
I attended the Datathon 2019 on October 20th and it was so much fun.
This year the event was hosted by Texas A&M University where I just graduated 3 months ago.

For the first time, TAMU Datathon is banding together data enthusiasts from across multiple disciplines, skill levels, and universities. TAMU Datathon is a 24-hour non-stop coding event where companies, researchers, and hundreds of students immerse themselves in data science.
This was probably the largest Data Science Hackathon in the US. There were 2032 Applications, 110 universities worldwide, and 15 company sponsors. Some big companies that sponsored the event are Facebook, ConocoPhillips, CBRE, Goldman Sachs, Shell, Walmart.
There were learning and competition track. The learning track was for beginners who have little or no experience in data science. Attendees on this track could choose to attend a series of lectures or a number of different workshops created by global lead data scientists. On the competition track, participants can show off their programming skills which could help them win prizes or earn an internship opportunity with a company.
I chose the competition track because it sounded so much fun. I joined the event Slack and found 3 friends who were also interesting in competition. Together, we created a team (4 math students) and worked non-stop on the problem.

When I first came, I was overwhelmed by the size of the event. Here are some pictures describe the activity at Recreational Center conference room throughout the day

and night...

Challenge
Every company brought here a challenge and the competitors could freely choose which one they want to do. There were three problems that I found entertaining:
Walmart: use the image processing technique to detect the availability of products on the shelves. This is mainly to deal with Black Friday!
ConocoPhillips: given a time series of about 150 sensors data on a drilling rig, predict when the machine has a malfunction.
Facebook: create a mini google map for the Dodoma region, given the satellite images and residential houses location.
I ended up choosing the Facebook challenge because of its complexity. The data consist of 64 high-resolution pictures described road network of the region approximately 30 km x 30 km in the vicinity of Dodoma, the capital of Tanzania
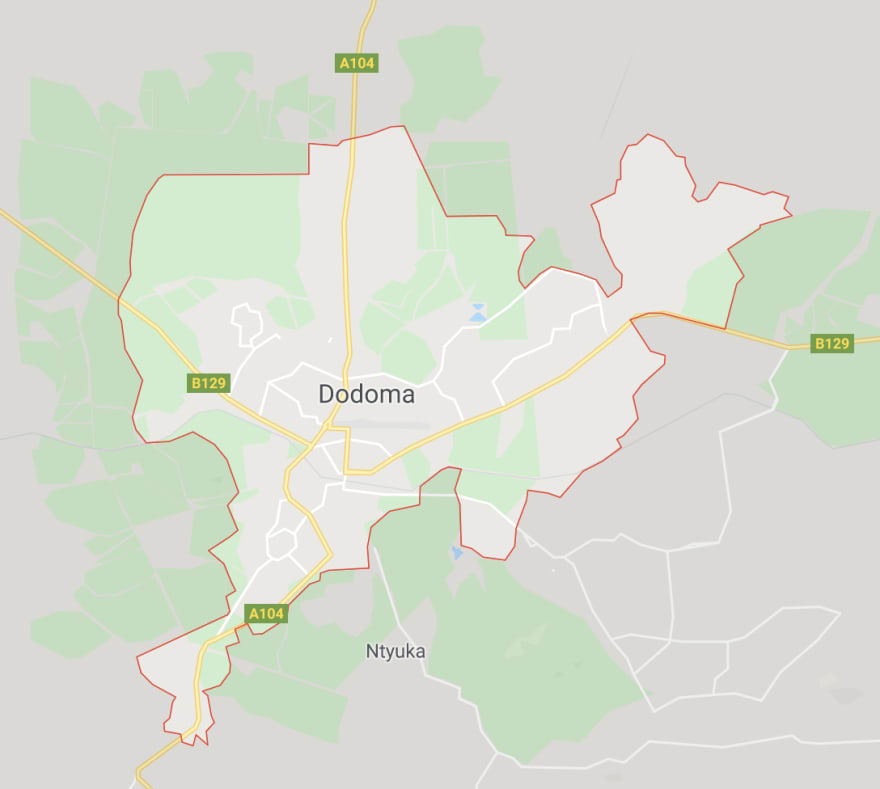
A sample of 4 images

Putting 64 images together we have the whole map
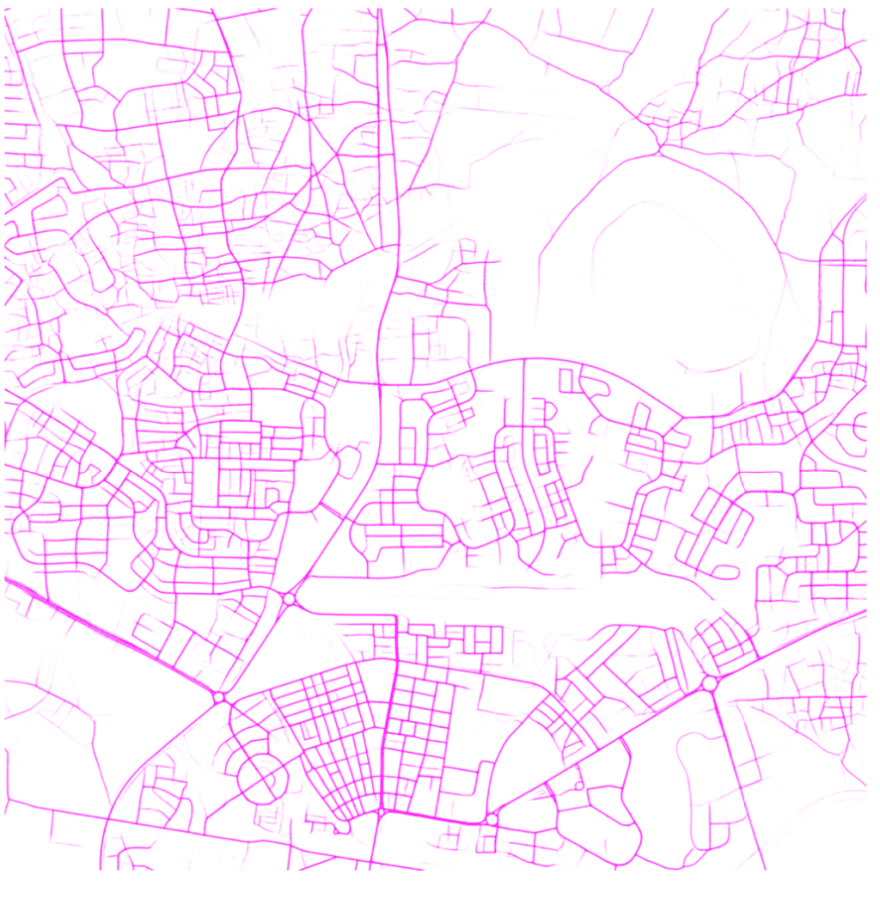
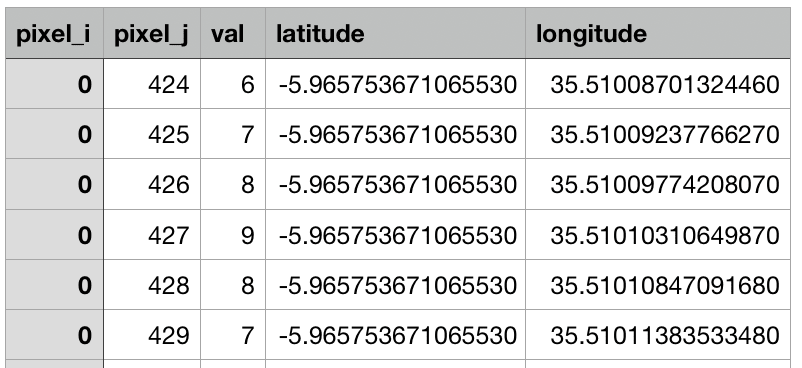
Besides the pictures, there was a folder containing 64 .csv files with detail about each pixel of the map and their coordinates!. Each pixel approximately represents 0.5 meters square in real space.
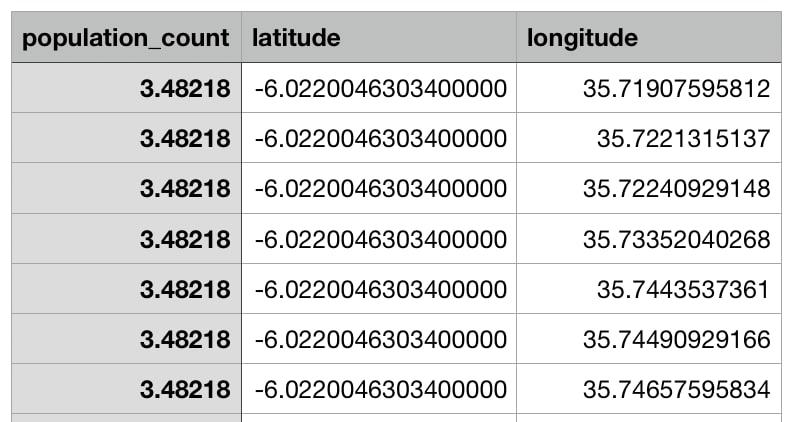
Another .csv file consists of population features
The questions were:
1) Find the closest street to each residential location
2) Find the closest patch from one place to another.
The data was two gigabytes and solving the second question required hours of training the neural networks. It was really hard working with big data and deliver a result in just one day. In fact, some of us did not sleep at all.
Presentation
The presentation starts at 2 p.m of the following day. The host set up a big timer on the projector. Every time it hit 4 minutes stop, all judges move to the next table to grade a different project. The best part about the presentation was I could talk to Facebook data scientists and listen to their valuable feedbacks.

The picture of me and my team presenting to a Facebook judge

After a tiring day, we took a group picture together. We were just strangers the day before and now we became much closer. This was because we tried so hard to complete our project. I was excited to come back home and shared my experience with everyone in my data science Bootcamp and later, the dev.to community.

For more pictures of the event, please visit here.


Top comments (0)