For the last few months, I was busy working with Kappitaan.com. And I was primarily responsible for building their website. And at the core, we used Next.js, Redux, a custom design system based on MaterialUI and Typescript.
In this article, I'm going to cover how and why we invented DataRepoArch and later found a better and mature opensource alternative for the same.
DataRepoArch is a client-side architecture designed to use with react for better server state handling. This architecture also guarantees a very neat, highly pluggable, and maintainable codebase.
Kappitaan.com help empower students and healthcare professionals by making it easier to train and get placement for work abroad.
So the story starts here
Though in the initial phase we didn't have many global state management requirements, we still integrated redux to our framework (without compromising code-splitting benefits). We were sure that we have a lot of server state handling coming for the dashboard part of the website.
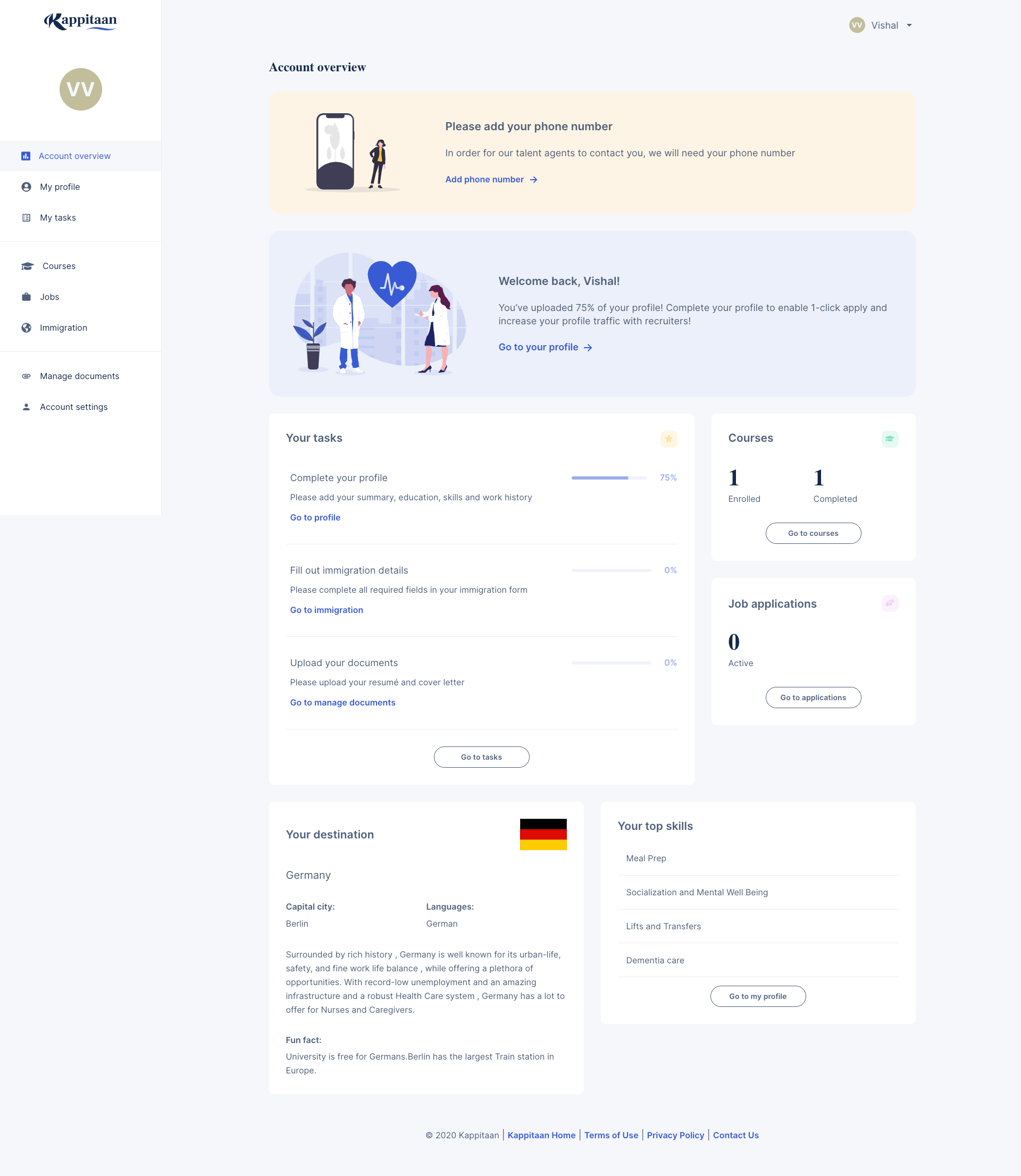
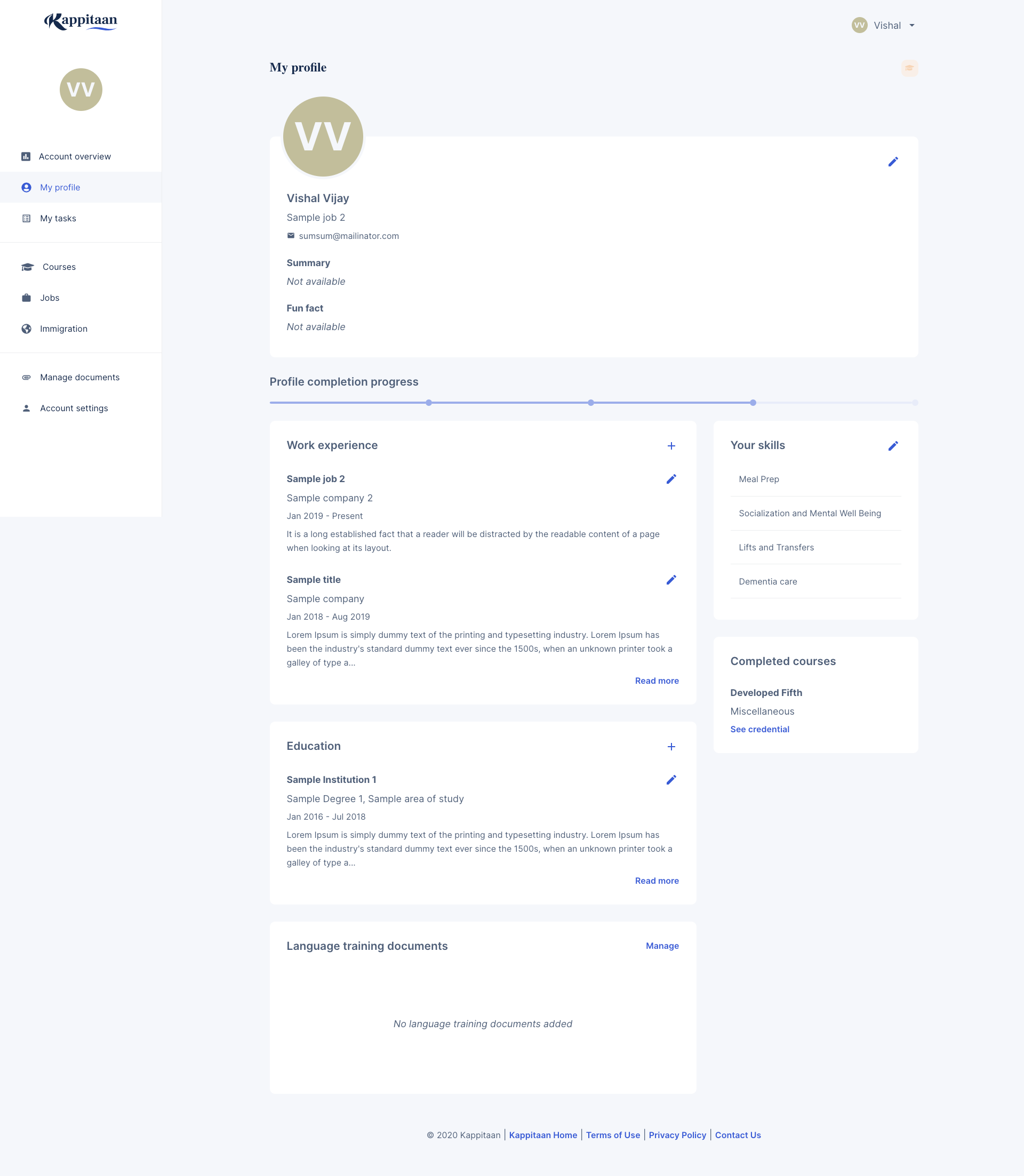
Before we continue, please check the sample screenshots of the dashboard to get an understanding. Sample 1, Sample 2
With the help of screenshots, we can understand the below points and requirements:
- Each page of the dashboard is consistent with multiple data cards.
- Some of the cards require data from the same source.
- Every page requires common dashboard related metadata to start loading.
- Data can get modified from anywhere on the dashboard.
- There are pages that require the same data which we fetched on other pages.
- A single data card might require data from multiple sources.
- If one of the API fails, users don't have to click retry on every card which uses the same data.
So to accomplish these requirements, we started the development plan with the traditional redux approach. This means, page component handles the fetching of the data and distributes it across the data cards based on its data requirements.
Listing the problems which we identified with this approach:
- The page component needs to know what all data cards are there on the page and its data requirements.
- Everything has to be routed through the page component as it handles the data fetching and caching using redux.
- API error handling and retry also became challenging.
- Lot of boilerplate code to handle data fetching.
- On page navigation, it triggers multiple API calls if the previous API hasn't finished loading for the same data.
- Data components are unable to abstract the business logic and it became really difficult to reuse the components.
- So many props to be passed in each data card to handle different states.
- Mutating the data also leads to a lot of boilerplates.
We understood that, if we take this approach, it is going to make our code difficult to maintain and adds a lot of boilerplates. Eventually, every feature additions are going to consume time in both developing and testing.
So, we decided to come with different approaches. Another suggestion was to move data loading inside a specific data card component. And that will help us solve many of the above problems mentioned such as data card can be reused, need not depend on parent or page component, etc.
But it still doesn't solve the problem of duplicate API calls, ease of development, and boilerplate code.
But we all agreed that the above is the way forward but we need a better framework in place. So we did our R&D and found a few libraries and architecture like react-query. When we initially looked at react-query we thought that this is another data fetching library similar to fetch. The fact is, we didn't do deep dive into the details of it.
So after the R&D, we didn't identify something which suits our requirements. So we decided to innovate ourselves.
DataRepoArch begins here
As we already have a redux system integrated, we decided to build something which is pluggable to it. And we started listing down the problems which we want to solve and the features we want to support.
- It must allow using any data fetching logic. Can be from a remote source, local data, fake data, or even from already downloaded data.
- All data should be by default in-memory cached and should get re-fetched if intentionally triggered (usually after mutation).
- It should not allow duplicate API calls if different data cards make the same request when already one is being fetched.
- It should easily allow handling data fetching states.
- It should allow fetching and handle multiple data together for the same data card.
- It should allow retrying API call if the previous one failed. And on retry, it should refresh all the data cards depended on the same data.
So we started architecting it
A working POC application can be found here. Randomly try navigating and refreshing the pages and experience the features like data fetching, caching, retry, parallel fetching, etc.
We are throwing errors randomly in the data fetching logic, to make it easier to test retry behavior.
Before we talk about the internal details of the architecture, let's see how a developer can use this architecture.
So let's look at Page 1
const Page1: React.FC = () => {
return (
...
<UserDetails />
...
<UserDetails />
...
<Product productId={200} />
...
<Product productId={140} />
...
<Product productId={200} />
...
<UserAndProduct />
...
);
};
Page 1 is consists of 3 unique data cards. In it, we are showing user details card 2 times, and 3 different product card. Also an example of fetching user and product details in a single card. Looking at the above sample you will understand, how pluggable are each card and all its business logic have been abstracted in itself.
Let's look at the code of all 3 unique data cards here
Before we continue, a quick note about DataLoadingHandler. It is a simple component that takes care of showing loader and API error based on the fetching state.
UserDetails
const UserDetails: React.FC = () => {
const userDetailsRepo = useUserDetailsRepo();
return (
<Paper>
<Box p={2}>
<DataLoadingHandler
successCode={userDetailsRepo.successCode}
errorMessage="Failed to load user details"
onRetry={userDetailsRepo.refresh}
render={(): JSX.Element => (
<>
<Typography gutterBottom variant="h4">
Name: {userDetailsRepo.data?.name}
</Typography>
<Typography gutterBottom>
Email: {userDetailsRepo.data?.email}
</Typography>
<Typography gutterBottom>
Total votes: {userDetailsRepo.data?.totalVotes}
</Typography>
</>
)}
/>
</Box>
</Paper>
);
};
The DataRepo API is as simple as this.
- Use the custom data repo hook.
- Pass
successCodetoDataLoadingHandler - Use the data the way you want in the render method.
Product
const Product: React.FC<Props> = ({ productId }) => {
const productRepo = useProductRepo(productId);
const product = productRepo.data;
return (...);
};
Product card implementation is also similar to UserDetails the only difference is, we are passing productId to useProductRepo hook to fetch independent product details.
UserAndProduct
const UserAndProduct: React.FC = () => {
const userDetailsRepo = useUserDetailsRepo();
const productRepo = useProductRepo(23);
const aggregatedRepo = useAggregatedRepo([userDetailsRepo, productRepo]);
return (
<Paper>
<Box p={2}>
<DataLoadingHandler
successCode={aggregatedRepo.successCode});
...
};
The UserAndProduct example demonstrates the use case of useAggregatedRepo. This helps to aggregate multiple custom data repo hooks fetching state to a single state for better loading and API error handling.
Now let's look into custom data repo hooks
There are 2 data repo hooks we wrote for this POC
useUserDetailsRepo
const fetchUserDetails = synchronisedPromiseMaker(
async (): Promise<UserDetails> => {
// eslint-disable-next-line no-console
console.log("Fetching user details...");
await sleep(2000);
if (Math.floor(Math.random() * 10) % 5 === 0) {
throw Error("Failed to load user details");
}
return {
email: "hi@example.com",
name: "Sample name",
totalVotes: 200,
};
}
);
const useUserDetailsRepo = (): Repo<UserDetails> =>
useRepo<UserDetails>("userDetails", fetchUserDetails);
synchronisedPromiseMaker is a utility created to prevent duplicate API calls at the same time.
The key to DataRepoArch is useRepo, this is where all the magic happens. You simply have to provide a repo name, a synchronized promise (which takes care of data fetching the way the developer wants), and the rest of the arguments will be forwarded to the data fetching method.
That's it, the data repo is ready.
useProductRepo
const fetchProduct = synchronisedPromiseMaker(
async (productId: number): Promise<Product> => {
// eslint-disable-next-line no-console
console.log("Fetching product...", productId);
await sleep(2000);
if (Math.floor(Math.random() * 10) % 5 === 0) {
throw Error("Failed to load product");
}
return {
id: productId,
name: `Sample product ${productId}`,
price: 450,
quantityAvailable: 23,
category: "Sample category",
};
}
);
const useProductRepo = (productId: number): Repo<Product> =>
useRepo<Product>("product", fetchProduct, productId);
useProductRepo is also similar to userDetailsRepo but it accepts productId as an argument.
That's all... developer need not worry about anything else. We solved all the problems we discussed above.
Now let's look at the core components of DataRepoArch
Redux
The current POC implementation is an addon for Redux. We did it because it can be easily plugged into our current project. But this redux dependency for DataRepoArch was unnecessary. We had only a little time to implement this all architecture. So for this version, we didn't want to reinvent the wheel and we want to take the advantage of the already existing architecture.
useRepo
This is the core of DataRepoArch. It abstracts:
- Redux communication
- Promise execution
- Loading state management
- Data caching based on arguments
- Reset data functionality
- Refresh data functionality
Using the
resetorrefreshmethod you can ask to clear or refresh the data which is already cached in redux. This will come handy when you want to mutate any dependent data.
useAggregatedRepo
This hook will help to handle multiple data dependency loading. You can avoid a lot of duplicate code in your component.
Yes... that's all about DataRepoArch. It's as simple as that.
But we think react-query is much better
Our current Kappitaan.com website uses DataRepoArch in production and we are really happy with the current product deployed. But we know that there is a lot of opportunities for improvements.
When we initially looked at react-query, we were not sure about all the problems which we have to solve in the current project. Also, we didn't understand the full potential of react-query and it was quite new at that time (Major development of the library happened in early 2020). Our implementation of DataRepoArch started around March 2020.
Along with the project, DataRepoArch also started evolving and we enhanced the architecture to allow the developer to write better code. At the later stage of the project, we had a chance to read more about react-query and that is when we started comparing our feature with react-query. Listing some of the core features supported by it.
- Transport/protocol/backend agnostic data fetching (REST, GraphQL, promises, whatever!)
- Auto Caching + Refetching (stale-while-revalidate, Window Refocus, Polling/Realtime)
- Parallel + Dependent Queries
- Mutations + Reactive Query Refetching
- Multi-layer Cache + Automatic Garbage Collection
- Paginated + Cursor-based Queries
- Load-More + Infinite Scroll Queries w/ Scroll Recovery
- Request Cancellation
- React Suspense + Fetch-As-You-Render Query Prefetching
- Dedicated Devtools (React Query Devtools)
Though we were sad that we didn't realize the potential of react-query and reinvented similar features in DataRepoArch. But we were happy that the problems which we tried to solve are valid and the thought process and solutions which we put to it are aligned with a quality library like react-query. So we are proud of what we made 💪.
The future plans
We are not going to invest more in DataRepoArch. Instead, we are planning to migrate to react-query. And our team will look into potential contributions to it.

{kind=link}
{kind=link}
Top comments (0)