
If you are new to the field of Machine Learning and Data Science and have already done some implementations of some of the Machine Learning algorithms, you might have heard the term Hyper Parameter Tuning. Yet, if you have not heard the term, I would like to take the privilege to ensure you that you are going to hear it soon when you will focus on the optimization of the performance of your algorithm or ML model. So, let's dive into today's discussion.
✴️ What is Hyper Parameter?
Hyper Parameters are those parameters of a machine learning algorithm that controls the learning process and efficiency of the machine learning algorithm in its training phase and of course can be set and optimized manually. It basically determines how the algorithm is going to take the different learning approaches in the different steps of its learning process. The wrong choice of Hyper Parameters can make your machine learning model vulnerable to overfitting or underfitting, resulting in poor performance. Therefore determining hyperparameter setting wisely can certainly make your machine learning model better.
➡️ What are the Hyperparameters of KNN?
Let's take the example of one of the simplest machine learning algorithms that beginners tend to understand easily, KNN (K Nearest Neighbour).
If you have implemented the KNN algorithm using the popular Scikit Learn Library in Python, you may have noticed that the KNN class object can take some arguments (values of parameters) at the time of creation according to the documentation of scikit learn. If you don't pass values to these parameters on your own, they would be set to their default values as per documentation.
Let's see how we create a KNN object in scikit learn. Here, some of the hyperparameters in KNN are "n_neighbours" (the value of K), "metric" (distance metrics to be used, for example, manhattan or euclidean distance, etc).
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier()
Here, I didn't pass any values of the parameters manually. But if do it like this;
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbours =9, metric= 'manhattan')
Now, I have passed 9 to the parameter "n_neighbours", and so the K value for this KNN would be 9, and also as I have passed "manhattan" to the parameter "metric", the manhattan distance will be used in certain calculations of the training phase. There are some other hyperparameters for KNN also which you can learn by referring to the documentation of scikit learn. Just like this, in Random Forest Classifier you can manually set the number of trees to be used or built for classification through the "n_estimators" parameter, and the splitting criterion through "criterion".
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=1500, criterion="gini")
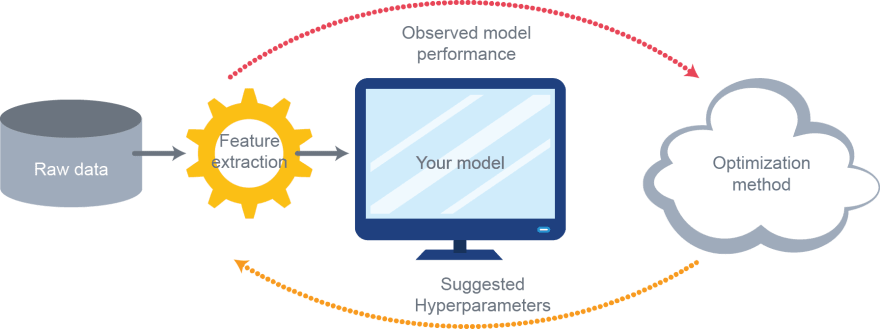
✴️ What is Hyperparameter Tuning?
There are a bunch of hyperparameters that can be set manually to optimize the performances of the different machine learning algorithms (Linear Regression, Logistic Regression, Decision Trees, Adaboost, K Means Clustering, etc). But there are no fixed universal best settings of hyperparameters of a machine learning algorithm. You might need to experiment over a set of possible values to choose the best settings according to your dataset and criteria. And this process of choosing the best set of values of hyperparameters is called hyperparameter tuning. For example, trying different values of K in KNN, or choosing the best splitting criterion, decreasing or increasing the number of trees in Random Forest Classifiers. Hyperparameter tuning is one of the most essential knowledge for machine learning engineers and data scientists. Hyperparameter tuning is also important in Deep Learning algorithms like CNN (Convolutional Neural Networks), RNN(Recurrent Neural Networks).
Conclusion
Don't forget to follow us. And share your thoughts with us in the discussion section.
💡 Subscribing to our YouTube Channel TechLearnersInc and Telegram t.me/TechLearners will be amazing.

Top comments (0)