Introduction
In this guide, we'll build a Retrieval-Augmented Generation (RAG) system using FastAPI for the backend and React Native for the frontend. The RAG system will allow users to interact with PDF documents by querying relevant information and generating responses using an advanced language model powered by Ollama. This system will also provide citations for the retrieved data, linking it back to the original documents.
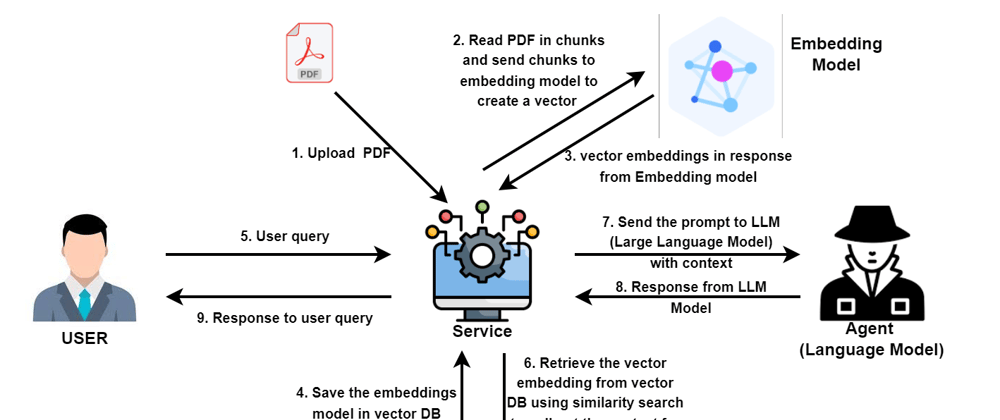
Overview of the Architecture:
1. Backend (FastAPI):
- Handles PDF uploads from the user, processes the content (text extraction), and stores the data in a vector database.
- Generates embeddings using Ollama API and stores them in ChromaDB for fast retrieval.
- Provides an API endpoint to process user queries by querying the vector database and returning the relevant document chunks.
- Uses Ollama to generate responses to user queries based on the context retrieved from the documents.
- Returns the response along with citation links for transparency and verification.
2. Frontend (React Native):
- Provides a user-friendly interface to interact with the backend API.
- Users can upload PDFs, view responses, and interact with the system by sending queries.
- Displays responses from the backend with citations, enabling users to verify the sources of the information.
- Handles user input, sends queries to the backend, and displays the resulting responses.
Backend Setup: FastAPI for PDF Processing and Query Handling
The backend is built with FastAPI, which is known for its speed and efficiency. The FastAPI server will handle PDF uploads, process text using the Ollama API, and store the results in a vector database for fast retrieval.
Backend Code (FastAPI)
1. PDF Upload and Text Extraction: The backend provides an endpoint to upload PDF files. The file is saved on the server, and its text content is extracted. The text is then chunked into smaller pieces (e.g., 500 words per chunk), making it easier to work with.
Text Extraction from PDF:
def extract_text_from_pdf(file_path):
text = ""
with open(file_path, "rb") as file:
reader = pypdf.PdfReader(file)
for page in reader.pages:
text += page.extract_text() + "\n"
return text
Here, we use the PyPDF library to read and extract text from the PDF. The extract_text_from_pdf function opens the file, reads each page, and appends the extracted text to a string.
2. Chunking Text for Embedding: After extracting the text, it is chunked into smaller pieces to improve embedding generation and querying performance. The chunking ensures that each document is broken down into manageable parts.
Chunking Function:
def chunk_text(text, chunk_size=500):
words = text.split()
return [" ".join(words[i:i+chunk_size]) for i in range(0, len(words), chunk_size)]
3. Generating Embeddings: For each chunk of text, we generate an embedding using the Ollama API. Embeddings are numerical representations of text that capture semantic meaning, allowing us to efficiently retrieve relevant document chunks when processing user queries.
Embedding Generation:
async def generate_embedding(text):
try:
response = httpx.post(f"{OLLAMA_API_URL}/api/embeddings", json={"model": "nomic-embed-text", "prompt": text})
response_data = response.json()
return response_data['embedding']
except Exception as e:
print(f"Error generating embedding: {e}")
return None
4. Storing Embeddings in ChromaDB: The embeddings are stored in ChromaDB, a vector database that allows for efficient retrieval of document chunks based on their embeddings. When the user queries the system, we can compare the query's embedding with the stored embeddings to find the most relevant document chunks.
Storing Chunks in ChromaDB:
collection.add(
ids=[f"{file.filename}-{idx}"],
embeddings=embedding,
metadatas=[{"text": chunk, "source": file.filename}],
documents=[chunk]
)
5. Retrieving Relevant Chunks: When the user sends a query, we generate an embedding for the query and retrieve the most relevant chunks of text by comparing the query embedding with the stored embeddings in the vector database.
Query Retrieval:
async def retrieve_relevant_chunks(query, top_k=3):
query_embedding = await generate_embedding(query)
results = collection.query(query_embeddings=query_embedding, n_results=top_k)
relevant_chunks = []
citation_links = []
for item in results["metadatas"][0]:
chunk_text = item["text"]
source_file = item["source"]
citation_url = f"http://localhost:8000/pdf/{source_file}"
relevant_chunks.append(chunk_text)
citation_links.append({"url" : citation_url, "title" : source_file})
return relevant_chunks, citation_links
6. Querying Ollama for a Response: Once the relevant chunks are retrieved, we send a prompt to Ollama's language model with the context from the documents and the user’s query. Ollama generates a response, which is then sent back to the frontend.
Query Ollama:
async def query_ollama_with_context(context_chunks, model_name, user_query):
context = "\n\n".join(context_chunks)
prompt = f"Context: {context}\n\nUser Query: {user_query}\n\nAnswer:"
async with httpx.AsyncClient(timeout=900) as client:
response = await client.post(
f"{OLLAMA_API_URL}/api/generate",
json={"model": model_name, "prompt": prompt, "stream": False}
)
response_data = response.json()
return response_data["response"]
7. Serving PDFs: The FastAPI backend also allows users to download the original PDF files via a simple API endpoint.
Serve PDFs:
@app.get("/pdf/{filename}")
async def serve_pdf(filename: str):
file_path = os.path.join(PDF_STORAGE_DIR, filename)
if os.path.exists(file_path):
return FileResponse(file_path, media_type="application/pdf")
return {"error": "File not found"}
Frontend Setup: React Native for User Interaction
The React Native frontend provides an interface for the user to interact with the system, including uploading PDFs, querying the system, and receiving responses.
Frontend Code (React Native)
Message Handling: The messages state keeps track of the conversation. Each message contains the message content, its sender (user or bot), and a unique ID.
1. Message Handling:
const [messages, setMessages] = useState([]);
const [inputMessage, setInputMessage] = useState('');
2. Sending Queries: When the user types a message and presses the send button, the app sends the user query to the FastAPI backend.
Send Message:
const handleSendMessage = async () => {
if (inputMessage.trim() === '') return;
const userQuery = {
id: Date.now(),
text: inputMessage.trim(),
sender: 'user',
};
try {
setMessages((prevMessages) => [...prevMessages, userQuery]);
setInputMessage("");
await processUserQuery(inputMessage);
} catch (error) {
console.error('Error sending message:', error);
}
};
3. Rendering Responses: Once the backend sends a response, the frontend displays it as a chat message. The response includes HTML content, which is rendered using the react-native-render-html library.
Rendering Messages:
const renderMessage = (item) => (
<View
key={item.id}
style={[
styles.messageContainer,
item.sender === 'user' ? styles.userMessage : styles.botMessage,
]}
>
{item.sender === 'bot' ? (
<RenderHTML contentWidth={width} source={{ html: item.text }} />
) : (
<View>
<RenderHTML contentWidth={width} source={{ html: `<p>${item.text}</p>` }} />
</View>
)}
</View>
);
4. Handling Input: The input field allows users to type messages. The input is cleared once the message is sent.
Input Field:
<TextInput
ref={inputRef}
style={styles.input}
value={inputMessage}
onChangeText={setInputMessage}
placeholder="Type your message..."
multiline={false}
placeholderTextColor="#aaa"
/>
5. Displaying Send Button: The send button triggers the handleSendMessage function, which sends the user's query to the backend.
Send Button:
<TouchableOpacity onPress={handleSendMessage}>
<View style={styles.sendButton}>
<RenderHTML contentWidth={50} source={{ html: "<strong>Send</strong>" }} />
</View>
</TouchableOpacity>
Deployment Instructions
Make sure the Docker is install and running.
Run the docker compose command from root project
docker compose up --build
Conclusion
In this project, we've built a robust RAG system that uses FastAPI for backend processing and React Native for frontend interaction. By combining Ollama's language models with ChromaDB for vector storage, we've enabled efficient retrieval and query processing. The system allows users to upload PDFs, query them, and receive detailed responses with citations for verification.
Complete source code : https://github.com/vcse59/GenerativeAI/tree/rag-based-application
Youtube Video : https://youtu.be/3OQ0dQ2YqGk?si=IwvBwMhK02sC0exU

Top comments (0)