With Azure Synapse Link for Azure Cosmos DB, we can now gain insights over our transactional data seamlessly without having to develop our own ETL pipelines.

In the past, performing traditional analytical workloads with Azure Cosmos DB has been a challenge. Workarounds such as manipulating the amount of provisioned through and using the Change Feed or any other ETL mechanism to migrate data from Cosmos DB to platforms more suited to performing analytics on our data do exist, but are a challenge to develop and maintain.
Azure Synapse Link for Cosmos DB addresses the needs to perform analytics over our transactional data without impacting our transactional workloads. This is made possible through the Azure Cosmos DB Analytical store, which allows to sync our transactional data into a isolated column store without us having to develop and manage complex ETL jobs, impacting our operational workloads and providing us with near real-time analytical capability on our data.
In this article, I'll cover what Azure Cosmos DB and Azure Synapse Analytics are and how they are tied together through the Cosmos DB Analytical Store. I will then show you how to enable Azure Synapse Link for your Cosmos DB account and how to create Containers in Cosmos DB with the Analytical Store enabled.
I'll then show you how to link your Cosmos DB account to your Azure Synapse workspace and show you how to query the data in the Analytical store using Apache Spark.
What is Azure Cosmos DB?
Azure Cosmos DB is Microsoft's globally distributed, multi-model, NoSQL database service that allows us to elastically and independently scale in terms of both throughput and storage to any Azure region worldwide.
We can build databases that use Document data (SQL and MongoDB API), Key-Value data (Table API), Columnar data (Cassandra API) and Graph data (Gremlin API).
Azure Cosmos DB allows us to build highly responsive and available applications worldwide, ensuring that our user's data is as close to them as possible with guaranteed low latency for both reads and writes at the 99th percentile.
We also have five well-defined consistency models to choose from (Strong, Bounded Staleness, Session, Consistent Prefix and Eventual). This gives us more flexibility in choice of consistency, as we are usually limited to either Strong or Eventual.
What is Azure Synapse?
Azure Synapse Analytics is a integrated analytics service that allows us to use SQL and Spark for our analytical and data warehousing needs. We can build pipelines for data integration, ELT and Machine Learning purposes. We can also integrate Azure Synapse with other Azure services, such as AzureML, Power BI and Azure Cosmos DB.
Synapse provides us with unified management, monitoring and security over our enterprise data lake and we can use Synapse Studio that gives Data Engineers, BI Engineers and Data Scientists a unified experience to build complete analytical solutions.
What is Azure Synapse Link for Cosmos DB?
Azure Synapse Link for Cosmos DB is a cloud native HTAP (Hybrid Transactional and Analytical Processing) capability that allows us to run near-real time analytics over our data in Azure Cosmos DB.
This is possible through the Azure Cosmos DB Analytical Store, which provides us a way to perform near real-time analytics on our data without have to engineer our own ETL pipelines to do so.
What is the Azure Cosmos DB Analytical Store?
In a nutshell, the analytical store is a isolated column store that allows us to perform analytics against our transactional data, without impacting those transactional workloads.
The transactional store is a row store that is optimized for transactional reads and writes. It's schema agnostic and allows us to iteration on our applications without have to manage the schemas and indices. This is great for performing super fast transactional reads and writes that Azure Cosmos DB is great for. However, no matter what type of applications we'll be build, we will inevitably need to perform some kind of analytics on that data.
Doing this in a Pre-Synapse world was honestly quite painful. We would have to find some way of extracting that data out of Cosmos DB into a separate data layer more suited to performing analytical workloads. This is possible through the Change Feed. For example, we could spin up an Azure Function to listen to a container for inserts, then persist that inserted document into Azure Data Lake or Blob Storage. We could even normalize our data back into a relational store such as Azure SQL.
Engineering these ETL pipelines add additional overhead and latency to our development efforts. While it was necessary, it can be pain. Some solutions require us to provision more throughput for our containers, develop complex ETL pipelines ourselves etc.
The analytical store helps address these problems. The analytical store is a column store that is optimized for analytical query performance. It can automatically sync our operational data in our row store into a separate column store which enables us to perform our analytical queries without having to build ETL pipelines ourselves.
When we enable analytical stores on our containers inside Cosmos DB, a isolated column store is created based on the operational data inside our transactional store, which is persisted separately. Since the data is automatically synced for us, we no longer need to use the Change Feed or develop our own ETL pipelines to perform analytics on our data. This syncing has a latency of around 2 minutes (unless you have a database that shares the provisioned throughput between containers, this could be up to 5 minutes).
Auto-sync will occur regardless of the intensity of our transactional traffic without impacting the performance of our transactional workloads.
We also get the benefit of having the Auto-sync automatically inferring the schema based in the latest updates from data in the transactional store for us. However, this does come with a couple of constraints. First, we are limited to 200 properties within our JSON documents with a max nesting depth of 5. We also need to have unique property names within our document (this includes the case sensitivity of our properties).
In the analytical store, there are two modes of schema representation. These are 'Well-defined schema representation' and 'Full fidelity schema representation'. Well-defined schemas present a tabular version of our data in the transactional store, while Full fidelity schemas handle the full breadth of schemas that exist within our transactional data. In well-defined schemas, properties in our documents always have the same data type and any array types must contain a single repeated type. Full fidelity schemas have no such constraints.
When the analytical store is enabled in SQL API accounts, the default is well-defined. For analytical stores in MongoDB API accounts, the default is Full Fidelity.
Enabling Azure Synapse Link
If you want to follow along with these tutorials, you'll need to create your own Azure Cosmos DB account, which you can do by following this tutorial.
Once you've done that, you'll need to enable Azure Synapse Link for your Cosmos DB account.
Go to your Data Explorer in your Cosmos DB account and simply click the 'Enable Azure Synapse Link (Preview)' button (highlighted below).

This will take a few minutes to take effect, but once that's done we can go through the process of setting up our Containers to use the Analytical Store.
Setting up our Containers to use the Analytical Store
Let's walk through the process of creating a Azure Cosmos DB container with the Analytical Store enabled. We'll use the portal for this tutorial. If you've never created a Azure Cosmos DB account before, check out this tutorial. Otherwise, let's get into it.
Go into your Data Explorer and click on 'New Container". You can set up your container with any name, partition key and throughput configuration that you like. The essential thing to note here, is to enable to Analytical Store by selecting the On radio button (highlighted below).

Once your container has been created, have a look at the Settings of your container. As you can see below, you will notice a configuration for Analytical Storage Time to Live (below).

Let's discuss what the Analytical Time-to-Live setting is.
Analytical Time-to-Live (TTL)
Time-to-Live isn't an entirely new concept for those who've worked with Azure Cosmos DB before.
TTL for our Analytical store states how long data in the analytical store should live for. This setting is isolated from the TTL setting we set for our transactional store. Since these two settings are isolated, data archiving becomes simpler for us. The Analytical store is optimized in terms of storage compared to the transactional store. We now have the possibility of being able to retain our data for longer in the analytical store by setting the Analytical TTL at a longer retention interval than that of the transactional store.
If you want to go into more details about the Analytical Time-to-Live, check out the documentation here.
Connecting Azure Cosmos DB to Azure Synapse
Now that we have our container with the Analytical Store enabled, we can connect our Cosmos DB account to a Azure Synapse Workspace.
If you haven't got a Azure Synapse Workspace, check out the following tutorial on how to create one.
From the Data Object Explorer in Synapse, we can connect to our Cosmos DB by choosing the external data source as a Linked connection.

At the time of writing, we can connect to Cosmos DB accounts that either have the SQL API or MongoDB API. The account that I'm using for this article is a SQL API account.

Once we've chosen the API, we can choose the account that we want to connect to. Give your connection a name and choose the Account Name and Database name that you want to connect to.
If you have a globally distributed Cosmos DB account, the analytical store will be available for that container in all regions of the account. Changes in our transactional store is replicated to all regions associated with your Cosmos DB account, so when we run queries against our Analytical Store, we are really running that query against the nearest regional copy of that data in Cosmos DB.

Once we've created our connection, we'll see it under the linked tab like so:

We can differentiate between containers that have the Analytical Store enabled on them from those that haven't through different icons:

For this article, we will need to create a Apache Spark pool. To do this, go to your managed pools. Click on 'Create Apache Spark pool' to begin creating one.
We can then configure our Spark pool. For the basics, we can create a pool name, node size, enable autoscaling and determine how many nodes we will need like so:

If we wish, we can also configure additional parameters, like what version of Spark we want to use and how many number of idle minutes must pass before automatically turning off our Spark pool:

Once we've set everything up, click 'Create' and we should see our Spark Pool ready to go:
Working with the Analytical Store in Azure Synapse
For the purposes of this article, I've created a simple device reading container with 10,000 documents of random device readings. Here's an example of one of those documents below:
{
"id": "6091b702-45b8-435f-8c67-c88ca68ee009",
"Temperature": 60.04,
"DamageLevel": "Medium",
"AgeInDays": 15,
"Location": "New Zealand"
}
Let's try querying our data using Spark. When querying our data, we can either load our data to a Spark DataFrame or create a Spark table. Synapse Apache Spark enables us to query our data in Cosmos DB without impacting our transactional workloads. We can insert data into Cosmos DB through Apache Spark in Azure Synapse and use Structured Streaming with Cosmos DB as both a source and sink.
I'm going to load a Spark DataFrame using PySpark. We can do this for our DeviceReadings container like so:
df = spark.read.format("cosmos.olap").option("spark.synapse.linkedService", "VelidaCosmosDB_Connection").option("spark.cosmos.container", "DeviceReadings").load()
We can see in our Notebook that our DataFrame has been created.

We can execute the following query to tidy things up a bit:
df_clean = df.drop("_rid", "_ts", "_etag")
Here I'm just dropping all the columns specific to Cosmos DB as I don't need them for this example. My new DataFrame looks a lot more tidy now:
Now that we've prepared our DataFrame, we can now use Synapse to perform our analytics. Remember that the queries that we run here target the Analytical Store, meaning that these queries have no effect on our transactional workloads.
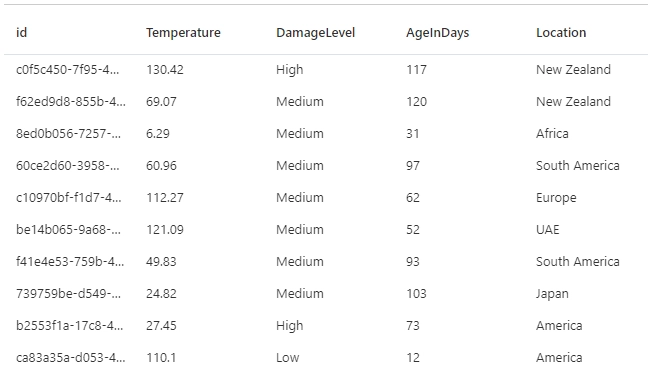
In our DataFrame, we have a column for how old the devices is in days. Let's see which ones are the oldest and see what kind of damage they've sustained in the field. For this, we can write the following query:
df_oldestdevices = df_clean.orderBy(df_clean["AgeInDays"].desc())
display(df_oldestdevices.limit(10))
After running this code, we can see the following DataFrame as an output:
Image here
I'm just using random data here, so the end result isn't very impressive. I'm just demonstrating the capability of being able to query the analytical store in Cosmos DB using Spark in Azure Synapse without it affecting my transactional workloads.
We aren't just limited to querying our data in Spark. We can also query our data in T-SQL using the Serverless SQL Pool. When we provision Azure Synapse, we immediately have a Serverless SQL pool available to us. If you want to know how to do this, check out the following tutorial.
How much is this all going to cost me?
When using Azure Synapse Link for Cosmos DB, you will pay for both the Analytical Store in Cosmos DB as well as paying for Azure Synapse Analytics.
The analytical store follows a consumption-based pricing model. You are charged for the storage retained in the analytical store and both analytical read and write operations. While pricing is separate from the transactional store, you don't provision request units as you would in the transactional store.
If you want to learn more about the pricing models for both the Analytical Store in Cosmos DB and Azure Synapse Analytics, check out the following articles:
Limitations
At the time of writing, there are some limitations to Azure Synapse Link for Cosmos DB.
Currently, Synapse Link for Cosmos DB is only available for SQL API and MongoDB API accounts. For any containers with the analytical store enabled, automatic backup and restore of your data in the analytical store isn't currently supported. If you need to restore your transactional store, the container will be restored without the analytical store enabled.
Wrapping it up
In this article, we discussed what Azure Synapse Link for Cosmos DB is and what benefits it can provide for our analytical workloads. We have also seen how simple it is to enable Synapse Link for our Cosmos DB accounts, create containers with the Analytical Store enabled and how we can link our Cosmos DB account to our Synapse workspaces.
Azure Synapse Link is ideal for enterprises looking to perform real-time analytics over their data in Azure Cosmos DB without impacting their transactional workloads. You can check out some use cases of Azure Synapse Link for Cosmos DB in this article.
If you want to learn more about Azure Synapse, Azure Cosmos DB and Big Data in general, I recommend the following resources:
- Azure Synapse Analytics
- Azure Cosmos DB
- The Missing Piece - Diving into the World of Big Data with .NET for Apache Spark
- MS Learn Course: Understand the evolving world of data
- MS Learn Course: Identify the tasks of a data engineer in a cloud-hosted architecture
Thanks for reading. If you have any questions, please feel free to comment below or reach out to me on Twitter.

Top comments (0)