Check out the Python open-source project Flow Compose, a tool that facilitates the implementation of the Execution Flows programming paradigm.
Function as a Core Construct
All programming languages revolve around functions as fundamental building blocks. We encapsulate code within functions and invoke them at runtime. In this discussion, we focus on one essential characteristic of functions: input arguments. Functions rely on input arguments to access data and operate effectively.
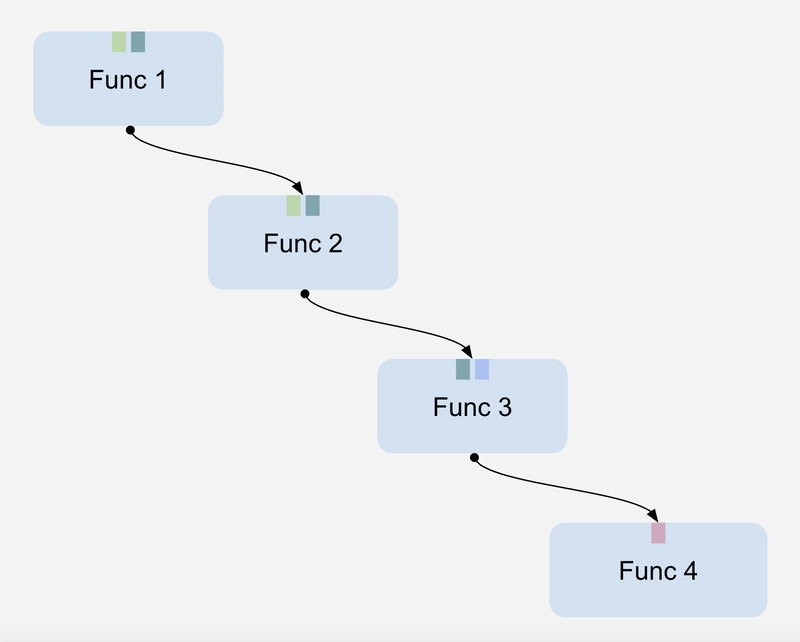
Figure 1. A simplified diagram illustrating how functions operate. Colored boxes represent the function's input arguments.
Function Input Arguments
A caller function must be aware of all required data and pass it to the called function through input arguments.
In object-oriented programming (OOP), additional data can be accessed through object member variables, reducing the reliance on function arguments. However, this approach is limited to the member variables of the specific object. Furthermore, adding new member variables to a class or object still requires passing them as arguments during object construction.
Explosion of Function Variations
As a software system expands its functionality, the number of functions grows exponentially. Variations of functions emerge to accommodate different use cases, leading to an increasingly complex codebase.
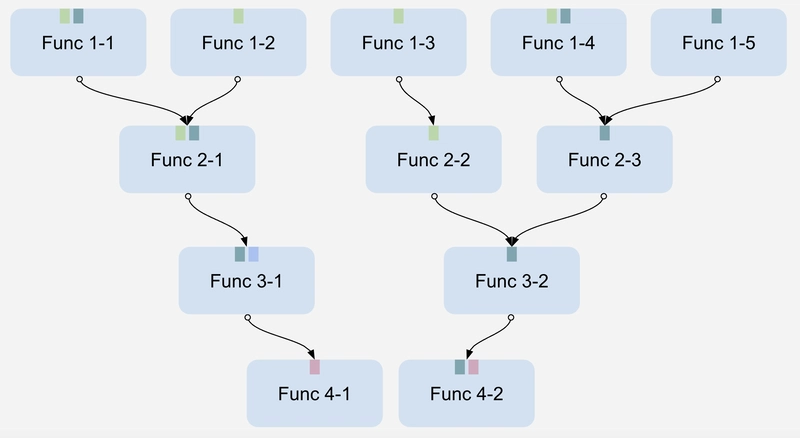
Figure 2. The complexity of the codebase grows exponentially, even with continuous code refactoring.
Each layer represents an application layer, such as the API, business logic, domain-specific components, or data transformation. Sub-numbers indicate variations in use cases and branching within these layers.
Why Can't Refactoring Help?
The extent of codebase refactoring is irrelevant because refactoring merely shifts complexity from one form to another. It can reduce a small number of massive, branching-heavy functions, but in doing so, it often explodes into an enormous number of smaller, interdependent functions, forming a complex execution graph.
Figure 2 is actually more representative of a refactored codebase—one where complexity is distributed across a large number of smaller, interconnected functions. However, real-world software architectures are far more intricate than this diagram suggests. These diagrams serve only to illustrate the core idea.
For applications with a small number of features and use cases, copying and pasting a few functions is rarely a concern. However, in enterprise software, the sheer scale of features and customizations drives exponential growth in branching and function variations, making complexity unavoidable.
Handling a Code Change
Code changes often require the introduction of a new data element. The most common way to deliver data is through input arguments. As a result, all functions involved in the feature must expand their input arguments to accommodate the change. This effect is known as “argument drilling.”
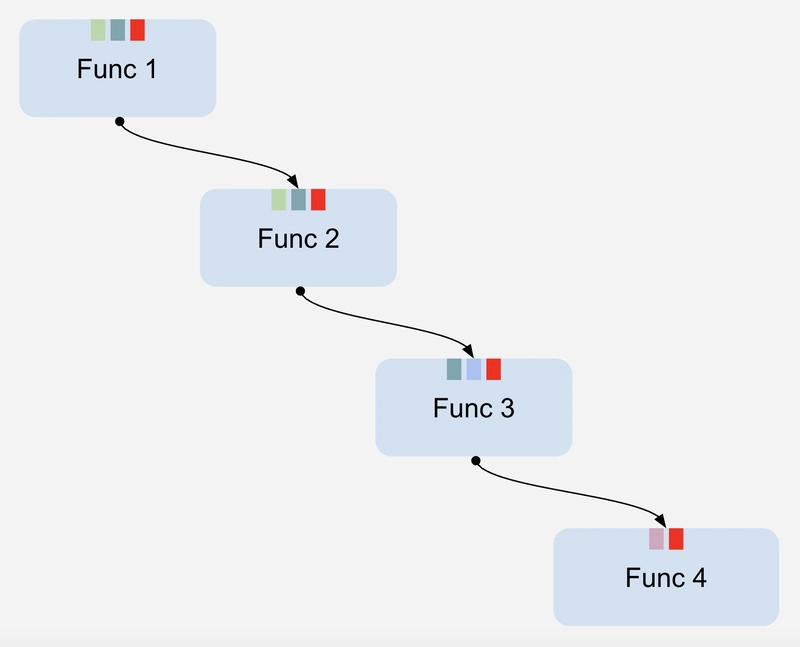
Figure 3. "Argument drilling" – A red box represents a new input argument required by Func 4.
Unfortunately, argument drilling has a significant impact, as it requires modifying not only all functions in the chain but also creating new function variations.
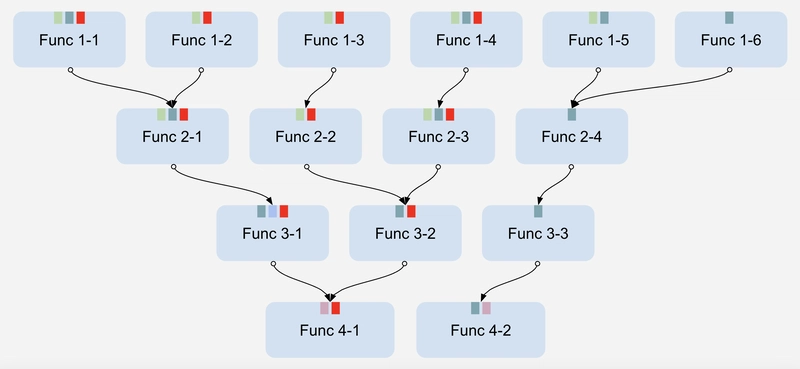
Figure 4. The magnitude of a “simple” code change in a large system.
"Simple code changes" become complex in large systems because the number of touchpoints grows exponentially.
Execution Flows Programming Paradigm
The benefits of the Execution Flows programming paradigm stem from three key characteristics:
1) Functions take no arguments.
2) Functions are mixins.
3) Functions use alias names.
Let’s explore each of these in more detail.
Introducing Methods and Properties as Nullary Functions
The first significant difference in the Execution Flows programming paradigm is that a function (referred to as a method) can access any data point (referred to as a property) available in the flow context.
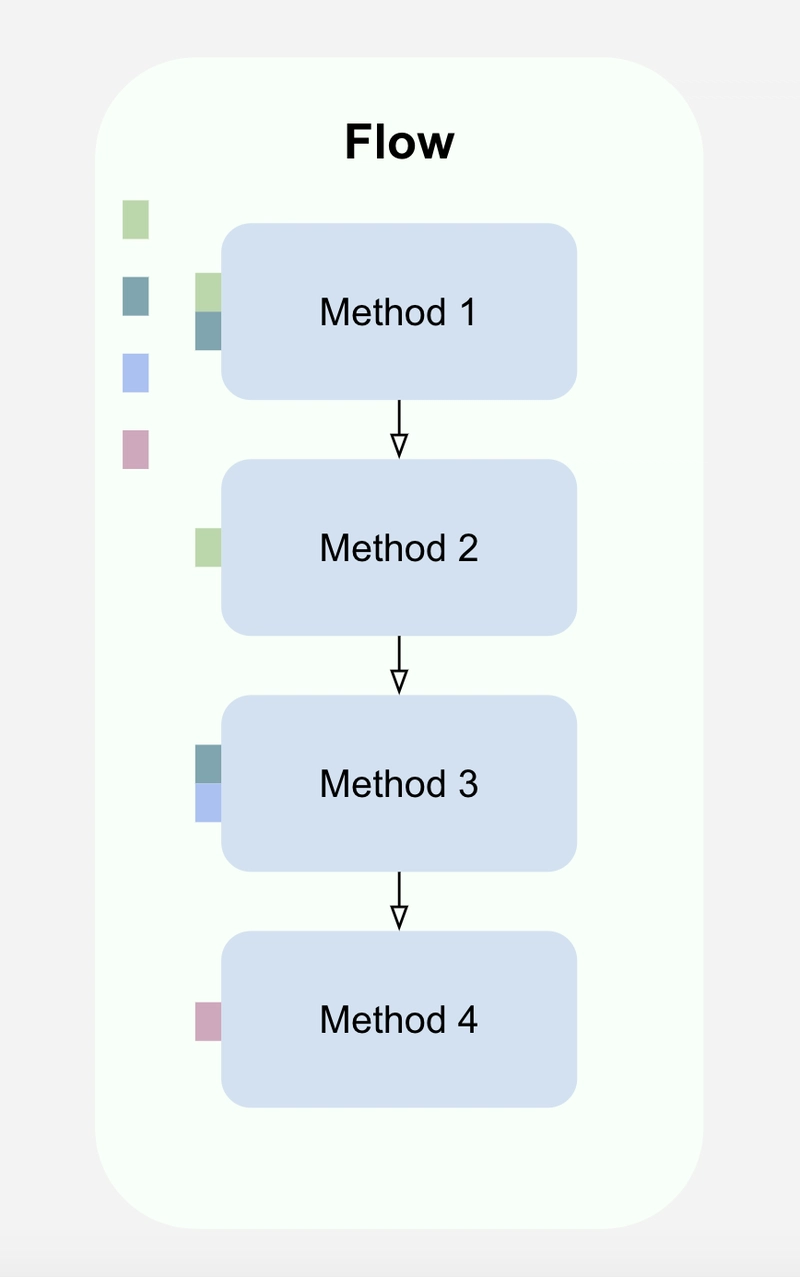
_Figure 5. Execution flow provides data properties (colored boxes) to its methods directly from the flow context, eliminating the need to pass them as arguments.
Because data properties are directly available to any method, methods rarely require arguments. When they do, these arguments are local and ephemeral, such as an index or the current item in a loop, which is readily available within the method's scope.
Methods and Properties as Mixins
The second key characteristic of methods and properties in the Execution Flows paradigm is that they function as mixins. When needed, a method or property can be added to any flow.
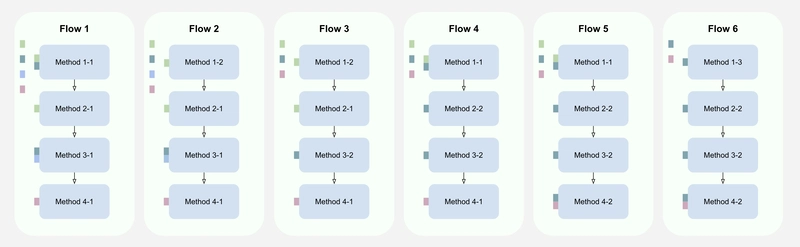
Figure 6. Methods and properties function as mixins — a single instance can be added to multiple flows.
Methods and Properties Are Referenced Using an Alias Name
The third key aspect of mixins — whether methods or properties — is that they reference other mixins using an alias name.
For example, Method 1-1 in Figure 6 calls Method 2, without directly specifying Method 2-1 or Method 2-2. Instead, the Flow determines which implementation of Method 2 will be used: either Method 2-1 or Method 2-2.
Because:
1) Methods take no arguments, reducing dependency on explicit data passing.
2) Methods are mixins and can be added to any flow.
3) Methods use alias names to access other mixins instead of direct references.
As a result, we achieve multiple orders of magnitude fewer variations in function implementations.
Now, let’s explore how much this reduces complexity.
The Complexity of a Code Change in the Execution Flows Programming Paradigm Is...
Unlike other programming paradigms, where code changes lead to variations of functions, code changes in the Execution Flows paradigm are highly localized. A change affects only the method that requires modification and involves adding a new property to the execution flow.
Adding a property to a flow is a one-line change.
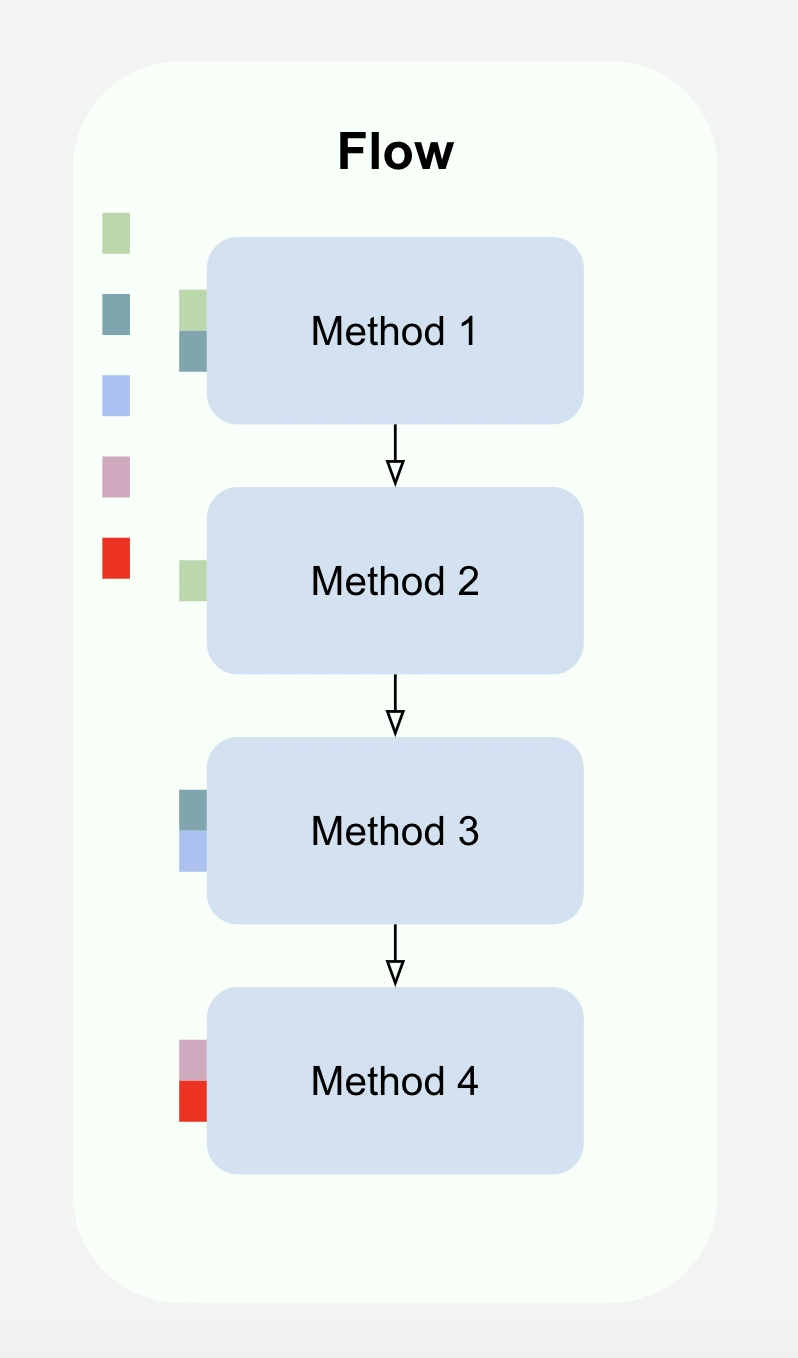
Figure 7. The red box represents a new data property used by Method 4.
To better understand how localized a code change is, let’s examine what it takes to modify multiple flows that are variations of a similar use case.
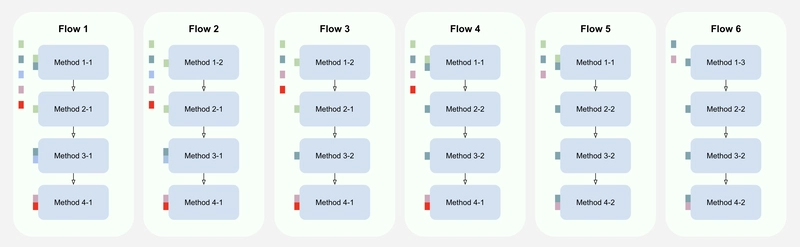
Figure 8. Implementing a change across multiple flows.
The code change is limited to Method 4-1 and involves adding a new property mixin to the flows that use Method 4-1.
Adding a property mixin to a flow is a one-line code change.
Conclusion
By adopting the Execution Flows paradigm, we reduce the exponential complexity of a code change from O(kⁿ) to constant complexity O(1).
For example, the code change shown in Figure 8 required modifying only a single method and adding a property to a fixed number of flows.
You can check out the Python open-source project Flow Compose, a tool that facilitates the implementation of the Execution Flows programming paradigm.

Top comments (0)