Support me on (Patreon)[https://www.patreon.com/tonywang_dev] to write more tutorials like this!
Introduction
In the previous post, we covered the process of analyzing the network panel of a webpage to identify the relevant RESTful API for scraping desired data. While this approach works for many websites, some implement techniques like JavaScript encryption, which makes it difficult to decrypt and extract valuable information solely through RESTful APIs. This is where the concept of a “headless browser” can enable us to simulate the actions of a real user browsing the website with a browser.
A headless browser is essentially a web browser without a graphical user interface (GUI). It allows automated web browsing and page interaction, providing a means to access and extract information from websites that employ dynamic content and JavaScript encryption. By using a headless browser, we can overcome some of the challenges posed by traditional scraping methods, as it allows us to execute JavaScript, render web pages, and access dynamically generated content.
Here I will demonstrate the process of creating a distributed crawler using a headless browser, using Google Maps as our target website.
Throughout my experience, I have explored various headless browser frameworks, such as Selenium, Puppeteer, Playwright, and Chromedp. Among them, I believe that Crawlee stands out as the most powerful tool I have ever used for web scraping purposes. Crawlee is a JavaScript-based library, which means you can easily adapt it to work with other frameworks of your choice, making it highly versatile and flexible for different project requirements.
How to list all the businesses in a country
In general, when using Google Maps to find businesses we want to visit, we typically conduct searches based on the business category type and location. For instance, we may use a keyword like “shop near Holtsville” to locate any shops in a small town in New York. However, a challenge arises when multiple towns share the same name within the same country. To overcome this, Google Maps offers a helpful feature: querying by postal code. Consequently, the initial query can be refined to “shop near 00501,” with 00501 being the postal code of a specific location in Holtsville. This approach provides greater clarity and reduces confusion compared to using town names.
With this clear path for efficient searches, our next objective is to compile a comprehensive list of all postal codes in the USA. To accomplish this, I used a free postal code database accessible here. If you happen to know of a better database, leave a comment below.
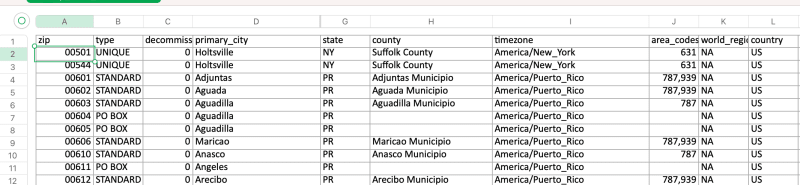
Once we have downloaded the postal code list file, we can begin testing its functionality on Google Maps.
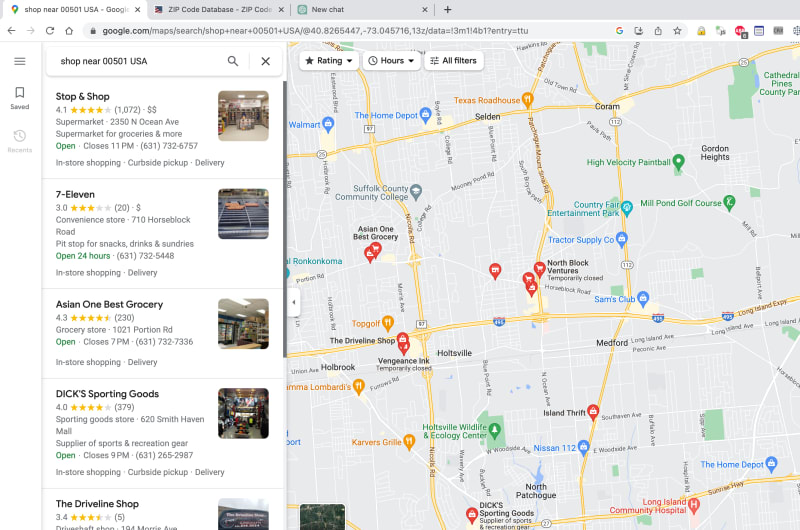
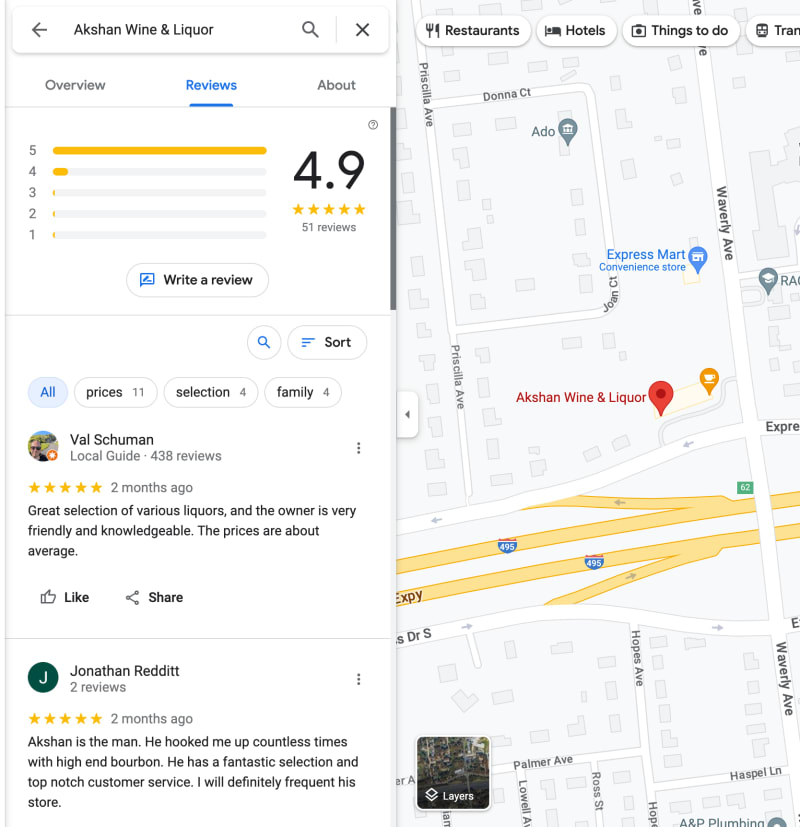
Using the keyword shop near 00501 USA in the Google Map search bar, we can observe a list of shops located in Holtsville. As our aim is to scrape all the businesses from this search, it is essential to ensure we retrieve a comprehensive list. To achieve this, we must scroll down through the search results until we reach the bottom of the list. Upon reaching the end, Google Maps will display a clear message stating You’ve reached the end of the list. This indicator serves as our cue to conclude the scrolling process and move on to the next phase of data extraction. By doing so, we can be certain that we have gathered all the relevant businesses from the specified location, enabling us to proceed with the scraping procedure accurately and comprehensively.

Once we have compiled the list of businesses from Google Maps, we can proceed to extract the detailed information we need from each business entry. This process involves going through the list one by one and scraping relevant data, such as the business’s address, operating hours, phone number, star ratings, number of reviews, and all available reviews.
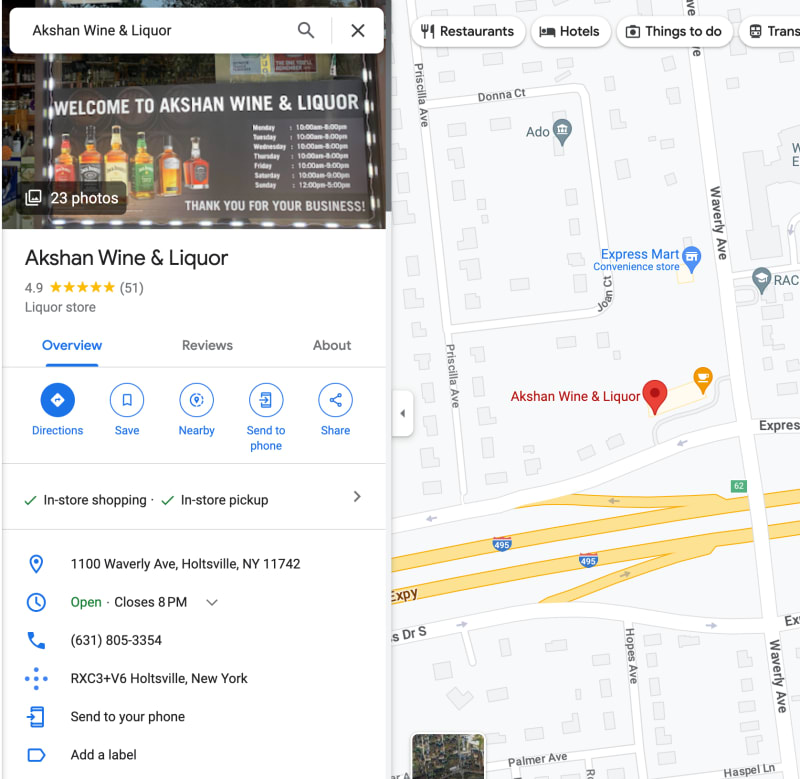
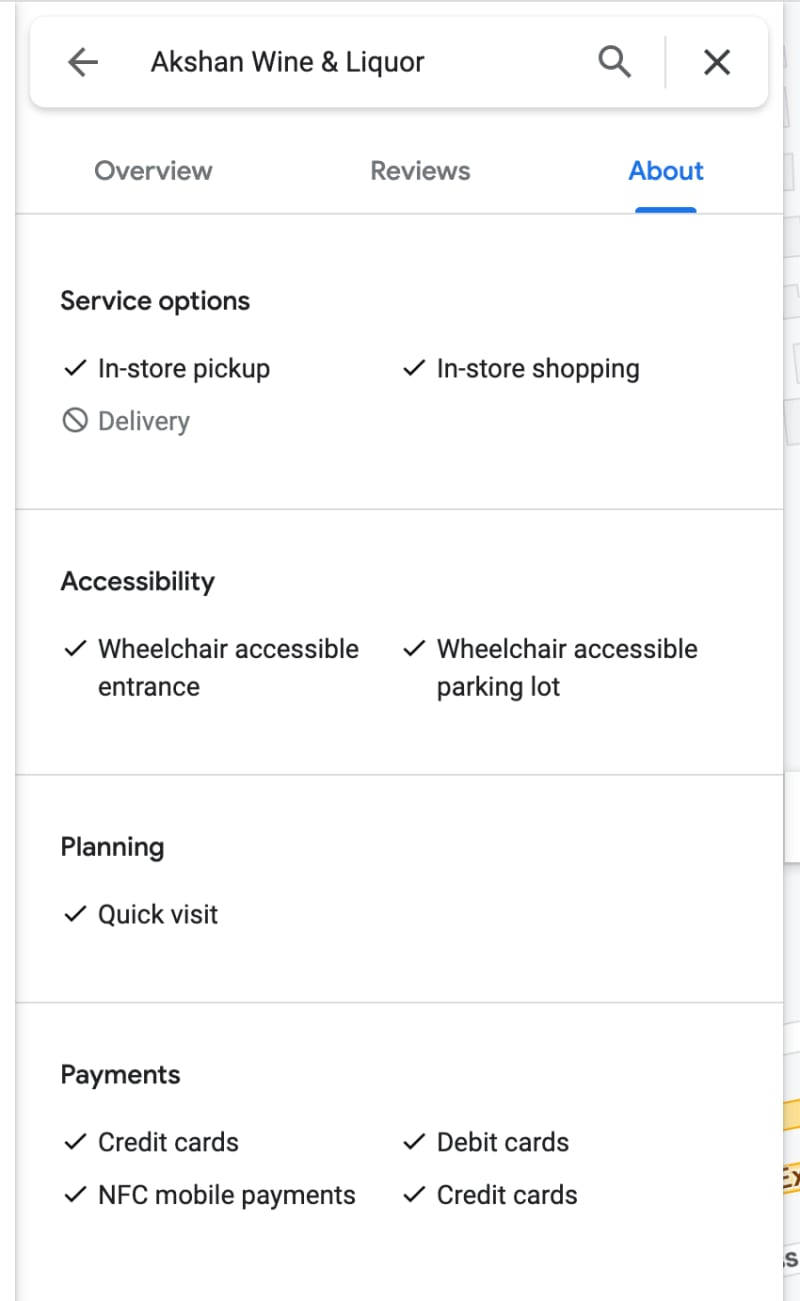
Implementing the code of Google Map scraper
-
Google Map Businesses scraper
The provided source code mainly focuses on extracting information from Google Maps using CSS selectors, which is relatively straightforward. As spot instances can be terminated at any time, it is essential to handle this situation carefully.
To solve this issue, we need to implement code that listens for the SIGTERM and SIGINT events. These events indicate that the instance is about to be terminated. When these events are triggered, we should take appropriate actions to backup any pending tasks in the job queue and also preserve the state of any running tasks that haven’t been completed yet.
By listening to these signals, we can intercept the termination process and ensure that critical data and tasks are not lost. The backup mechanism enables us to store any unfinished work safely, allowing for a seamless continuation of tasks when new instances are launched in the future.
['SIGINT', 'SIGTERM', "uncaughtException"].forEach(signal => process.on(signal, async () => {
await backupRequestQueue(queue, store, signal)
await crawler.teardown()
await sleep(200)
process.exit(1)
}))
2. Google Map Business Detail Scraper
3. Deployment file for Kubernetes
Monitoring and Optimizing the performance
As of now, everything with Crawlee appears to be functioning well, except for one critical issue. After running in the Kubernetes (k8s) cluster for approximately one hour, the performance of Crawlee experiences a significant drop, resulting in the extraction of only a few hundred items per hour, whereas initially, it was extracting at a much higher rate. Interestingly, this issue is not encountered when using a standalone container with Docker Compose on a dedicated machine.
Moreover, while monitoring the cluster, you may observe a drastic decrease in CPU utilization from around 90% to merely 10%, especially if you have the metric-server installed. This unexpected behavior is concerning and requires investigation to identify the underlying cause.
To address this performance degradation and ensure efficient resource utilization, you have taken the initiative to leverage the Kubernetes API and client-go, the Golang SDK for Kubernetes. By utilizing these tools, you can effectively monitor the CPU utilization of all instances in the cluster. To further mitigate this issue, you have implemented a solution to automatically terminate instances that exhibit very low CPU utilization and have been active for at least 30 minutes.
By automatically terminating such instances, you can avoid inefficiencies in resource allocation and ensure that underperforming instances do not hamper the overall data extraction process. This proactive approach helps maintain the cluster’s performance and ensures that Crawlee operates optimally, delivering consistent and reliable results even in the dynamic and challenging Kubernetes environment.
the provided code aims to address the issue of low CPU utilization in Kubernetes nodes by utilizing the Kubernetes metrics API to filter out underperforming nodes. Subsequently, the instance termination process is executed through the AWS Go SDK.
To ensure the successful implementation of this solution in a Kubernetes (k8s) cluster, additional steps are required. Specifically, we need to create a ServiceAccount, ClusterRole, and ClusterRoleBinding to properly assign the necessary permissions to the nodes-cleanup-cron-task. These permissions are essential for the task to effectively query the relevant Kubernetes resources and perform the required actions.
The ServiceAccount is responsible for providing an identity to the nodes-cleanup-cron-task, allowing it to authenticate with the Kubernetes API server. The ClusterRole defines a set of permissions that the task requires to interact with the necessary resources, in this case, the metrics API and other Kubernetes objects. Finally, the ClusterRoleBinding connects the ServiceAccount and ClusterRole, granting the task the permissions specified in the ClusterRole.
By establishing this set of permissions and associations, we ensure that the nodes-cleanup-cron-task can access and query the metrics API and other Kubernetes resources, effectively identifying nodes with low CPU utilization and terminating instances using the AWS Go SDK.
Conclusion
At this stage, the majority of the code is complete, and you have the capability to deploy it on any cloud server with Kubernetes (k8s). This flexibility allows you to scale the application effortlessly, expanding the number of instances as needed to meet your specific requirements.
One of the key advantages of the design lies in its termination tolerance. With the implemented safeguards to handle SIGTERM and SIGINT events, you can deploy spot instances without concerns about potential data loss. Even when spot instances are terminated unexpectedly, the application gracefully manages the data in the job queue and running tasks.
By leveraging this termination tolerance feature, the application can handle spot instance terminations smoothly. This ensures that any pending tasks in the job queue are backed up safely and that the state of running tasks, which haven’t completed yet, is preserved. Consequently, you can rest assured that the integrity of your data and tasks will be maintained throughout the operation.
Deploying the application with Kubernetes and taking advantage of termination tolerance empowers you to scale the Google Maps scraper efficiently, managing numerous instances to meet your data extraction needs effectively. The combination of Kubernetes and the termination tolerance design enhances the overall robustness and reliability of the application, allowing for seamless operation even in the dynamic and unpredictable cloud environment. If you have any questions regarding this article or any suggestions for future articles, please leave a comment below. Additionally, I am available for remote work or contracts, so please feel free to reach out to me via email.

Top comments (0)