You can listen to a podcast version on Career Chats or read the updated version of this in The Coding Career Handbook
If you are a lifelong/infinite learner, you want to get the most out of the time you dedicate to learning. What are the determinants of how much you learn over time?
In the formal study of algorithms, Big O (simple explainer here) is often used to succinctly state how costs scale as a function of the amount of work to do. I think we can also take this notation to talk about different forms of learning over time.
Big O is handy because it allows engineers to talk in terms of orders of magnitude (which is more important for architectural decisions) rather than get bogged down in precise details (which are hard to predict and don't matter at scale).
In this post I sketch out Big L notation, which plots your learning as a function of N years of experience, with P peers. Note that while Big O is a cost curve (higher is worse), Big L is a benefit curve (higher is better).
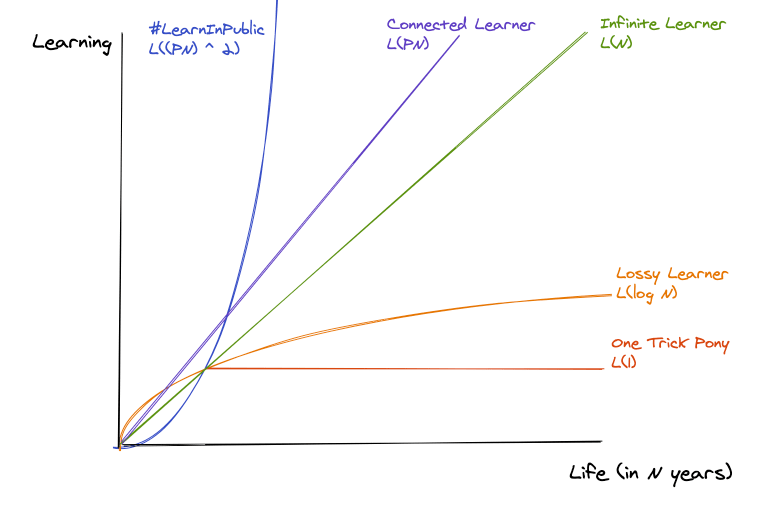
Learning in Private
L(1) - The One Trick Pony
This person learns one thing and chooses to do it over and over again for the rest of their career. You might consider jobs like being a forklift operator or long haul driver or taxi driver or TPS report filer as amenable to this, but you can get L(1) attitudes in high variance jobs like teaching and programming as well. Their competencies don't noticeably scale with years of experience.
You know people like this. They may be stuck in a rut due to unfortunate circumstance, but also due to limitations in personal ambition.
L(log N) - The Lossy Learner
This person's learning function is lossy - they learn things and forget things and have to relearn them again, re-commit mistakes made. They be uncurious - learning reactively as a result of randomly distributed events, rather than having a self directed learning goal.
This is the normal learner.
L(N) - The Infinite Learner
This person learns something new every year and keeps it. Mistakes are not repeated. This requires constantly pushing boundaries and building a system (principles, habits, or a second brain) for the stuff the human mind naturally forgets.
This is most people's idea of an ideal learner.
L(N^2) - The Deep Learner
This may not be a realistic goal for a human to do, but it is an interesting thought experiment. What does it take for someone to scale faster the more years of experience they have in something?
I agree with the breadth vs depth split proposed by Preet. You can be diffuse in your efforts, or you can concentrate your efforts every day building on what you had done the previous day. Take one step each for 360 degrees and still be in the same spot, or take 360 steps in one direction and go places.
The choice might seem obvious, but only if you go 360 steps in the wrong direction it might be a waste of time. This is why I choose the neutral term Learning Gears for the different modes of learning.
I think for true L(N^2) learning, some introspection should take place as well. You ought to be looking back over your prior years and articulating something more than the sum of the parts. Writing a comprehensive historical/technical reference, coming up with a grand explanatory model of Why Stuff Happens, these are all activities of L(N^2) learning.
Learning can compound forwards as well as backwards. If the L(N) learner builds systems to keep themselves from repeating mistakes, the L(N^2) learner automates to save future work, and builds mental models that anticipate future needs, inferring from prior cycles.
Learning in Public
When it comes to learning in public, we introduce another input P to learning. It means whatever you want it to mean - "People", "Peers", "Possible Mentors", or Community.
Of course, these exist when you are learning in private. You have to learn from someone. Most people's P are constant and they don't pay any attention to it.
But you could also learn with someone. When you Learn in Public, growing P becomes an explicit, monitored goal with milestones you track like you do New Years' Eve.
You should also mentally scale it up or down according to how much you think one additional P contributes vs. one additional N.
L(PN) - The Networked Learner
The Networked Learner learns with a group of peers, sharing notes as they go, tapping into them when they get stuck, and learning by answering questions they've never thought to ask. This ability to learn from people either just behind you, slightly ahead of you, or where you are, is profoundly multiplicative.
There is probably a Dunbar limit to how high P can go, but I find active relationships wax and wane such that adding learning peers is still always additive. In other words, Concurrent P matters more than Lifetime P.
It's actually harder to be a Networked, yet Lossy, Learner, or L(P log N). If you do it right, people keep you accountable.
L((PN)^2) - The #LearnInPublic Grand Slam
Alright, we're firmly outside the bounds of human reality here. But what does L((PN)^2) look like?
First of all, you're a Deep Learner. That's a given.
But you're also compounding learning from people proportional to the square of the number of people (aka Metcalfe scaling). The only way to do this is to have people learn from each other independently of you, AND still have you benefit from it.
I think this means actively growing a Community that helps you serve a bigger goal/mission. It can also take the form of Open Source Knowledge. Wikipedia beat the traditional Encyclopedias at a fraction of their budget because it was able to grow at L((PN)^2) vs L(N) or L(PN).
There are people scaling factors beyond N^2 - Reed's law scales at 2^N. But that is again a function of community.
P(N) - Reflexivity in Learning
Of course, "Big L" is just a model of reality, it isn't actual reality. One of the ways it falls apart is in pretending that N and P are independent variables. They aren't. P is likely to grow with N as a function of your seniority and influence - making a good Networked Learner grow on the order of L(N^2) which is plenty great. But if you can figure out how to grow P superlinearly with N - by writing, speaking, teaching, etc - you can make your career explode in possibility.
Little L
I've talked a big game about learning, but I do also acknowledge that learning is not everything. You have to be doing, and you have to be living. How will you measure your life? It's also likely a function of the people you meet and the years you live productively. What insights can we glean there?
Maybe that is the real Big L we should be chasing, at the end of the day.
This thought originated in a tweet.

Top comments (2)
Interesting thoughts! 🤔
I think pair programming is another way to boost P in this model.
Often times we dwell on a mentor-mentee dichotomy when thinking about pairing, but it can also be an effective way for two inexperienced (in general or in a particular area) devs to quickly level up.
The team I'm on has been developing Kubernetes and service mesh expertise this way, and it's been a great way of getting exposed to a broader range of topics. As folks learn new things on their personal/solo learning journeys they share it with their pair -- and vice versa. 🙌
I find that pairing also helps with lossiness of learning. Between the two you will remember more things, especially in deep /complex code