Hey fellow developers!
I've been recently running Hyde, a privacy-tech company, as a co-founder and CTO of it for a little shy of a year.
I feel that OAuth's conception of "scope" should be richer. Right now, there's nothing that prevents OAuth clients from breaking their promises they made in Authorization screens. Not just in practice but in terms of RFC 6749, scopes simply convey a set of kinds of resources authorized, not how they could or couldn't be used.
I don't think this is a problem of OAuth as it's based on the assumption that, in the first place, you can trust OAuth clients in a degree at which they wouldn't break the promises they themselves made. Like, as long as OAuth clients are somewhat famous enterprises, it would critically harm them if they break the promises they made against their customers.
At the same time, it's obvious for savvy people like ones in this community, that there's a bunch of malicious actors who would intentionally break those promises, and it's not easy to distinguish those shady agencies from indie hackers who actually do really interesting works.
In such a context, I've came up with an idea where you would be able to audit, in advance, what computation would happen on your data. I believe this could be established on open standards out there, but for this time, to prove the concept myself right now, I've built PoC tool for both.
So I made a Form Builder like Typeform where nobody can see answers in clear text.
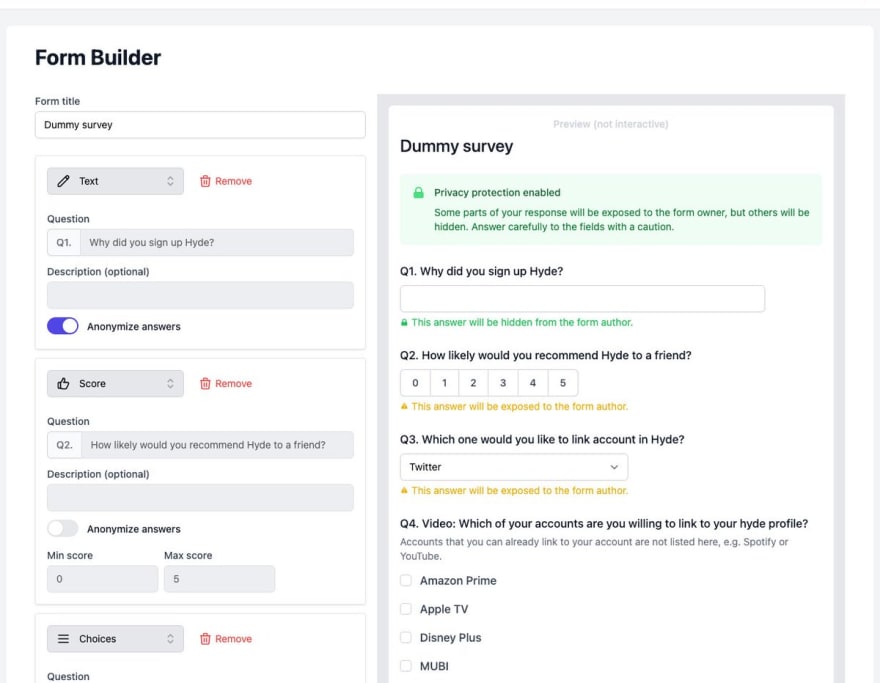 I made a Form Builder like Typeform where nobody can see answers in clear text!
I made a Form Builder like Typeform where nobody can see answers in clear text!
It works like typical form builders on the surface, but unlike, you wouldn't read responses even if you're the owner. You'll see these instead (what is the use of it? will cover later in thread :)11:18 AM - 09 Aug 2022




It works like typical form builders on the surface, but unlike them, you wouldn't be able read responses from participants even if you're the owner.
I propose two ways to work with those data kept secret.
First one is UI with visualization but as only vector embeddings, not raw data. Vector embeddings keep characteristic in terms of the operations on elements in the set. You would get the idea roughly by referring several word2vec explanations out there.
In nutshell, vector embedding preserve the relations between elements in a set while it compresses (in other words, anonymize in this context) by mapping them onto another set. For instance, if you get an idea of adding like King + Female = Queen, then you would construct an embedding in which (king.x, king.y, king.z) + (female.x, female.y, female.z) = (queen.x, queen.y, queen.z). This allows you to execute certain class of computation being unaware of actual words i.e. sensitive information in this context. Caveats are that this also requires you, the application programmer here, to understand what the embeddings are and how you would operate on them.
Second one is something perhaps a little overloaded in terms of architecture, but simpler to work with. To access the data, you need to make a Docker image. The image will be executed on our end, with JSON files of responses mounted there. Here, you would be able to process the responses in clear text. And it would be supposed to write results to a specific file, from which we would read and provide you via API. Since they (hopefully including you!) can code on them as usual, unlike on the embeddings discussed above.
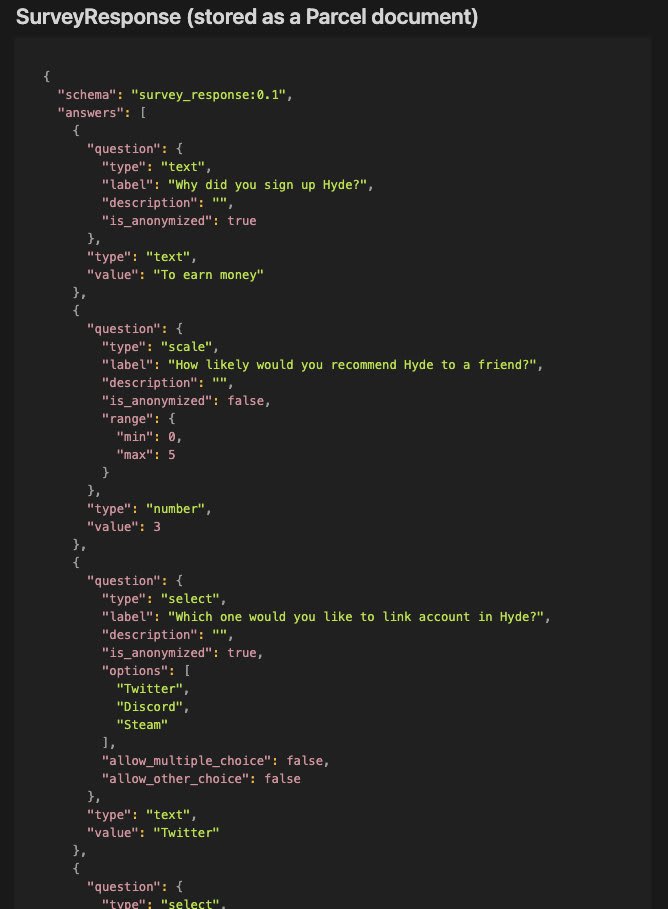 To access the data, you need to have a Docker image. The image will be executed on our end, with JSON files of responses mounted there. It would be supposed to write results to a specific file, from which we would read and provide you via API.11:18 AM - 09 Aug 2022
To access the data, you need to have a Docker image. The image will be executed on our end, with JSON files of responses mounted there. It would be supposed to write results to a specific file, from which we would read and provide you via API.11:18 AM - 09 Aug 2022
Tutorial and API reference is available here
Any feedback would be warmly appreciated :)
As a next story, I envisage to integrate this on top of OAuth or GNAP; Either by adding a scope/access.actions with specific semantics or returning results in place of tokens. Since GNAP has async mechanism in nature it would fit better.

Top comments (0)