
Hydration is the name given to the process in JavaScript frameworks to initializing the page in the browser after it has previously been server rendered. While the server can produce the initial HTML we need to augment this output with event handlers and initialize our application state in a way that it can be interactive in the browser.
In most frameworks this process carries a pretty heavy cost when our page is first loading. Depending on how long it takes for JavaScript to load and for hydration to complete, we can be presenting a page that looks to be interactive but in reality isn't. This can be terrible for user experience and is especially felt on lower end devices and slower networks.
You'd think there would be a lot ways to address this. And there are. But none of them are foolproof. Library authors have been circling around this for years incrementally improving on techniques. So today, I thought we'd take a look at the topic of hydration specifically to best understand what we are dealing with.
Debunking Server Rendering as the Silver Bullet

So you've taken your favorite client rendering JavaScript Framework and now have it rendering on the server. Better SEO. Better performance. Best of both worlds.
... No. Let's stop you right there.
This is a common misconception. Simply server rendering your SPA doesn't suddenly fix everything. In fact, more than likely you've increased your JavaScript payload and may have even longer times until your application is interactive than when you were just client rendering.
What?!...
I'm not messing with you. Most frameworks hydration ready code is larger than their typical client code because ultimately it needs to do both things. It might only be hydrating at first but since your framework allows client side rendering it needs the code to do that as well.
And now instead of shipping our mostly blank HTML page immediately that might show some feedback to the user while it loads data, we need to wait for the whole page to load and render on the server, before we then run a process similar to rendering in the browser. That page is also a lot larger as it contains all our HTML and the data our application needs to bootstrap itself.
It's not all bad. Generally speaking your main content should be visible faster since you didn't have to wait for the browser to do an additional round trip to load the JavaScript before it got to work. But you also delayed the loading of assets, including the JavaScript needed to hydrate your app.
Note: This is highly dependent on consumer network and data latency. And there are many techniques to address this load performance timing like streaming. But I seek to illustrate this isn't a clear win and we have new tradeoffs and considerations.
The Fundamental Problem
When it comes to client side hydration there are two characteristics that are pretty unfortunate. One is we render on the server, and now we basically need to re-render it again in the browser to hydrate everything. The second is we tend to send everything across the wire twice. Once as HTML and once in JavaScript.
Generally it gets sent across in 3 forms:
- The Template - component code/static templates
- The Data - the data we use to fill our template
- The Realized View - the final HTML
The template views are both in your bundled JavaScript and rendered HTML, and the data is present both as usually a script tag rendered into the page and also in part in the final HTML.
With client rendering we just sent the template, and requested the data to render it. There is no duplication. However, we are at the mercy of the network loading the JavaScript bundle before we can show anything.
So having the realized HTML from the server is where we get all the benefits of server rendering. It lets us not be at the mercy of JavaScript loading times to display our site. But how do we combat the inherent extra overhead that comes from server rendering?
Static Routes (No Hydration)

Examples: Remix, SvelteKit, SolidStart
One idea that we've seen employed in a number of JS SSR frameworks is the ability to just remove the <script> tag on some pages. These pages are static and don't need the JavaScript. No JavaScript means no extra traffic over the network, no data serialization, and no hydration. Win.
Well of course unless you need JavaScript. You could sneak in some vanilla JavaScript on the page and maybe that'd be fine for somethings but this is far from desirable. You are basically creating a second app layer.
This is the no nonsense way to approach this though. But realistically once you add dynamic stuff and you want to leverage the framework you are pulling everything in. This approach is something we've always been able to do with SSR with pretty much every solution out there but it also isn't particularly flexible. It's a cool trick but it isn't really a solve for most things.
Lazy-loading the JavaScript (Progressive Hydration)

Examples: Astro(In combination w/ Islands)
This approach is what I refer to as "Progressive" or "Lazy" Hydration. It isn't saying we won't load the JavaScript. Just that won't load it immediately. Let's load it on interaction, whether click or hover or when things scroll into view. The extra benefit of this is if we never interact with part of the page maybe we never even send that JavaScript. But there's one catch.
Most JavaScript frameworks need to hydrate top-down. This is as true for React as it is for Svelte. So if your app contains a common root (as Single Page apps do) we need to load that. And unless our render tree is really shallow you may find that when you click that button half-way down the screen you needed to load and hydrate a huge amount of code anyway. Deferring the overhead until the user does something isn't really any better. It's probably worse since now it's a guarantee that you will be making them wait. But your site will have a better Lighthouse Score.
So maybe this might benefit apps that have wide and shallow trees but that isn't really the common case in your modern Single Page App(SPA). Our patterns around client side routing, Context Providers, and Boundary Components (Suspense, Error, or otherwise) have us building things deep.
This approach alone also can't do anything to save us from serializing all the data that could be used. We don't know what will eventually load so it all needs to be available.
Extracting Data from the HTML

Examples: Prism Compiler
The other thought that people usually have right away is maybe I can reverse engineer my state from the rendered HTML. Instead of sending a big JSON blob you would initialize the state from the values inserted in the HTML. It isn't a terrible idea on the surface. The challenge is model to view aren't always 1 to 1.
If you have derived data trying to get back to the original to re-derive is in many cases impossible. For example if you show a formatted timestamp in your HTML you might have not encoded the seconds but what do you do if another UI option allows you to change to a format that does.
Unfortunately this applies not only to state we initialize but data coming databases and APIs. And often it isn't as simple as not serializing the whole thing into the page. Remember most hydration runs the app again on initialization in the browser top-down. Isomorphic data fetching services will often try to refetch it again in the browser at this time if you don't send it and setup some sort of client side cache with the data.
Islands (Partial Hydration)

Picture a web page as mostly static HTML that doesn't need to be re-rendered or hydrated in the browser. Inside it there are the few places where a user can interact which we can refer to as our "Islands". This approach is often called Partial Hydration since we only need to hydrate those islands and can skip sending the JavaScript for anything else on the page.
With an app architected this way we only need to serialize the inputs or props to the top level components since we know nothing above them is stateful. We know 100% it can never re-render. That outside of the islands is incapable of change. In so we can solve a lot of the double data problem simply by never sending the data we don't use. If it isn't a top-level input there is no way it can be needed in the browser.
But where do we set the boundaries? Doing it at a component level is reasonable as it is something we as humans can make sense of. But the more granular the islands the more effective they are. When anything under an island can re-render you need to send that code to the browser.
One solution is developing a compiler smart enough to determine state at a subcomponent level. In so not only are static branches pruned from our tree but even ones nested under stateful components. But such a compiler would need a specialized Domain Specific Language(DSL) so that it could be analyzed in a cross module fashion.
More importantly, islands means server rendering each page on navigation. This multi-page (MPA) approach is the way the web classically works. But it means no client side transitions and loss of client state on navigation. Effectively, Partial Hydration is an improved version of our Static Routes above. One where you only pay for the features you use.
Out of Order Hydration

Examples: Qwik
If Partial Hydration is an updated version of our Static Routes, Out of Order Hydration is an improvement on Lazy Loading. What if we weren't restricted by the typical top-down rendering frameworks do to hydrate. It lets that button half way down the page hydrate independent of you loading the pile of client routing and state managers on the page above it in the component hierarchy.
This has a fairly hard restriction. For this to work the component must have everything it needs to operate initially without depending on its parent. But components have a direct relationship with their parents as expressed through their input or "props".
One solution is dependency injection to get all inputs in the respective components. The communication isn't direct between parent child. And on server render the inputs of all components can be serialized (deduped of course).
But this also applies to children being passed into our components. They need to be fully rendered ahead of time. Existing frameworks do not work this way for very good reason. Lazy evaluation gives the child the ability to control how and when children are inserted. Almost every framework that eager evaluated children at one point now does it lazily.
This makes this approach very different feeling to develop in as the rules of parent child interactions we are used to need to be orchestrated and restricted. And like lazy-loading this approach doesn't save us on data duplication since while it can hydrate fairly granularly it doesn't ever know which components actually need to be sent to the browser.
Server Components

Examples: React Server Components
What if you could take Partial Hydration but then re-render the static parts on the server? If you were to do that you'd have Server Components. You'd have a lot of the same benefits of Partial Hydration with the reduced component code size and the removal of duplicate data, but not give up maintaining client side state on navigation.
The challenge is that to re-render the static parts on the server you need specialized data format to be able to diff the existing HTML against it. You also need to maintain normal server HTML rendering for initial render. This means much more complicated build step and different sort of compilation and bundling between these server components and those client ones.
More so even if you've removed incremental overhead you need a larger runtime in the browser to make this work. So the complexity of this system probably doesn't offset the cost until you get to larger websites and apps. But when you have reached that threshold this feels like the sky is the limit. Maybe not the best approach for maximizing initial page loads but a unique way to preserve the benefits of SPAs without scaling your site to infinite JavaScript.
Conclusion
This is an area that is constantly being worked on so new techniques are constantly emerging. And the truth of the matter is the best solution might be a combination of different techniques.
What if we took a compiler that could automatically generate sub-component islands, could hydrate out of order, and supported server components? We'd have the best of all worlds, right?
Or maybe the tradeoffs would be too extreme that it wouldn't jive with people's mental model. Maybe the complexity of solution too extreme.
There are a lot of ways this can go. Hopefully now you have some more insight into the work that has been going on for the last few years to solve one of modern JavaScripts most challenging problems.

Top comments (35)
Whatever happens with Qwik in the long term, it added important new terminology—"replayable SSR" versus "resumable SSR".
I would go as far as saying that it identified the core limitation of contemporary client side frameworks—SSR reliant on "replayability" which is a consequence of their client side centric design (as opposed to a design that is distributed from the beginning).
Dynamic server rendering pretty much follows this pattern:
This pattern is pretty much guided by doing as much work as possible on the server to minimize the work needed on the client (and taking maximum advantage of the browser's built-in capabilities) which makes sense in a distributed environment where
Extending this to a distributed application leads to resumable server rendering:
The key here is that the "pre-rendered initial application state" isn't just "initial data" that needs to be "played out" inside the application but is the actual internal application state—so the application is ready to go once it's dropped in. Not only is the display shipped as pre-rendered HTML but also the application state is pre-rendered.
Now Qwik adds some other tricks like fragmenting interactivity to the smallest possible granularity in order to aggressively optimize TTI but the fundamental shift in thinking is moving from today's "replayable SSR" to tommorrow's "resumable SSR" (pre-rendered, joinable application state).
It's my sense that "resumable SSR" is going to force a major rethink in terms of client side application architecture (how it's partitioned) which may require significant tooling to get to the necessary level of DX that would ease its adoption.
If I remember correctly Qwik initially was trying to store application state in the HTML but I think they have abandoned that idea.
Yeah the reason I didn't focus too much on resumable hydration here is I don't think true resumable hydration exists yet. Qwik does succeed at doing out of order hydration in that you can hydrate the child before the parent. And with that partitioning it is possible to assume that data initializes with initial state from the server at a component level. You have the inputs and you have the outputs, so you can confidently just not do the re-render of that component in the browser at hydration time and only attach the event handlers, or any defined side effects.
However, the reason I don't consider this true resumable hydration is that when any data would update for this component it needs to re-run and redo unrelated work that may have already been done on the server. It's like the motivation for the React forget compiler example if you saw that.. if you have some state that has nothing to do with a list you are rendering and you update the state the list re-renders. This is unsurprising. Picture if that unrelated work triggered an async data request etc..
VDOM based solutions have some challenges with resumable hydration. Qwik's approach is more like skipping hydration and then doing the work when you interact with it. Resumable Hydration should be able to work not only skipping unnecessary hydration but be able to not redo computations and derivations in the browser after the fact when unrelated data changes. This is possible if you can slice up your component logic the other way more similar to the fine-grained graphs that Solid produces. And you are probably unsurprised to hear this is exactly what we are working on for Marko 6.
I am playing with Qwik right now and seeing just how effective their resumable approach is, because I do want to confirm my understanding is correct.
UPDATE: Talking to Misko and the team Qwik is already working on a solution for precisely the concern that I have. They have a runtime based reactive system similar to Solid and are serializing the dependencies at runtime on the server with some new primitives that resemble
useEffectanduseMemo. When this lands they should be able to do the type of fine-grained resumability I'm talking about.I had a most excellent chat with Ryan offline and wanted to share my thoughts here, which boil down to "Qwik is truely resumable." Maybe not right this moment, as we have a few more things to implement, but we have designs for all of these.
To be truly resumable, you need to have a few things:
If you don't have #3, then once the data changes, you don't have a choice but to re-render the whole app because you don't know which components are invalidated and need to be re-rendered. This forces you to download the whole app, and that is expensive.
But Qwik does know the answer to #3. Though Proxys Qwik knows which component cares about which data, Qwik serializes all of this information to the DOM. Then the data gets mutated Qwik can run
querySelectorAllon HTML, which will tell it which components are subscribed to the data and hence have to be re-rendered. This is significant because it allows most of the components to stay in their unhydrated state for the duration of the app's life.I think of this problem as layers in onion:
useEffectequivalent) (If you don't have that you will have to eagerly download code)On each of the levels, there are interesting problems to solve. Qwik's aim is to solve all of them, and so far, we have been able to do that and have plans for the reminder, which is consistent with Qwik's mental model.
This is why I think that Qwik is (will be) truly resumable.
I appreciate both yours & Ryan's work so this thread is gold. Thank you for listing out the hydration scenarios. Here is my concern as an app & library developer. I really like isomorphic JS & am building around that concept. Up till now isojs hydration has been a black box. Making the isojs hydration process more transparent & even programmable will be appreciated.
I would like to learn more about your plans re: step 4 & 5. Also, do you forsee Qwik or its concepts as being compatible with Solid & other isojs component libraries?
I love Misko's framing here as 4/5 are big part of what we are working on with Marko as well. 4 is a fairly natural extension of 3 in the same way Solid's granular reactivity is over say MobX + VDOM. The way to do this involves serializing the dependencies, then you don't need to run it once. In Marko's case it is a compiler that detects these similar to Svelte, except Marko's works cross file and traces dependencies even hoisted. For Qwik it's runtime similar to Solid, just that if it runs on the server you know the dependencies from the last run and can continue only when one updates. The way they serialize them is simply to take the key off their shared proxy store that all components use (that manages the Dependency injection).
I do want to talk to Misko more about this because there are different types of scenarios. Derivations definitely want to run on the server and be treated this way but effects in most frameworks are also a way to do client only code that you don't run on the server, like include a jQuery chart. In those cases you'd want the effect to run at hydration time so it isn't really a problem since you don't need it to run on the server to collect dependencies. In Marko we make that deliberation that it is effects and event handlers that run at hydration time. The interesting piece for Qwik is do they code split on this too putting the effects in with the event handlers and separate from the other component code.. once you follow this thinking Qwik may actually approach closer to how Marko 6 is breaking up code.
For Marko we actually split it from input/props through Reactive graph so a component consists of many different fine-grained pieces. Which is interesting since instead of things being component level the parent can know based on whether it passes static or reactive data to even import the dynamic child part to run it. And since we know exactly what can be stateful we can eliminate whole subtrees through the component structure.
I'm excited to talk more about this because the implications get pretty interesting. Because even when things are stateful instead of serializing everything we can optimize it further to serialize things based on the leaf nodes of the reactive graph. It's only things read from an DOM, event handler or effect directly that need to be serialized. With one except reactive convergences need each source branch serialized as well so one side can update without needing to run again. In a sense I've shown how Marko today can only serialize data that is used in components based on what is passed in to top level components input/props. With this approach we'd get field level serialization of only what is actually used/usable. Because of convergence we know that and in other cases we know that it would be impossible change what data we are seeing without refetching (ie triggering an async source) so we can be confident we don't need to have it in the browser initially.
Of course this all comes down to what is serializable. I'm interested to learn more about Qwiks approach. With Marko since the compiler sets the boundaries we can always step up one level with serialization if it isn't serializable as long as all root sources are. But we are working on techniques to serialize typically unserializable things like promises or functions and closures.
I think it just did, with Qwik 1.0 just having been released recently.
Given your article's introduction the characterization of "replayable hydration" (for the current state of SSR) versus the hypothetical ideal of "resumable hydration" seemed useful.
No we have not abandoned it all. We have just moved it to the bottom of HTML for several reasons:
Sorry, I should have been more precise. Back in August
Qwik: the answer to optimal fine-grained lazy loading
Miško Hevery for Builder.io ・ Aug 2 '21 ・ 7 min read
the state seemed to be stored directly in HTML element attributes.
By December it consolidated into a
qwik/jsonscript block containing "flattened JSON with reference keys" (with some reference keys being used as HTML element attribute values).Yes that is correct, we have moved it to a consolidated place.
I'm having trouble understanding the difference between 'initial state' vs 'actual internal application state'. If the point is to have the app take over once the initial app is rendered on the client, then isn't initial state, the only state there is? Can you give an example of a difference?
From Static to Interactive: Why Resumability is the Best Alternative to Hydration and Hydration is Pure Overhead get into this in detail.
Perhaps replace “initial state” with “initial data”.
Hydration:
Resumability:
I love how you pointed out that lighthouse scores can be meaningless. UX can still suffer despite a perfect score.
I'm assuming this article started from this thread? twitter.com/RyanCarniato/status/14...
I can see why you'd think that. It isn't unrelated. I sort of knew that the Remix guys were going to attempt to downplay partial hydration again. It isn't the first time. Expect the same for Streaming, or any other technology that doesn't start and end with React before React 18. So this seems timely but it's more I was prepared.
I think the biggest thing here is to have the language to talk about the work people have been doing. Whether or not I can convince someone of the merits of techniques developed by companies working at the largest scale is besides the point. After all it might not be worth any of the tradeoffs for someone's given app. But best know what those are.
We have people working on solutions in this space for years and there are slight differences in how everyone attacks the problem. The best way to cut through this is at least have the frame of reference to talk about these things.
This is a weird comment that assumes a lot about us?
I'm not trying to downplay anything. I'm genuinely interested in partial hydration, been anticipating doing it ourselves in Remix since the beginning. But we've gotten so far with progressive enhancement I'm now not sure there's much to improve, so I'm just looking for a well-designed demo that shows it beats PE before I go mess around with it.
Nobody has one, I hope they do soon.
Thanks for your concerns Ryan. I'm a bit annoyed by the situation and I let that show. We can talk some more about this in private. I have nothing but love for Remix.
@ryansolid Here’s a crazy idea:
Progressive Eager Hydration - with JavaScript streaming and execution by way of HTML streaming.
The goal is to make partial pages interactive asap, so the user can interact above-the-fold immediately (while the rest of the page is also made interactive asap, without the disadvantage of laziness: surprise stall on user interaction).
Could JavaScript be streamed in, in parallel with the HTML, and then progressively but eagerly hydrated (top down) incrementally, as the HTML is streaming in?
I imagine rendering would could go in progressive lock-step (after the HTML and JS streams in parallel): render some HTML -> hydrate corresponding JS component -> render some more HTML -> hydrate corresponding JS component -> … etc.
The framework would need to inject intermittent script tags in the HTML, in a very finely grained manner. Since heavy operations inside a component would block the rendering. Devs would also immediately get aware of slowdowns and optimise above-the-fold components. All so that the JS can be executed during streaming before the entire page is loaded:
Run JS before all HTML has loaded
Maybe this would be more line with the original vision of the web (before we collectively decided to put all JS inside a single script tag at the bottom of the HTML).
This is how Marko works with in order streaming. In a sense it is how Solid and React's out of order streaming works. Not necessarily splitting it above the fold, but rather based on async data. Now making it work above the fold isn't that far from how things like Astro work with intersection obvserver. I think eager generally is good if it isn't blocking. React has termed "Selective Hydration" as this approach.
All that being said Resumability may be just better than all of this because then the code never needs to run. I think the conversation with Qwik gets too often pulled into the lazy loading story. That isn't the important part for a lot of things. Hard to do less work than eliminating Hydration.
Maybe you could even offload Hydration to a separate thread (web worker) that runs in parallel with the HTML being streamed in.
github.com/BuilderIO/partytown
An initial script tag at the top of the page could set the JS framework off on a separate worker thread, and the framework would need to take in (or listen to) the HTML/DOM as it becomes available, and then hydrate it incrementally. Not sure how wise it is to rely on support for web workers, though.
Maybe.. but I think we can just do better doing less work still. Party town is cool because what it does is super low priority, no one is waiting on it. But using a worker like this much slower for working with the DOM. Solutions are getting too fancy with deferring when we should just be focusing on doing less work. Resumable Hydration is great, Partial is great at mitigating it. Progressive has its usage but is very overrated.
FFR, adding a small code example with preview of the basis of this idea. When loading this HTML, the JS executes synchronously in between the rendering of each section of HTML:
hey @adrienpoly @marcoroth this approach could maybe be used with StimulusJS to make the page interactive faster, while the HTML and JS are being streamed in. You could have Rails interleave Stimulus controllers in JS script tags in the HTML immediately after the HTML tags with the corresponding data-controller attribute (you could even mark the script tag async, to progressively load it from the server and it will «hydrate» and make the HTML interactive asap). So the user doesn’t have to wait until all the JS is downloaded to start interacting (above the fold, for instance). Not sure if this is what Rails with Stimulus already does though…
I think I'm missing the benefit in taking on the complexity of partial hydration when you still have dynamic parts that will need to access data from the server regardless of when they are hydrated. Fewer round-trips to the server is better, right? Is this complexity just to reduce the initial JavaScript size delivered to the client?
Are there examples in the wild of partial hydration in a complex app that can be used to compare against SSR + hydration, like we saw from remix with the ecommerce demos?
While all great ideas on paper, I think this is missing some substance to back up the claims against the tried and true champion: SSR.
I do think you are missing something. The article might be worth a re-read. This is all SSR and doesn't introduce more round trips. If you mean that MPAs do a full page reload sure but keep in mind you are hitting the server already in these scenarios. But you are correct initial page load is a big part of it.
Unfortunately where you see this employed the most is huge eCommerce. Those sites are also plagued by 3rd party scripts and ads. We develop independent of them and since introducing Marko at ebay.com in 2013 we haven't been allowed to let any degradation in performance come from the numbers we doing in Java + jQuery before then.
It's not just ebay. Amazon has similar concerns:
In fact most large companies have a version of this when you consider internal framework Wiz from google and the investment React has been making into server components.
I can show some size comparisons from ebay.com between sizes of partial (component) and full hydration. It doesn't take much to do a little math to see the impact.
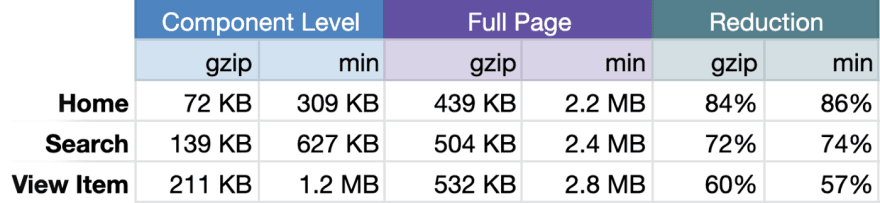
I know the hackernews demos are pretty poor in that they are mostly uninteractive so removing the script tags almost does the same thing. But even then you can already see the benefit. In fact in the original version of the Remix vs Next article Remix did exactly that so it isn't unlike the creators are naive to the benefits here.
But it goes beyond just code size but serialization savings. I just went on hackernews and found a story with an absurd amount of comments. Look at the difference between Marko and Remix anyway way you choose. I made essentially identical versions of this demo:
Remix: remix-hackernews.ryansolid.workers...
Marko: hn.markojs.workers.dev/story/30186326
Notice the difference streaming and partial hydration make here. I can keep churning out examples but it takes time.
This is much more clear to me now, thank you. The issue isn't SSR itself, the issue is the hydration strategy after server rendering. The first few paragraphs seem almost like an attack on SSR, so I was confused why you'd be discussing concepts that build on top of SSR.
You've got a 👍 from me.
Yeah I felt it necessary to knock the "l'm doing SSR in my SPA so I'm good" mentality down a couple pegs in order to help reset expectations for broader look at the topic. To me this is hardly a done topic. There are so many ways to make it better.
So I'm really excited about all the technology in this area. Remix and Sveltekit improves on Next. We're all moving forward. I think its important to view our efforts at like a 2-3/10 right now instead of the 9/10 people are sort of picturing. I think this area is pushing our mental model of what the best architectures are and how they apply to different use cases. Honestly I'm not sure there is a clear direction with both things like React Server Components and Qwik showing us what is possible with really different models. Or how Marko continues to show that these techniques can be done automatically and more optimal than a human would practically write the code.
Programmable hydration (e.g. jQuery, Alpine.js) is another strategy which has been used by MPA libraries like Ruby on Rails. The isomorphic rendering JS libraries eschewed this path but it may be worth revisiting now.
This would achieve programmable hydration & reduce payload size & reducing double data at the cost of imperatively managing the behavior injection. It could facilitate a custom Islands, Server Component, or lazy behavior injection implementation.
It may not be as ergonomic as Islands/Server Components but it can be improved with hydration libraries/hooks, compilation, & asset servers (Vite), tools which were not available or were only available in limited ways (ASP.NET) when the initial push to create isomorphic rendering libraries occurred.
I personally went all in on isomorphic rendering but perhaps behavior injection could be augmented with isomorphic rendering, compiled templates, & asset servers to take advantage of programmability in hydration while mitigating the complexity of the 2 layered app.
I implement rehydration by leveraging the different steps for building a document:
When browser history changes, depending on what part in the location changes, following steps are replayed.
If the document becomes visible, paint phase is replayed.
If the document is hidden, paint/hash phases are not run, this is the SSR case (unless rendering to a PDF, in which case the document is "visible").
The built document just has to carry at which step it is sent to the client:
When browsing, a change in query just replays query/paint/hash, not pathname step.
Custom elements help a lot in this picture.
Maybe using Laravel + React but GoLang + AlpineJS beats JS hydration out of the water
Are there any benchmarks comparing Go + AlpineJS vs PWA vs various JS library hydration solutions?
Yeah depends on what we are testing. Like most of these test the speed of a single response to line it up with the hydration expectations. In those scenarios the response time between these backends is probably not going to make a huge difference because the cost of network and browser costs way outweigh a handful of milliseconds on the server. I wouldn't be surprised that a light JS layer on top of pre-rendered HTML would perform well.. Alpine itself I'm not sure as it often is larger than other dedicated JS Frameworks and benchmarks pretty poor on performance. But simply it being so granularly applied probably still makes a it a good choice over like a giant React app.
This isn't so much about whether you can just use some vanillaJS to add interactivity. You most definitely can. Mind you it's like layering 2 apps on top if each other. This is about looking at how you can build it all as a single app experience which I think has more interesting implications. Especially when trying to scale the complexity of these systems from simple site to interactive app all with a single development experience.
stressgrid.com/blog/webserver_benc...
Here is a benchmark of the underlying language servers
It would be interesting to see a benchmark with the server & client TTL. AlpineJS does not score well on the Krausest benchmarks. There are not many hydration benchmarks as well.
krausest.github.io/js-framework-be...
indepth.dev/posts/1324/the-journey...
github.com/marko-js/isomorphic-ui-...
I think that there is no single ideal solution for different use cases and the future will show frameworks that allow developers to control the process in a sensible way to succeed where frameworks that try to take the cognitive load off the developers will fail in many cases.
A web shop will need a completely different hydration solution from that of a complex web app; unless the result is faster and more maintainable than hand crafted HTML with jQuery (e.g. amazon.com), it won't be winning.
A complex web app reliant on lots of JS on the other hand will likely rather have only its skeleton, noscript message and SEO data pre-rendered and rely on a mix of hydration and client-side rendering.
Control is key. If I can switch between different modes within the same root component just by dropping or removing a few flow components, and have conditions at hand to use in the state logic, that's a definite win; one could easily a/b-test different solutions for different use cases to get the maximum possible performance without spending days of work.