
With great enthusiasm and excitement, I am writing my first post on the dev.to platform. My posts will mostly cover cloud-native data management and cloud-native Chaos Engineering: sometimes on existing technology and sometimes on future thoughts. I started my Kubernetes journey four years ago when I pivoted from closed source to open source as a platform to build future technologies. Having co-created two open-source projects OpenEBS and LitmusChaos, now I can only say that the choice was the right one, and a brilliant one.
Open source is the vehicle or platform for innovation. Kubernetes is the most recent example. We, at MayaData, started solving issues around data management for Kubernetes in 2017 and quickly realized that there is a common issue that needs to be resolved amongst all Kubernetes applications i.e., How to realize the promise of Kubernetes - the agility of DevOps? Developers/SREs have understood the advantages of Kubernetes and are moving to microservices at an unprecedented rate. They need a framework or toolset to help them make the transition to microservices quickly and keep the resilience of the final deployment at acceptable levels. The choice of the framework needs to be architecturally a correct one.
What's the answer?
The answer is - adopt "Chaos Engineering" from the beginning and as a first principle.
“Chaos First” principle
There is so much written about Chaos Engineering in recent times. But one thing that stuck out to me is the following from Adrian Cockroft.

“Chaos first” is a great strategy for cloud-native teams in order to achieve resilience when your deployment scales up.
Chaos Engineering has been the answer to achieving greater reliability in production systems. The cloud-native ecosystem has to adopt this discipline more so because of the dynamism inside the components and the sheer number of components itself. Most importantly they are all loosely coupled, which is a requirement for microservices architecture. I had recently written an article at CNCF blog platform around the principles and want to write them here again in my first post.
What is Cloud-Native Chaos Engineering?
It is Chaos Engineering done in a cloud-native way or Kubernetes-way. Here are the four principles that define how cloud-native your Chaos Engineering framework or practice is.
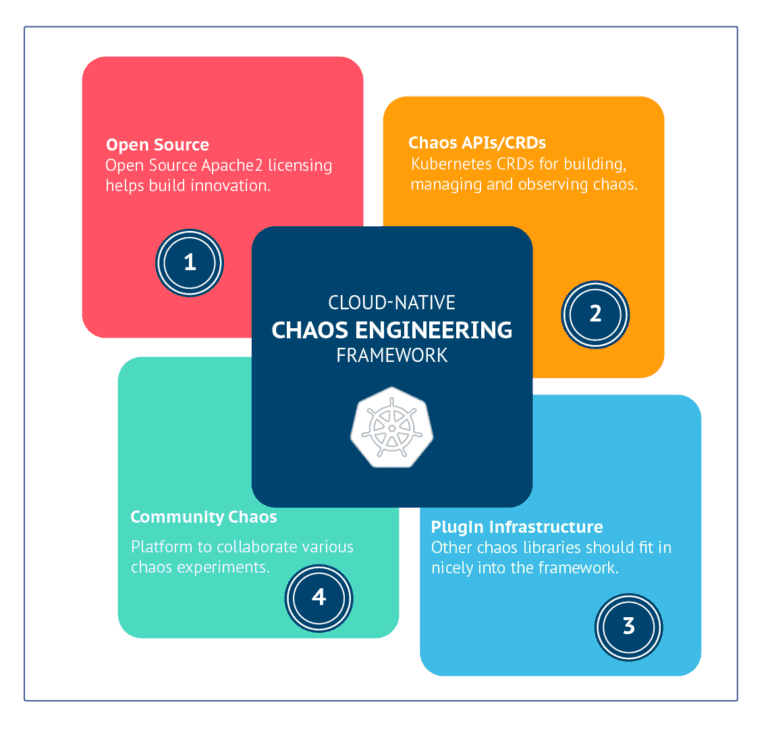
4 Principles of a Cloud Native Chaos Engineering Framework
These principles are for your guidance and they help you when you are choosing a strategy for your Chaos Engineering stack or framework for your Kubernetes platform.
1. Open source
The framework has to be completely open-source under the Apache2 License to encourage broader community participation and inspection. The number of applications moving to the Kubernetes platform is limitless. At such a large scale, only the Open Chaos model will thrive and get the required adoption.
2. CRDs for Chaos Management
The framework should have clearly defined CRDs for orchestrating chaos on Kubernetes. These CRDs act as standard APIs to provision and manage the chaos in complex production environments. These are the building blocks for chaos workflow orchestration.
3. Extensible and pluggable
One lesson learned why cloud-native approaches are winning is that their components can be relatively easily swapped out and new ones introduced as needed. Any standard chaos library or functionality developed by other open-source developers should be able to be integrated into and orchestrated for testing via this pluggable framework.
4. Broad Community adoption
Once we have the APIs, Operator, and plugin framework, we have all the ingredients needed for a common way of injecting chaos. The chaos will be run against a well-known infrastructure like Kubernetes or applications like databases or other infrastructure components like storage or networking. These chaos experiments can be reused, and a broad-based community is useful for identifying and contributing to other high-value scenarios. Hence a Chaos Engineering framework should provide a central hub or forge where open-source chaos experiments are shared, and collaboration via code is enabled.
An example of cloud-native Chaos Engineering framework is LitmusChaos.
Brief introduction to LitmusChaos
LitmusChaos is a cloud-native Chaos Engineering framework for Kubernetes. It is unique in fulfilling all 4 of the above principles. Litmus community publishes it's chaos experiments at hub.litmuschaos.io. The hub contains chaos experiments for Kubernetes resources and specific applications. Developers can bring in their own chaos experiments as a Docker container image and make use of the Litmus framework very easily to orchestrate and monitor chaos.
I will write another detailed blog to introduce Litmus here to the Dev community.
I will write another detailed blog to introduce Litmus here to Dev community.
Summary
Doing Chaos Engineering on Kubernetes should be an important first step towards high resilience levels in the deployments. The strategy of “Chaos First” will help set up the mindset of both developers and SREs. For practicing Chaos Engineering in cloud-native environments, you need not start writing the experiments from scratch. Instead choose the open-source framework that has a well-defined API, a lot of well-tested experiments, and a good community around it. Cloud-native Chaos Engineering fits into Kubernetes' scheme of things and SREs often find it as plug-and-play.

Top comments (0)