
The Linear Regression algorithm can get the best fit line for our data set. We mostly use it to predict future values. But, when we use linear regression, We can see little errors on predicted values rather than on the actual data points. Sometimes, the actual value and predicted value can be change. In this post, see what is the Cost Function is.
There are many Cost Functions in machine learning. Each has its occasion depending on whether it's a regression or classification problem.
- Regression Cost Function
- Binary Classification Cost Functions
- Multi-class Classification Cost Functions
What is an Error?
Always I try to give a simple answer for better understanding. Look at the linear regression graph below. In that graph, we can see the difference between the actual value and the predicted value. Basically, that difference is an "error". If you don't understand what is linear regression is, I would recommend reading my previous article about linear regression.


Cost Function
So Cost Function helps to understand the difference between the actual value and predicted value. The definition of the Cost Function is "It's a function that determines how well a Machine Learning model performs for a given set of data."
What is the formula of Cost Function?
The Cost Function has many different formulations. Let's see the Cost Function for linear regression with a single variable.
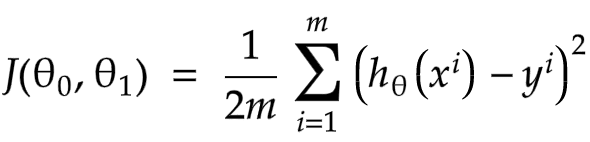
- m: Is the number of our training examples.
- i: The number of Examples and the Output.
- Σ: The Summatory.
- h: The Hypothesis of our Linear Regression Model
In addition, we can find the Cost Function with this simple formula below.

So, how can we make the Cost Function as little as possible? the gradient descent is the best method rather than linear regression for minimizing the Cost Function. We'll talk about that later.

Top comments (0)