
Developers know well the perils of mutable state in a program. A value changes from underneath you, messing up a computation in progress. Two different places on the screen, ostensibly based on the same information, are not consistent with each other. The application crashes because a value was not changed at an appropriate time.
The functional style of programming, which is based on immutable values and functions that build new values instead of mutating existing ones, has become very popular due to the complexity of managing state when everything is mutable. But let’s say that we find programming with mutable state useful. For instance, my experience is primarily in mobile app development with the native tools, where the whole platform is built around mutable state, and it is a rare team or company that is willing to go for a completely different app architecture or programming style than is practiced by the majority of developers. The main question then becomes how do we manage that state to keep our programs comprehensible.
Values and Entities
A view that I’ve found useful is to divide the objects manipulated by the program into two kinds, values and entities. A value is conceptually similar to a primitive type, an immutable object, with a structured value simply a sum of its parts with no hidden content. In contrast, each entity is a distinct object, even from entities with the exact same state. And as an entity has a distinct identity, its state can be mutable.
| Value | Entity |
|---|---|
| State-based equality | Distinct identity |
| Immutable | Internal mutable state |
| External observable state | |
| “Functional” | “Object-oriented” |
This view conflates equality with mutability, but in my opinion the other possibilities are not needed. An immutable object with a distinct identity can simply be a value that includes a unique identifier. And a mutable object with state-based equality is in my experience just asking for trouble.
Languages like C# and Swift have some of this separation at the language level, with the separation of types into structs (values) and classes (entities). But they don’t go all the way, as both also include an overridable equality for their entity types, allowing a non-identity-based equality to be defined. I feel like this is a holdover from languages where “Everything is an entity” and has no place in a proper value-entity-separating language. The “identity has a state” approach of Clojure is much better but we can’t always program in Clojure.
I’ve used the terms “Functional” and “Object-oriented” in the table above, as this is how a programming style primarily based on one kind feels to me. A functional style is based on values, building new values out of pure computations on existing values, whereas an object-oriented style is based on distinct entities having internal state modified by their external interfaces. The rest of this post will be focused on the entity-based object-oriented style relying on mutable state, so I won’t say more about the pure functional style.
State
Now that the big beast of mutable state has been pushed into these things I call entities, let’s look at how to manage it. I’ve split state in an entity into two forms, internal and external. It doesn’t matter much how internal state is managed, as that is local to the entity and can be contained in a small enough area to usually be understandable.
For external state, it should make sense as something that is exposed by the entity. Most often, it is better not to simply expose a piece of internal state directly as external state, but provide something more meaningful to the outside world. Or even expose only invocations that can be performed on the entity, whose implementation depends on the internal state but no specific state is ever exposed.
Thinking in terms of invariants helps keep the state of an entity manageable. An invariant is simply a property that holds among different parts of an entity’s state. For instance, in an entity representing a shopping cart, the total price should be the sum of the prices of the individual items minus any applied discounts. While an entity is modifying itself, an invariant can temporarily be violated, but an external observer should always see the invariant to hold.
I used the term “observable” in the table above for external state. This, to me, is necessary to manage the application state properly. It must be possible for other entities to observe changes in an entity’s state and to react to those changes. In a stateful application, pieces of state are never fully independent of each other, so keeping the complete application state consistent requires modifying many pieces of it simultaneously.
Dependencies
Observable state and reacting to its changes introduces the notion of an entity, and its state, depending on the state of another entity. Internally, entities can contain references to other entities that they depend on. And their state can depend on the state of other entities. So there are two kinds of state: Base state and derived state, where derived state is a composition of other state.
I find that a good way to manage this is to represent the observable state of an entity as values. Following this, derived state can be defined as a pure function of its dependent state. This is essentially how spreadsheets work, and that is a very useful conceptual model for understanding the complete application state as consisting of independent pieces of base state and dependent pieces of derived state. Entities may contain other entities as internal state but these contained entities are never exposed as external state.
To do this properly, the programming language or environment needs to support some form of data binding. Derived state is defined by binding to all its dependencies, with a pure function to compose it. This way the system guarantees that all the state throughout the application is always consistent. This can in theory be also done with the Observer pattern, but as the Observer pattern splits the definition of the state from the update, in practice it can be too easy to forget some necessary update to derived state when the relationships get complex.
The Redux architecture shows similar thinking. State changes are performed with pure functions that take the existing state and a performed state-changing action. Redux essentially has only one entity, the store, which simplifies derived-state management. When combined with something like React, where the UI is a pure function of application state, the complexity of state management is significantly reduced.
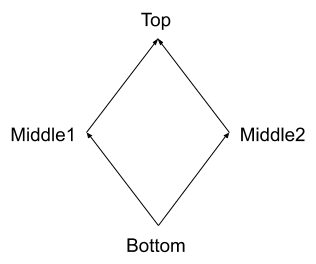
In platforms that encourage the multiple-entity style, derived-state management is not really supported all that well in languages themselves or their libraries. Data binding is usually treated through modification events, which do not function well in, say, the diamond dependency scenario: The state of entity Top depends on the states of entities Middle1 and Middle2, both of which depend on the state of entity Bottom. The correct order to modify the states is Bottom -> (Middle1, Middle2) -> Top, which is followed by any spreadsheet, but a system based on modification events will do Bottom -> Middle1 -> Top, where the new state of Top is computed based on the new state of Middle1 but the old state of Middle2, leading to an inconsistency.
For large pieces of state, it is not really the best idea to rebuild all depending state from scratch when something little changes. For instance, if the state represents the whole product catalog of a shop service, adding one more product is a very small change that should not trigger massive recomputations. In such situations, I usually include an additional stream of change events. A change event is essentially just the difference between the previous state and the current state, and it has enough information so that any derived state can be modified to match the new dependent state. So when first creating an entity with derived state, a full computation is performed, but afterwards, the derived state is modified in place to reflect changes communicated through the change events.

Top comments (0)