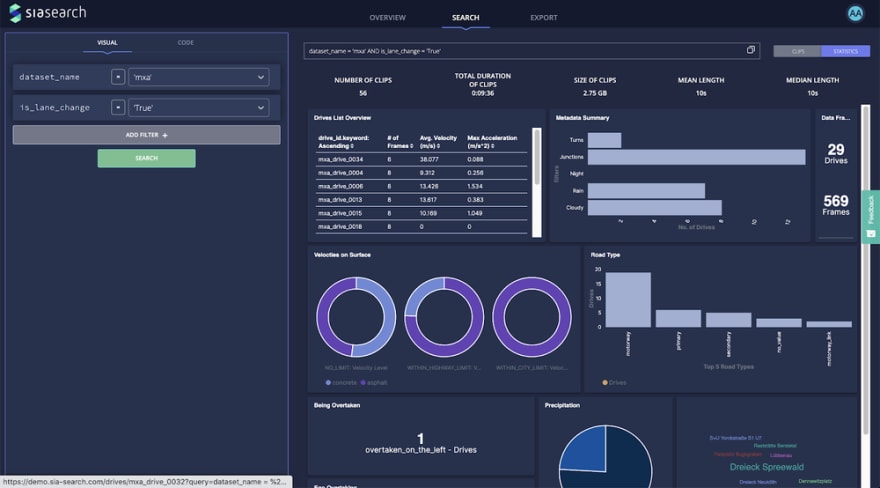
The GUI also allows the user to dig deeper into each segment and use the embedded data viewer:
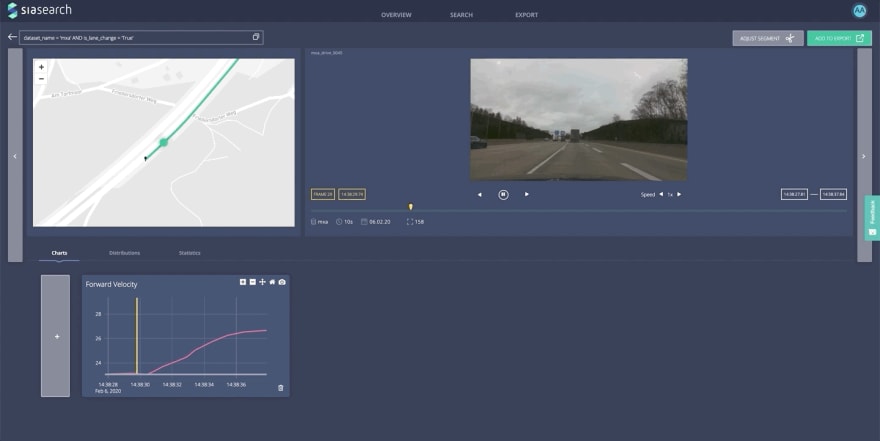
Generating data subsets by tagging
In our simple example the goal was to identify unseen lane changes which are potentially interesting to use for model training and testing. Therefore we also want to be able to tag segments and produce subsets of data. Here we will show you how to tag the first two-thirds of the segments as training data and the rest as test data:
>>> switching_point = int(len(results.segments) *2/3)
>>> for seg in results.segments[:switching_point]:
seg.add_tag("lane_change_train")
>>> for seg in results.segments[switching_point:]:
seg.add_tag("lane_change_test")
It is easy to obtain information about which tags are already present for the current user by calling:
>>> sia.get_all_tags()
['lane_change_test', 'lane_change_train']
Or simply return all segments which belong to a certain tag:
>>> tag_results = sia.get_results_from_tag('lane_change_test')
>>> tag_results.segments[0]
<Segment(drive_id='mxa_drive_0052', start_timestamp='2020-02-06 15:04:47.400000+00:00', , dataset_name='mxa', tag='lane_change_test')>
Accessing additional metadata
If we want to build analytics and visualizations without depending on the SiaSearch web interface we can access SiaSearch’s automatically extracted metadata catalogue through the API. In our example we will also extract information about the vehicle velocity, the road types and the precipitation types under which the lane changes were conducted.
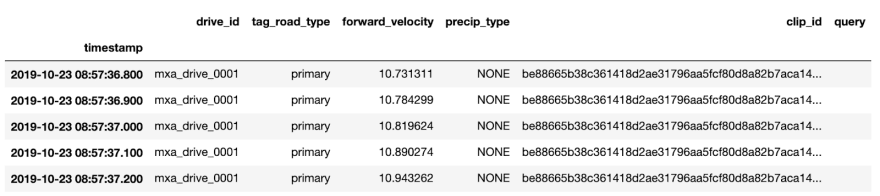
The additional metadata for the desired dimensions can be easily accessed and the results are obtained as a dataframe:
>>> meta_results = results.segments[0].get_raw_values(["forward_velocity", "precip_type", "tag_road_type"])
>>> meta_results.head()
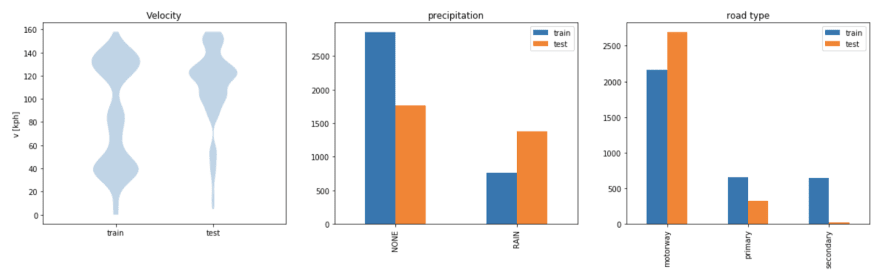
This dataframe allows us to quickly generate new plots in order to analyze the underlying data. In our example this allows us to compare the train and test datasets in a straightforward way by visualizing the additional metadata:
The underlying GPS data can also be obtained in order to generate geospatial visualizations (using ipyleaflet for jupyter notebooks).
>>> m = Map(center=compute_gps_center(results), zoom=7)
>>> add_segments_to_map(
m,
sia.get_results_from_tag('lane_change_train').segments,
color="blue"
)
>>> add_segments_to_map(
m,
sia.get_results_from_tag('lane_change_test').segments,
color="red"
)
>>> m.save("my_map.html", title="My Map")
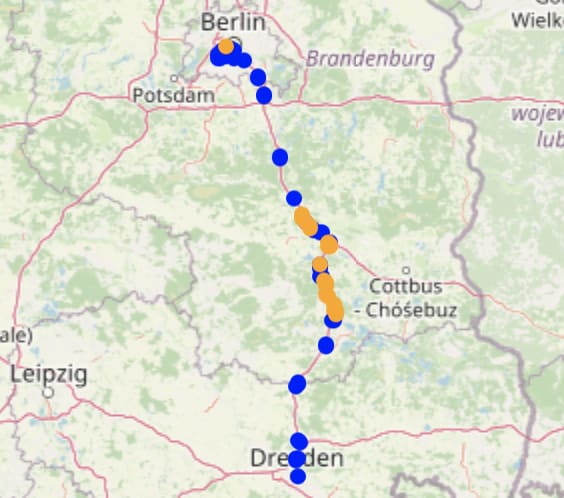
The visualizations obtained through the API clearly show that the data in the train and test sets are not balanced, which could cause biases during training or misleading test results, as most test data was recorded on highways. This is not surprising since the process we used to split the data is very simple (first two thirds of the data put into the training set, the rest in the test set). More iterations or a different split of the data would be required.
Exporting
The final step is to export the results into a format you can use for importing into your model or validation pipeline.
The easiest way to achieve this is to access the underlying Panda’s DataFrame which provides a multitude of export formats to choose from. See the official Panda’s document for all available export formats.
As an example:
>>> df_results = results.df_segments
>>> df_results.to_csv(“out.csv”)
>>> df_results.to_parquet(“out.parquet”)
In future versions we will provide more custom formats, not directly available from Pandas interface, such as GeoJSON, KML, and MAT files.
As shown in the previous steps, the SiaSearch API and Python SDK allow the user to easily interact with large scale unstructured data. Cumbersome data engineering tasks are abstracted away which allows the user to focus on the important task of analyzing the data and identifying the required datasets for training, testing and validation files.
Get started with SiaSearch
If you share some of the problems we talked about, or are excited give SiaSearch a try, request a demo on our website or reach out to us at hi@siasearch.io.
Originally published by Mark Pfeiffer on: https://www.siasearch.io/blog/data-curation-without-the-effort

Top comments (1)
Use long filenames
I even put the gps location in
also the start point for the best action
If you can't find ALL your data like I can.... boo to your curation.
My spectateswamp search finds and highlights all matches.
If the data indicates a pic ... then it is displayed.
Videos and music played.
The directory function provides a text file with all the location and full name
that is searched time and again. Fast Random Full featured
archive.org/details/spectate-01-se...