
Data engineering is one of the fastest rising Data Science job roles. It is the foundation for big data. Data engineers are also known as information architects.
Information engineering (IE), also known as data engineering, information technology engineering (ITE) or information engineering methodology (IEM), refers to the building of systems to enable the collection and usage of data. This data is usually used to enable subsequent analysis and data science; which often involves machine learning.Making the data usable usually involves substantial compute and storage, as well as data processing and cleaning.-Wikipedia
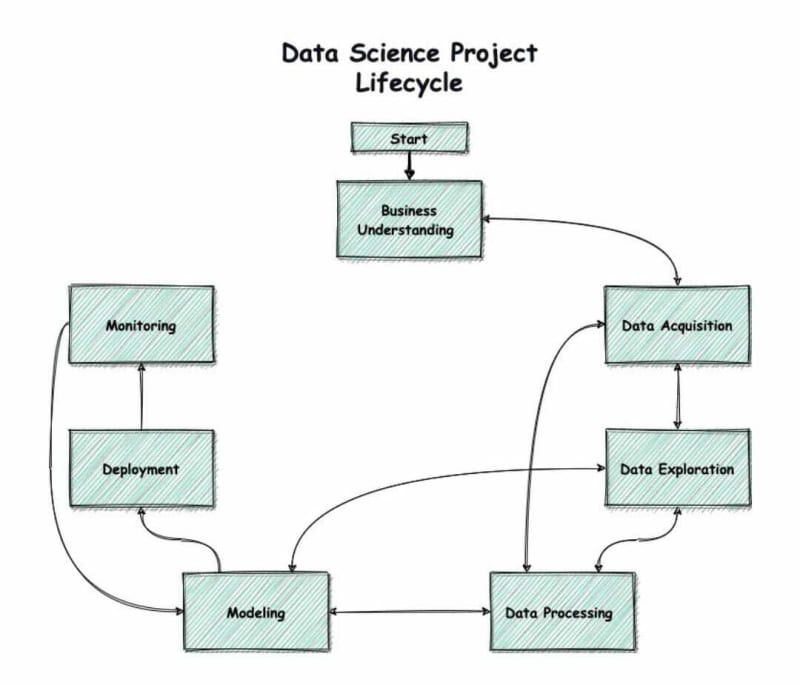
This article introduces the reader to basics they should know in order to get started with data engineering. It is a continuation of my previous article getting started in data science
Objectives
What is data engineering?
Data engineering and big data.
Data Engineers VS Data Scientists.
Data pipelines.
How to move and process data.
What is data engineering?
Data engineering refers to the building of systems to enable the collection and usage of data.
A data engineer's primary job is to prepare data for analytical or operations. They are responsible for building data pipelines to bring together information from different sources.
In the Data Science workflow, Data Engineers are responsible for data preparation, collection and storage.
Responsibilities of a data engineer
Ingesting data from different sources.
Optimizing databases for analysis.
Removing corrupted data.
They develop, construct, test and maintain data architectures.
BIG DATA
This is large volume of data that is difficult to process using traditional management methods.
The five V's of big data
Volume- The amount of data. How much?
Variety- The types of data. What kind?
Velocity- The rate at which data is received. How frequent?
Veracity- How truthful your data is. How accurate?
Value- How useful?
Data Engineers VS Data Scientists
Data Engineers collect and store data, Data Scientists exploit the data.
Data Engineers set up databases, Data Scientists access the databases.
Data Engineers build data pipelines, Data Scientists use pipeline outputs.
Data Engineers have strong software skills, Data Scientists have strong analytical skills.
Data Pipelines
A data pipeline is a series of data processing steps: Ingest ->Process ->Store.
Data pipelines automate data flow from one station to the next so that Data Scientists can use up-to-date, accurate and relevant data.
They ensure efficient flow of data.
ETL and Data Pipelines
ETL is a popular framework for designing data pipelines.
E-Extract data
T-Transform extracted data.
L-Load transformed data to another database.
Processing Data
Processing data refers to converting raw data into meaningful information.
Importance of procesing data
a. It helps to convert data from one type to another.
b. It helps to remove unwanted data.
c. It helps to organise data.
d. It helps to optimize memory, process and network costs.
e. It helps to fit data into a structure.
f. It increases productivity.
How data engineers process data
Data manipulation, cleaning and tidying.
Storing data in a sanely structured database.
Creating views on top of the database tables.
Optimizing performance of the database.
Links to other resources
What a Data Engineer does Coursera article
Becoming a data engineer article by datacamp
What do Data Engineers actually do?
Data Engineering Road Map

Top comments (0)