Traindex is a semantic search engine for corporate datasets to retrieve the most relevant results from a corpus. This search not only incorporates the meaning of the words but also includes contextual awareness. It enables a semantic search engine to outperform any keyword search engine; to find more, you can head out to our detailed article about the difference between both these approaches.
Traindex performance is measured using a variety of benchmarks, ranging from automated algorithms to manual experts' classification. For instance, we are using the Jaccard Similarity, which counts how many words from the retrieved results match the query's keywords. The following graph illustrates the visual intuition of this benchmark:
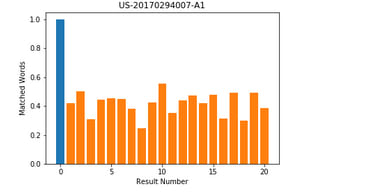
The blue bar represents the query's keywords, whereas the orange bars represent the matched keywords. The higher the bar, the more keywords in common.
In general, the benchmarking queries contain around 1200+ unique words. We have achieved a 47% average Jaccard Similarity score for the first twenty results against each query in our latest API release. This score means that we are implicitly applying the keyword search over the corpus since it approves that on average, Traindex could retrieve 564 common keywords with the query, which is far more than any keyword search engine can offer.
Moreover, the common words are not just random words because they are meticulously picked by an algorithm that decides about the query's best representative. The same algorithm also incorporates their semantic meaning during the search, which leads the percentage of Jaccard Similarity score sometimes to raise up to 90% and 99%.
When it comes to response time, Traindex is fairly quick. You can imagine how much time it would take to perform a keyword search of 564 words on 8.5M+ documents. It will require a lot of time and resources to go through the entire corpus, match the keywords, and bring up the relevant results. However, Traindex searches and ranks the results by their semantic similarity and not by the highest keyword match, as you can see from the above figure.
Conclusion
Traindex could give you the best of both worlds: keyword search and semantic search. Keyword search over millions of documents will take a long processing time and too many resources and produce a lot of false positives. Traindex, on the other hand, permits you to do a query with an entire document with even tens of thousands of words, and still, the response time is quick, and results are quite relevant.

Top comments (0)