Veri Ön İşleme:
1.Bozuk Veri: Bir çok veri madenciliği algoritması girdi olarak temiz, kaliteli ve gürültüsüz veri aldığı varsayımına dayanarak çalışır.
a. Kayıp Verileri Tamamlama (Missing value imputation): Eksik verilerin bulunduğu satırları çıkarmak veriyi bozabilir, değerli verilerin kaybolmasına sebep olabilir, hele kayıp veriler özellikle bir örüntüye sahip ise ciddi sapmalar (bias) oluşturabilir. Kayıp verileri tamamlamak için istatistiksel yöntemleri veya makine öğrenmesi yöntemleri kullanılması çıkarmaktan daha sağlıklıdır.
b. Gürültülü Veriyle Uğraşma (Noisy data): Gürültülü veriyle uğraşma konusunda bozuk veriyi düzeltme yöntemleri (data polishing methods). İkinci yaklaşım ise gürültülü veriyi filtrelemek ve eğitim verisi olarak kullanmamak.
2.Boyut İndirgeme (Dimentionality reduction): Bağımsız değişken sayısı çok fazla olduğu durumlarda bağımlı değişkene olan etkiler çok zayıflar ve kurulan modellerin yorumlanabilirliği ve gerçek hayata uygulanabilirliği azalır.
a. Özellik Seçimi (Feature Selection): Özellik seçimi, problemi çözmek için gereksiz ve problemin çözümüne etkisi olmayan özellikleri tespit ederek bunları kullanmamaktır. Özellik seçimi ayrıca aşırı öğrenme (overfitting) olasılığını da azaltır, model eğitiminde gereksiz kaynak tüketiminin özellikle ana bellek (bilgisayar rami), önüne geçer.
Train, Test ve Validation:
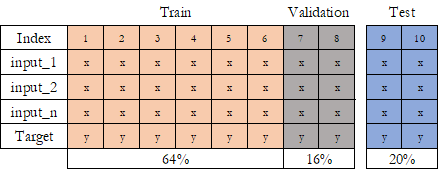
Train Test ve Validation Örnek Dağılımı
Train Set (Eğitim seti): Modelin eğitildiği veri kümesidir.
Test Set (Test seti): Bir eğitim kümesinde geliştirilen modeli değerlendirmek için kullanılan bir veri kümesidir.
Eğitim setimiz büyüdükçe modelimiz daha iyi öğrenecektir. Test setimiz büyüdükçe ise değerlendirme metriklerimize daha iyi güvenebileceğimiz daha sıkı güven aralıklarımız olacaktır.
Random state parametresine istediğiniz bir değeri verebilirsiniz. Bu parametre kodunuzu her çalıştırışınızda veri kümesinin aynı şekilde bölünmesini sağlamaktadır. Sürekli çalıştırdığımız durumlarda modelimiz test verimize adapte olup overfitting yapmaktadır.
Validation Set (Doğrulama Seti): Modelin üzerinde eğitim alınmamış ve hiperparametreleri ayarlamak için kullanılan veriler. Validation set ile her eğitim sonunda model etkinliğini test edip nihai modele karar verdikten sonra test seti ile test ederek modelimizin etkinliği daha sağlıklı bir şekilde gözlemleyebiliriz.
Validation setin modelin fit performansına etkisi yoktur. Sadece test setine overfitting olmasını önlemek için ara bir aşamadır.
Modelin overfit veya underfit olmasını kontrol eden şey test setidir. Validation set sadece test setine olan overfiti denetler.
Cross Validation: Veri setini k tane parçaya ayırarak eğitimi yapar, bu k parçadan 1 parçayı test için kullanır, bu parça her seferinde bir önceki iterasyondan farklı olur, bu yüzden modelimiz sürekli yeni test seti ile test edilmiş olur.
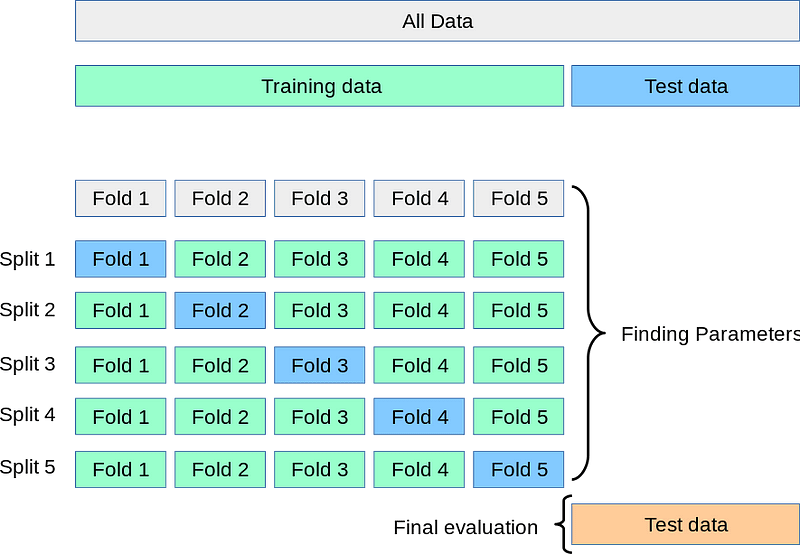
Cross Validation
Değerlendirme Ölçütleri:
Confusion Matrix: Gerçek değerlerin bilinmekte olduğu bir dizi test verisi üzerinde, bir sınıflandırma modelinin performansını tanımlamak için sıklıkla kullanılan bir tablodur.

Karmaşıklık Matrisi
Doğruya doğru demek (True Positive - TP) - DOĞRU
Yanlışa yanlış demek (True Negative - TN) - DOĞRU
Doğruya yanlış demek (False Positive - FP) - YANLIŞ
Yanlışa doğru demek(False Negative - FN) - YANLIŞ
Prediction [tahmin] verileri ile observe [gerçek] kısmındaki bağıntılara bakılır.
True Positive ve True Negative Değerlerimizin yüksek olması iyi bir sınıflandırma yaptığımızın göstergesidir.
Accuracy = Doğru Tahminlerin Sayısı / Tüm Tahminlerin Sayısı -> [91/100=0.91]
Precision = Pozitif olarak tahmin edilenlerin gerçekte kaçta kaçı doğru. -> [1/(1+1)=0.5] 2 tahmine 1 doğru.
Recall = Model, pozitif classların kaçta kaçını yakalayabiliyor. -> [1/(1+8) = 0.11] 9 kez varken 1 kez var dedik.
F1 Score = Precision ve Recall değerlerinin ağırlıklı (harmonik) ortalamasıdır. 1 ile 0 arası değer alır. 1 en iyi başarım anlamına gelir.
ROC Curve (Alıcı İşletim Karakteristik Eğrisi), AUC:
Sınıflandırma problemlerinde olasılık değerini sınıflandırmak için eşik değere (threshold) ihtiyaç duyulur. Örneğin 0.5 gibi; Sonuçları, 0.5'in altı ve 0.5'in üstü olacak şekilde böler. ROC Curve, eşik değerinin performansını gösteren eğridir.
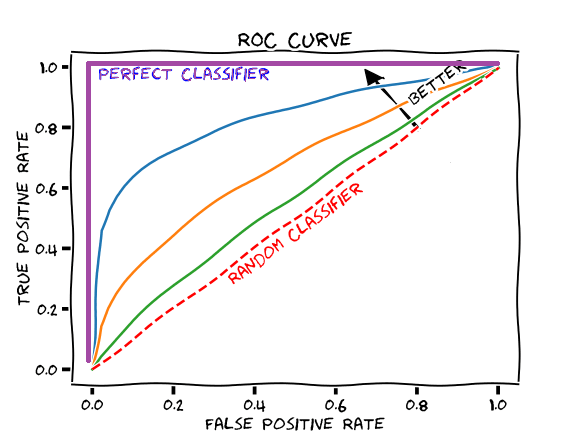
Roc Eğrisi
Tablonun x ekseninde FP Rate [False Positive Rate], y ekseninde ise TP Rate (Recall) [True Positive Rate] vardır.

AUC Skoruna Göre Eğriler
FPR = FP / (FP + TN) (1-Specificity olarak da biliniyor.)
TPR = TP / (TP + FN) (Sensitivity olarak da biliniyor.)
ROC eğrisinin altında kalan yere AUC (Area Under the ROC Curve) denir.
Positive Class'ı Negative Class'tan ne kadar ayırabildiğini verir. Alan arttıkça ayrım yeteneği artar.

Top comments (0)