
With software development, we are often presented with alternative choices for libraries and tools that appear to accomplish the same sort of things. Each one will advertise its key advantages, and we attempt to weigh the pros and cons.
Sometimes, the differentiators have less to do with what we are accomplishing and everything with how we accomplish it. In those cases, it isn't always as clear what the tradeoffs are. Are these things that even matter?
There isn't a rule here. Finding myself in the middle of these discussions regularly I thought I'd share a few around JavaScript web development.
1. MPA vs SPA
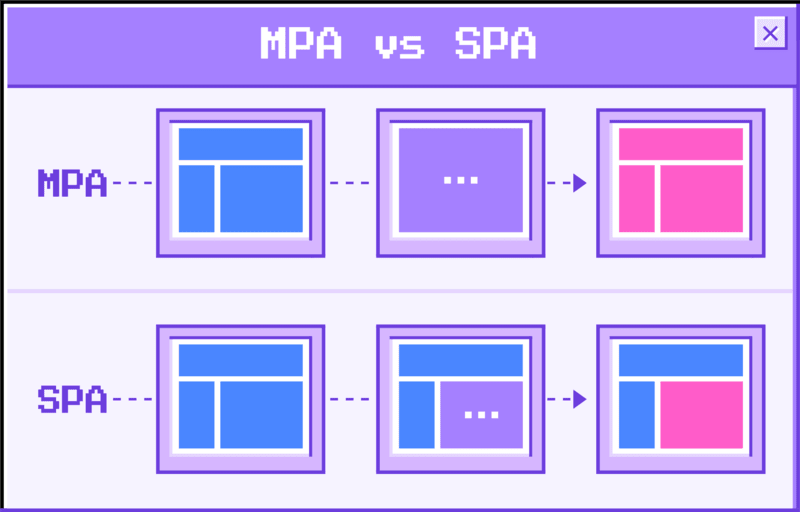
Single Page Apps vs Multi-Page Apps is by far one of the biggest sources of confusion I've seen for the web. There are so many different patterns that exist for building websites and applications it is far from clear what people even mean by these terms.
Historical considerations aside, the simplest heuristic for identifying between a Modern SPA and MPA is the concept of JavaScript entry point. If it is the same for all pages you have a SPA. If each page has its own topmost entry it is an MPA.
Your bundler might produce different chunks per page but if your application starts from the same point regardless of the page you have a SPA. You can pre-render it into 1000 different pages. You can preload the per page chunks for each. You can even turn off client-side routing. It is still a SPA architecturally. Single application execution defines behavior for all pages.
Next, Gatsby, Nuxt, SvelteKit, you name it falls into this category. Single Page App architecture applies to server-rendered pages and statically rendered pages just the same.
So what's an MPA then? A website or application that is written from the top at a per-page level. You can use the same components across pages but there is not a single entry point. When the server receives a request and serves that page the JavaScript execution entry is unique to that page.
This means your routing is server-side. While a SPA can opt into this from a top-level architectural perspective an MPA must function this way since it doesn't have the code immediately or lazily loaded to render any page other than itself. Some tradeoffs are worth an article in itself. But in short, MPAs having no expectation of being re-rendered in the browser can be optimized to send significantly less JavaScript.
In JavaScript land, only a few frameworks are optimized for this scenario. Marko is one. And recently we've seen frameworks like Astro and Elder provide wrappers for existing SPA frameworks. Albeit ones that only support static rendering for now. And Qwik as new framework from the creator of Angular also coming to answer the question.
It's worth mentioning, MPAs are each pages themselves so they could always host a SPA on a given page. And through iFrames or other HTML injection frameworks like Turbo, it is possible to serve an MPA off a single page.
The key takeaway is that SPA vs MPA isn't about how many pages you are serving. It is a decision you make depending on how important initial load performance(MPA) is versus future navigation experience(SPA). Either approach has tools to improve their weaknesses but each is fundamentally tailored to optimize for their primary usage.
2. React vs Reactivity

You've probably heard somewhere React is not reactive. Maybe someone thought it was a funny joke. You know, React is in the word Reactive. Maybe you read a blog post that got into the fundamentals of push-based observables versus scheduling. Maybe you saw a framework advertise itself as "Truly Reactive" or "Purely Reactive" as a differentiator from React.
Here is the thing. There have been many attempts to formalize what Reactive programming means. Some are more narrow than others. So much so that even within reactive circles we've needed to differentiate between "Functional Reactive Programming" and "Functional + Reactive Programming".(source)
The common thing driving all these solutions is they are systems based on declarative data. You code in a style that describes the state in terms of fixed relationships. You can think of it as equations in a spreadsheet. The guarantee is that with any change everything stays up to date.
If this sounds like pretty much any web UI development you've worked with it's for good reason. HTML is declarative and we build on top of it. At this point in terms of frameworks being reactive means any number of things.
Some take it to mean you have control over the primitives to wire up behavior, but it would be hard not to consider React Hooks in this way.
Some take it to mean that updates happen automatically without calling an update function, but these libraries like Svelte do in fact call component update functions behind the scenes.
Some take it to mean granular updates without diffing. But every framework diffs (more on that below). Or that it means we remove scheduling but almost all frameworks batch changes and schedules them on the next microtask.
So React might not be formalized reactive programming but for all effective purposes, the same things are being accomplished in, perhaps surprisingly, almost the same way.
3. VDOM vs No VDOM

Does old become the new new? Well, sort of. All rendering in JavaScript frameworks comes down to knowing what has changed and updating the DOM accordingly. The update part can be done pretty effectively with familiarity with DOM APIs. All frameworks have access to these tools. But what about knowing what has changed?
Believe it or not, this process is similar in the majority of frameworks. The reason is reading values from the DOM does not come without consequence. In the worst case, it can even cause premature layout calculations/reflows. So what do we do? We store values outside of the DOM and compare those. Has it changed yes? Apply updates. Otherwise no. This is true of all libraries VDOM or not.
But how we go about this is where the differences lie. There is 2 axis along which solutions differ:
- Granularity of change - How much do we re-run in response to the user changes
- What are we diffing - data, VDOM abstraction
For a VDOM library, like React, the granularity of change is per component. On the first run the code you supply to render functions or function components executes and returns a bunch of Virtual Nodes. The reconciler then creates the DOM nodes from that. On subsequent runs, new Virtual nodes are diffed from the previous Virtual Nodes, and updates to the existing DOM nodes are patched in.
For a non-VDOM library, like Svelte, the granularity of change is also per component. This time the compiler has split create and update paths. On the first run, the create path creates the DOM nodes and initializes locally stored state. On subsequent runs, it calls the update path which compares the values of state and patches the DOM where applicable.
If these processes sound incredibly similar, it's because they are. The biggest difference is that the VDOM has an intermediate format for diffing instead of just a simple locally scoped object and Svelte's compiler just compiles only the needed checks in. It can tell which attributes change or which locations child components are inserted.
Other frameworks like Tagged Template Literal uhtml or Lit don't use a compiler but still do the diff as they go in a single pass like Svelte versus React's two pass approach.
These traversals don't need to be expensive. You can apply similar optimizations to VDOM libraries as we've seen with Inferno and Vue using compilation. In so they prevent recreating VNodes similar to how a non-VDOM library avoids unnecessary creation of DOM nodes. It is all about memoization, whether of VDOM nodes, data objects, or through reactive computations.
So what is the meaningful difference? Not very much. Diffing isn't that expensive. The only thing left we have to play with is the granularity of change, if ideal diffing and updates are about the same cost all we can do is do less diffing. But granularity generally brings heavier creation costs. Thankfully there is a lot more optimization to be done with compilers to address those creation costs.
4. JSX vs Template DSLs

This probably seems similar to the last comparison and it is related for sure. Some people view JSX as HTML in JavaScript, and Template DSLs or Single File Components(SFCs) as JS in HTML. But the truth is these are all just JavaScript. The output, in the end, is JavaScript with maybe some string HTML in there somewhere.
So if the output is more or less the same how are these different? Well, they are becoming exceedingly less different. A framework like Svelte has full access to JavaScript in its Script tags and template expressions. And JSX while dynamic still has contiguous blocks that can be analyzed statically and optimized.
So where is the difference? Mostly around what can be inserted. Attributes are easy to analyze and optimize, but what goes between the tags in JSX could be a few things. It could be text, it could DOM elements, it could components or control flow. Ultimately though it's text or DOM elements.
So a template DSL removes a little bit of the guesswork with what is being passed here which otherwise requires a check every time. But that isn't huge savings. Even with JSX, you have some ability to look at what the JavaScript expressions are doing. SolidJS uses heuristics to determine if something could be reactive.
The biggest benefit of Template DSLs is the explicit syntax for control flow can make it more easily optimizable for different targets. For instance, a for loop is more optimal than map. If you are rendering on the server just creating a giant HTML string, something as small as that can improve performance by a noticeable amount. But that is just a simple abstraction.
But outside of these sort of scenarios there really isn't any differences fundamentally. Sure most Template DSLs don't have equivalent to React's Render Props, but they could. Marko does.
5. Runtime vs Compiled Reactivity

This one might be a bit more niche but it's still a question I get often. What's the difference?
It comes down to dependency tracking. Runtime reactive systems like Solid, MobX, or Vue collect dependencies as their computations run. They intercept reactive atoms(signals, refs, observables) reads and subscribe the wrapping scope to them. So that later when those atoms update they can re-run these computations.
The key thing is that since the dependency graph is built on the fly they are dynamic. They can change run to run, and in so you are managing a set of dependencies. Every run means potentially new subscriptions and releasing others.
Compile-time figures out the dependencies ahead of time. In so, there is no need to manage subscriptions as the relationship is fixed. The code runs whenever the dependency changes. This has far less overhead at runtime. And even means that computations don't need to run to know their dependencies.
However, these dependencies aren't dynamic so there is always a chance of oversubscribing and over executing. Situations, where runtime can pull reactivity from a deep call stack, become harder because you can't know if something is reactive without tracing its bindings.
This works both ways though. If you were to put a setTimeout in an effect, with runtime reactivity by the time it executes it would not be in scope. With compile-time, if it's inside the function it's easy to register the dependencies. Similar considerations when you update values. Svelte looks for an assignment operator which is why list.push doesn't just work.
There is a lot to be done with the compiler and it is easier to do some things than others. In the end, for the most part in terms of raw performance, this is mostly a wash. But a compiler can bring a lot of other benefits when you can leverage specific syntax to better convey intent. This is the next logical step over template DSLs and I think we are just scratching the surface here.
6. Components vs Web Components

I want to open this by saying if there is one takeaway here, don't assume the word component means the same thing to everyone.
I've been on both sides of this. I used Web Components in production for 6 years at the startup I previously work at and I've also worked and written Component frameworks. To me when people compare these they are talking about very different things.
A Web Component is very much a Custom Element in every sense. It is a DOM node that encapsulates behavior with a common interface. We get attributes and convenient hooks to write custom behavior on creation, and when attached and removed from the DOM. The latter 2 lifecycles are important because they are complementary. It means that for the most part all side effects are tied to DOM connectivity.
What is a Framework Component? To paraphrase something Rich Harris once said, they are tools to organize our minds. Now that's abstract. But that's the thing. When you look at components in frameworks, they are abstract. They might output DOM elements, or not. Their lifecycle is not tied to the DOM. Some manage state, they are rendered on the server or maybe mobile. They are anything the framework needs them to be.
The first is an interopt story, the second an organization story. Are these congruent goals? To a point. But neither will compromise on their primary purpose. And in so they are destined to stay in their lanes. I mean you can add more framework-like behavior to Web Components but then you become a framework yourself and no longer are standard. But as soon as you take the solution farther, like SSR you are inventing new territory.
This can be argued to be ground for new standards but I'd argue that standards development isn't an exercise in building a framework for the browser. Opinions change, technologies evolve. In the web, the DOM may be timeless but the way we organize our applications is not.
On the framework component side, there is no lack of incentives to take the abstraction further. The truth of the matter is a specific solution can always be more tailored to the problem. And in so a React Component is always going to be capable of being better in a React App than a Web Component. And this is true for any framework.
When people talk about re-inventing the wheel, they aren't wrong but how much does this matter. In this petri dish of JavaScript frameworks constant re-invention is the catalyst to evolution. Ideally, we are talking about 2 sides of the same coin. In practice, there might be more friction there.
This isn't a "use the platform" or "don't use the platform" argument. Web Components have a role to play as long as we clearly understand the difference. Every framework uses the platform. Some are just better than others. And some better than Web Components can. After all Web Components are just Custom Elements. And sometimes more DOM nodes are not the solution to the problem.
It was fun to dive into a few topics that I've gathered opinions on over the years. If you have any ideas of similar comparisons let me know in the comments.





Top comments (27)
I am researching reactivity in general and a few reactive patterns (frp, push \ pull, and so on) for a few years already and I want to insist on a "reactive" definition.
Reactive programming is a pattern of delegating the responsibility of initialization data processing to the data source, which doesn't know dependent units and can't interact with it outside one-way notification.
FRP, OORP, Flux, two-way binding, single-store, granular updates are just buzzwords on top of that, other high order patterns.
Rx, Solid, React, Even Emmiter is all about reactive programming.
The main reason for that is to move components coupling from code to runtime, that's all.
I never thought about this before I listened to Rich Harris and his talk about rethinking reactivity where he explained how React uses the virtual DOM, and Svelte essentially uses hierarchical chaining (I'm not sure if there's a proper name for it but that sounds about right).
The reason it was so interesting to me is because if I didn't know what the virtual DOM was and someone asked me how I thought Reactivity worked, my instinct would be to describe a chain of dependencies for each object.
So basically having events for data changes?
Doesn't it make more sense to
diffapplication state? And then only derive and update those parts of the view that need updating.Granted diffing the DOM is more abstract and could perhaps be more reusable across a larger range of applications but it's like preferring to catch the horse after it has left the barn rather than just locking the barn door. Maybe it's more to the point that VDOM-based solutions are more focused on providing an alternative to the DOM API that is as far removed from the DOM API as possible.
Good luck with that one.
Certain members of the front end developer community seem to have a hard time differentiating between a framework in general and an "application framework". There seems to be a "one word", "(my personal) one meaning" mentality out there.
I think the second one is even more problematic though - organization of what?
If you can get people to accept Web components as mere custom elements (while the existence of the shadow DOM suggests the DOM component perspective) I think people will quickly lose interest - especially as Safari only supports autonomous custom elements without a polyfill (or ponyfill).
I think not foreseeing the need for direct support of SSR/partial hydration may turn out to be the Achilles heel of the v1 spec. Hand designed solutions (that take over browser parsed DOM fragments) are possible with the technologies introduced by the spec but are not likely going to be embraced by a community with a very specific expectation of what a "component" should be.
… or components for that matter.
What I'm alluding to is that components boundaries need a lot more attention. You've published a number of articles about the performance impact of component boundaries but there is another aspect that I think needs more scrutiny.
On a legacy automotive engine a carburetor can be considered a "component". The way many front end framework components are authored is reminiscent of a small carburetor permanently joined to a slice of an engine block containing a single cylinder. When it comes to combustion engine design that idea would be considered ludicrous, yet in front end development this type of "self-containment" with high internal coupling is considered necessary to maximize productivity.
The Elm community gave up on "components" because of two distinct aspects of The Elm Architecture:
While both aspects communicate via the Model there is an important insight - the boundary around the part of state affected by a message often didn't match up with the boundary around the parts of state needed to render the affected parts of the view - thus making it impossible to package "a bit of View" together with a "bit of Update" (and therefore bit of Model) into a "self-contained component".
Now granted SolidJS's fine-grained reactivity gets around this by be being - well - fine-grained enough to not have to worry about these courser grained boundaries. But …
While framework components need to manage view state - shouldn't that be separate from client-side application state? This of course goes back to UI as an Afterthought which itself is based on earlier work. It seems to me that the current generation of "light weight" front end frameworks promote framework component boundaries that aren't necessarily ideal for maintainability - trading it off for perceived short-term productivity gain and perceived but usually unrealized reusability.
Great Article!
As I mentioned in my comment; doesn't it make even more sense to diff nothing, and instead react directly to the data changes?
Not all "data" is created equal.
UI as an Afterthought:
In the article state refers to state handled by MobX. So
I don't see the problem here. State changes -> you respond accordingly. If only a small part of your state changes, you could specifically respond to only those changes (and only update the UI where necessary, or not at all).
Because …
… because …
Current generation UI frameworks have a tendency to encourage client side architectures where "the UI is your application" - it typically takes a significant amount of discipline and effort to persevere with a "the UI is not your application" client side architecture.
Jest has pretty much shown the downsides of the "React is your application" architectural style. The testing framework is bloated and slow because that is what happens when you need to "unit test" "Smart UI Components".
Extreme Programming Explained (p.117, 2000):
This lead to the The Humble Dialog Box (more generally the Humble Object) back in 2002 - yet for some reason front end development 20 years later continues to ignore this insight:
Elm's update/view separation has a counterpart in the OO world - Command Query Separation. Traditional OO would argue the accessors and mutators belong on the same object because that object manages a single concern. Command Query Separation challenges that notion; it argues that updating state (via commands) and retrieving a representation of state (via queries) are separate concerns.
Similarly a dumb UI fragment is simply a representation (query result via subscription) of some part of the application state. That fragment may contain some simple actions (commands) to initiate a change of some part of application state - perhaps even a portion distinct from the part the original representation was based on.
jQuery projects typically ended up being a Big Ball of Mud because as a library jQuery made it extremely easy to work with the DOM, leading developers to try to solve all problems within the DOM. But the DOM was simply the representation of server application state as parsed by the browser - if you were doing anything interactive on the client side that representation might no be enough to rehydrate client side application state (that is what Embedding data in HTML is for). Client-side application state needed to be managed separately from the DOM and it's changes needed to be propagated to the DOM. Segregated DOM demonstrated that approach but by that point AngularJS and React already had all the attention.
Isn't that exactly what I'm proposing though? Having the data live in one place, and an mutation observer sitting on top of it changing the UI to reflect data changes. The data doesn't need to know about the UI and can live in its own little (testable) world.
User actions could then be passed back to the data as events, and suddenly the whole thing starts looking a lot like an MVC design. Or, if we want to look at it from the object side, we'd end up with two objects that communicate through message-passing, which is also an excellent way of de-coupling different parts of an application.
My interpretation of your statement is that you are proposing a variant of MVC where the mutation observer is intimately familiar with both the model and the view - i.e. is tightly coupled to both. The logic around such a mutation observer would be anything but so simple that it can't possibly break.
The point is to create the conditions where you don't need to microtest the dumb UI at all - delaying that part for integration testing.
Even Pattern-Oriented Software Architecture Vol.1 (1996) lists some hefty liabilities for MVC (p.142), in particular:
A consequence of the tight view/controller coupling is that with the controller being the most complex piece of the pattern a "dumb view/controller" becomes essentially impossible.
(p.136)
This is already is starting to look more like something like Flux where the "commands" become events or actions. The problem with the controller is that it orchestrates - orchestration logic tends to be complex. Sometimes choreography lets you break up that complexity into smaller more manageable pieces - ultimately that's what a state that accepts actions and supports change subscriptions is all about. That way an application can be built in terms of application actions and subscriptions to application events.
However in some cases the flux-style single global store just isn't optimal.
Aside: MVC: misunderstood for 37 years
So the ideal scenario is where "dumb UI fragments" can be updated via application event subscription (thin events requiring additional querying of the application to obtain relevant view state or fat events containing the relevant view state) and affect the application via application actions. The application gets to dictate the shape of the application events and application actions. The dumb UI depends on the application - not the other way around nor is there something (complex) sitting in the middle, brokering everything.
That MVC thing was a bit of an accidental red herring. Personally, I don't really like the idea of using MVC as a design philosophy on its own and only wanted to mention the similarity. More than the MVC part, I'd focus on the message-passing aspect of it, which to my knowledge is about the most decoupled way we know for two parts of a software system to interact.
Let's skip the controller part entirely for now, and just consider the data (model) and the UI (view): Ideally both would send very generic messages to the other, so neither would have to make any assumptions about the other.
But even in a more "real world" example, it will more often be the UI that will depend on certain assumptions about the data, not the other way around, which I find ideal.
This way, if we put the business logic on the data side (aka. coupling model and controller), we can reason about that side and test it independently of the UI.
The similarities to MVC are obviously still there, but more in the sense that it's a way to categorise components of our application, not a template for how to build it in the first place.
If any single paradigm could be used to describe this form of application structure, it'd be the original idea of Object Orientation (one that's more about message-passing and less about classes and inheritance).
That's not the mainstream perspective but the Joe Armstrong perspective:
And loitering here a bit subscribe-notify is a common communication pattern between BEAM processes as it decouples the Provider from the Subscriber. That is the relationship that you want between the application (Provider) and the dumb UI (Subscriber) in the context of UI updates. The beauty of that approach is that update logic doesn't have to know which parts of the UI are active to push updates out but only has to supply updates to the parts of the UI that are currently subscribed.
Aside: You may find David Khourshid's XActor interesting (and visit his Redux is half of a pattern articles while you're at it).
Not sure about the "generic message" and "no assumptions" aspects:
"The application" leads, the "dumb UI" has to follow.
That said there is also a Consumer Driven contract dynamic between the consumer "dumb UI" and the provider "application". The UI has to fulfil its intended purpose so the application has to make accommodations:
The aim isn't "loose coupling" but an application core that has no direct dependencies on the UI.
Nicolai M. Josuttis: p.9 SOA in Practice
i.e. we're investing in just enough complexity to keep the application decoupled from the UI - but no more.
There is that word again - component.
At least that's what the UML modeling glossary states.
😁
Doesn't it suck that we have to make that tradeoff? I mean, both features are really really important for any app or site.
Why are SPA's naturally better at navigation experience? Because of animations, and relying more on replacing components on the page instead of forcing a full page change?
What is even a "page", in this case? When swapping out components, fluidly updating/morphing the UI bit by bit, when would/should a SPA decide to change the URL?
It's so complex. I'm starting to appreciate that there is a fundamental mismatch between the concepts of "documents/pages" and "application" which cannot simply be padded over by frameworks/libraries. The problem is exacerbated by the fact that to a consumer there isn't any material distinction between the two concepts (it's just a GUI), and sites often evolve into apps, as consulting clients want more and more features. Thus often invalidating any sound architectural trade-off one might have made in advance. In addition to the architectural complexities needed to be juggled by developers, who mostly really just want one single uniform way of working, which "just works".
Also, when reading about Resumability vs Replayability (re: Qwik), I wonder how approaches like Hotwire Turbo, which you mentioned, compare? Both Qwik and Hotwire seem to be DOM-centric.
Isn't Hotwire basically already "resumable"? Since Turbo Drive circumvents the need for rehydration, Turbo Streams reuses the server-rendered HTML, and Hotwire Stimulus also stores state within the HTML, and doesn't perform heavy bootstrapping or reconciliation? And how is Fine-Grained Lazy-Loading different from Turbo Frames?
Maybe @adamdbradley , @mhevery and/or @excid3 , @julianrubisch , @javan , @kirillplatonov could help clarify the similarities and differences between Qwik and Hotwire (specifically its Turbo and Stimulus parts).
The difference is that Qwik isn't saying everything needs to be rendered on the server. You can mix Turbo with Stimulus and get elements of this. But Turbo is more just a means of HTML partials. You could use that with any of the partial hydration approaches to have benefit of not shipping js to render it. But Marko or Qwik(and really modern js frameworks) are designed so the shift between hydration and client render is seamless.
I will say this html centric is a bit overplayed. I agree from a transport perspective but that can be in the form of inlined script tags etc.. unless you can solve double data which these aren't claiming you can achieve the same without resorting to what can be serialized as an attribute.
In general for what it is doing you can compare these with Turbo and all, but when it comes to app mental model and DX these are worlds apart. One feels like layering a Javascript app on server rendered views, the other feels like authoring a single app experience like you'd find with any JS Framework, ie React etc.
Thanks for clarifying it a little bit.
Hm. But Qwik, being an MPA, has server-side routing, like you said. It's client also focuses on "resuming" HTML rendered on the server, and is apparently also completely stateless. So why wouldn't everything be rendered on the server, then? What would be beneficial to render on the client? Animations (like on entry/exit)? Being stateless, does Qwik ever render anything on the client? To me it seems (from their github description, and blog posts) that SSR is not only Qwik's focus, but its fundamental mode of operation. I can't see how replacing sections of the DOM with SSR'ed HTML is any different (or more client-side rendering) than Turbo?
What do you mean by double data?
Yeah, the mental model seems quite different, and I appreciate that authoring components in React/SPA style is preferable DX to having HTML template partials which later has to be targeted from JS (Stimulus).
They have client state they just put it in the HTML, keep on reading and reflecting it back. Again I think they are just overplaying the it's just HTML thing a tiny bit. It's really no different than anything else other than by keeping it in the HTML they can pause and resume the same page multiple times (like if stored in service worker app cache). Of course limitations here around serialization and after render performance (constantly reading from the DOM/reflecting to the DOM is less than great overhead). One could obtain resumable hydration without doing anything HTML specific. All you need to do is serialize the props to every component to get the same. Of course that is wasteful, so a better approach is to look at it like a reactive data graph. Qwik does that and so could anyone else not doing exactly what Qwik does.
Qwik's approach could apply to a SPA with some refinement but they aren't focusing there right away. And I imagine given Builder.io static site generation will be the starting point. But look at their TodoMVC example Misko tends to show off. That is a very client side application. Each new Todo is client rendered, each removal and edit as well. Qwik only loads the event handlers you need and in so has incredibly granular hydration. But you write your TodoMVC app like a TodoMVC app for the most part. Think of Qwik's state more like a global store with Dependency Injection.
Qwik isn't doing HTML partials. It doesn't replace things from the server. I'm not sure where you got that idea from. It just hydrates out of order. So you could put a client side router on the page and not load it until someone clicks a link, yet before that happens do something interactive on the initial page. This is very applicable to SPAs. Now you could use Qwik with something like Turbo.
The "double data" problem is that technically the data gets serialized twice with hydration. Once in the HTML (ie your manifested view) and once as the data you bootstrap the framework with. I've seen experiments to extract the data back from the manifested view but that has big limitations, and it isn't what Qwik is doing. Their data in the HTML is just the data you may have serialized a different way and is still independent of the manifested DOM.
I was going to reply but, Ryan you are doing a great job, thank you.
Thanks for a good and candid response, as always, Ryan.
To complicate things a little bit further..
Compared to Turbo, you said:
I recently discovered Inertia.js. Which is like HOTwire Turbo (aka. Turbolinks) but sending JSON over the wire containing props data and the the name of the client side JS-component to inject it into. So that you could develop an SPA (using React/Vue/Svelte), with the same app mental model and DX, though also avoiding having an API. You get this by letting Inertia.js hot-swap components and data (props), and let the server take care of the routing. So it occupies this weird spot between an SPA and an MPA, since it, like Turbo, will "serve an MPA off a single page", as you said.
So Inertia uses client-side rendering (CSR/SPA) by default, and like Qwik is also saying "not everything needs to be rendered on the server". (Even though Inertia can even do SSR now.)
So how is Qwik different from Inertia.js?
To try to answer my own question:
I guess the main difference is that Qwik is able to Resume hydration of the initial HTML the server sends. While Inertia relies on React/Vue/Svelte to hydrate it by Replaying the application state on bootstrap / first page load.
So Qwik would have a faster initial Time-To-Interactive (TTI).
As you said:
So: partial page hydration.
But for subsequent interactions, then I guess it wouldn't be much of a difference. As Inertia doesn't do what NextJS SSR does. From what I understand, NextJS SSR serves a new page and then completely re-hydrates (replays) that page on the client, on every route change. (Unless using next-super-performance, which is a proof-of-concept that apparently does partial page hydration). Inertia, on the other hand, wouldn't need to re-hydrate (replay) components it swaps out, because it is responsible for rendering them in the first place.
It would be interesting to see an app that used Qwik with Inertia.js. It would, if my analysis is correct, speed up the initial page hydration, by allowing it to be SSR'ed and then simply Resumed on the client, allowing faster initial TTI. Inertia would then take over for subsequent page changes.
Feel free to correct me if I'm wrong anywhere.
On another note, @ryansolid:
It would also be really interesting if there existed a Inertia.js adapter for SolidJS.
The thing with Next and most SPAs is that they are fast after the fact because they render in the client. THe server only renders initially for the first load. The main awkward part of SPAs is that initial payload/hydration. You could make it work in MPA mode where it went back to the server but those frameworks don't optimize for that in general.
Now like we are seeing with React Server Components or Turbo there are cases where rendering partials on the server after the fact is beneficial, and in so those partials can also be partially hydrated. Which is interesting. But as soon as you have the ability to move this to the client the performance is better with client rendering. But there are other considerations here. I feel that thinking of this in a more microfrontend scope is where things like Turbo have more value. Or the fact that server rendering can save you from implementing an API.
But raw performance, client side rendering is probably going to win once you have the necessary JS in the browser. This is important. An impossible task on first load, but not so much after. You can of course do stupid things and cause waterfalls in the browser but just generally I see Turbo as a way to keep the MPA mentality going for client side routing. But other than the reasons I mentioned above SPA taking over is probably fine at that point. It's just harder to break things up in that manner.
So I'm still unclear where this goes. But there are a few things being overestimated right now. Lazy hydration just defers expense. You need to do it carefully. Like if a SPA did this and you clicked deep in the tree it would need to then load the whole page and hydrate, which would be terrible for the end user. Qwik avoids this by isolating the components hierarchically, whereas Marko today and Astro solve it by breaking off Islands. But naively implemented if you were to use Qwik in a SPA and you navigated since it suddenly finds itself needing to render everything in the browser it would be downloading a ton of small granular chunks that would have been better served as a single split bundle.
So if attacking this holistically I'd look at something in the middle where we can make the bundles large enough to not die by a 1000 slices but also defer work needed for hydration as needed. This is what we are doing with Marko and why we have a different focus. Because honestly while Turbo is probably good for the big stuff(page navigation) it sucks for the little stuff(small interactions). And might not even be needed for the big stuff if we do this properly except in those cases I was talking about.
We are also working on a streaming microfrontend setup with Marko that I guess could be Turbo-like but it's still something that you go to when you need it. But for now these are separate things and we are working on making Marko produce the smallest possible bundles and are in the process of implementing resumable hydration. Qwik is working towards it's similar goals. As is even Astro. I think we all acknowledge Turbo is a path but it's a bit longer term because there are so many gains to get already before going there and adding that complexity. Inertia.js is fine and all but I feel it is working from the assumption client frameworks have to be like Vue or React.. they don't.
I've always found the various approaches to reacting to data/state changes in JS frameworks rather over-engineered.
To me the ideal solution would be a
MutationObserverfor plain JS objects. Something that tells me (via callback) when, for example, an element was pushed on an array.Built-in reactivity on a data-level seems like a much more straight-forward (and probably easier to optimise) solution than a full re-render with subsequent DOM-diffing or Svelte's broken
update = () => state=state™ hackEDIT: To some extent, it is possible to approximate this behaviour in JavaScript using
Proxyobjects, which works just fine but comes with the downside of having to use Proxies of everything, because the plain object could still be changed without the proxy knowing.Even with this limitation though, I've found that this way of reacting to data changes is much easier to handle in plain JS and leads to way less weird shenanigans to convince a framework to really update.
Have you seen my library SolidJS? It's what I'm hinting at in the end about being more granular and diffing less. But it works as you mentioned more or less. I just don't want to always come in with the strong hand. But performance wise it is reasonably impressive.
Just wanted to say I think that SolidJS is fantastic work.
Very well written article, and kudos for staying in the middle on these discussions
At last a good article on dev.to, worth reading.
Not those kinds of "5 the best etc etc etc of 2021", or the "Top 10 ek ek ek of 2021"
JavaScript wins. Flawless victory. FATALITY