In the previous post we explained the implementation details of List<T>. This time we will look at another generic collection defined in System.Collection.Generic namespace which is Dictionary<TKey TValue>.
Implementation
The most important implementation elements of the Dictionary<TKey, TValue>:
-
buckets- set of elements with similar hashes -
entries- elements of theDictionary<TKey, TValue> -
freeList- index of the first free place -
freeCount- the number of empty spaces in the array, not at the end -
count- the number of elements that are currently in theDictionary<TKey, TValue> -
version- changes as theDictionary<TKey, TValue>is modified
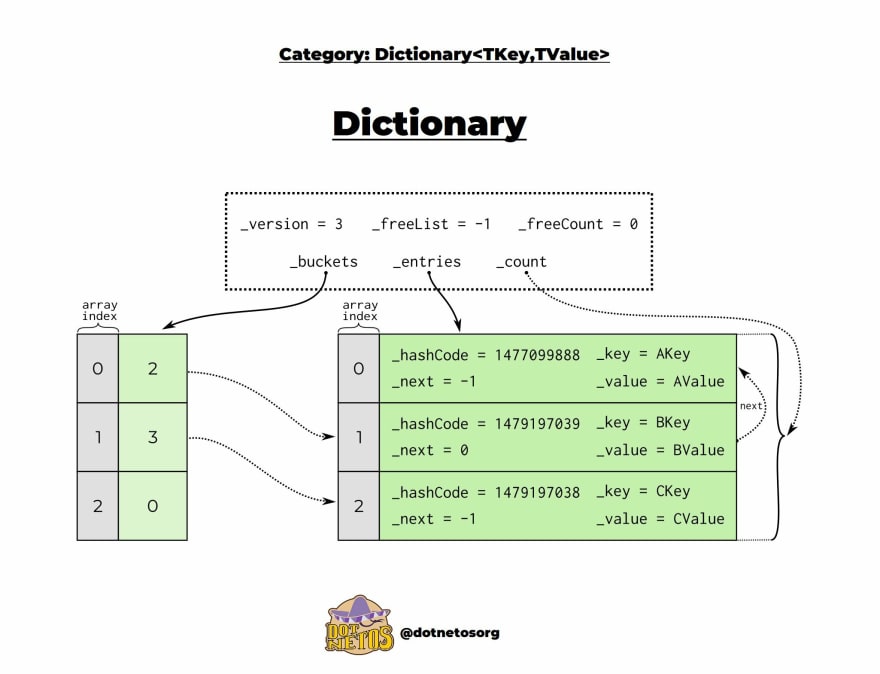
...and a few more equally important elements that Entry contains:
-
_key- key to identify element withTKeytype -
_value- value of an element withTValuetype -
_hashCode- numeric value used to identify an object in hash-based collection -
_next- describes the next item in thebucket

The dictionary uses an array of Entry structures to store data. To get a better understanding of how this really works, you need to know what exactly a hash table is.
Hash table (also called hash map) is a data structure that implements an associative array which allows you to store pairs - each pair contains a key and a value.
With the key, we are able to quickly find the value associated with the key. According to the dictionary's equality comparer the key is unique within the entire associative array.
In .NET the hash table contains a list of buckets to store values. A hash table uses a hash function to compute an index based on the key. This allows us, for example, to find the correct bucket with the value we are looking for.
The same is the situation with other operations - by calculating the hashcode we can add an element to the appropriate bucket with the index designated for it. We will continue to explain this in more detail later in this post.
The value in the bucket indicates the index in entries +1. As it is in infographic: a value of 3 points to index 2. And a value of 2 points to index 1.
The next property points to the next item that is in the same bucket. In the picture it is additionally marked with an arrow. When next is equal to -1, it means that it is the last item in the bucket.
Adding an item when the key doesn't exist
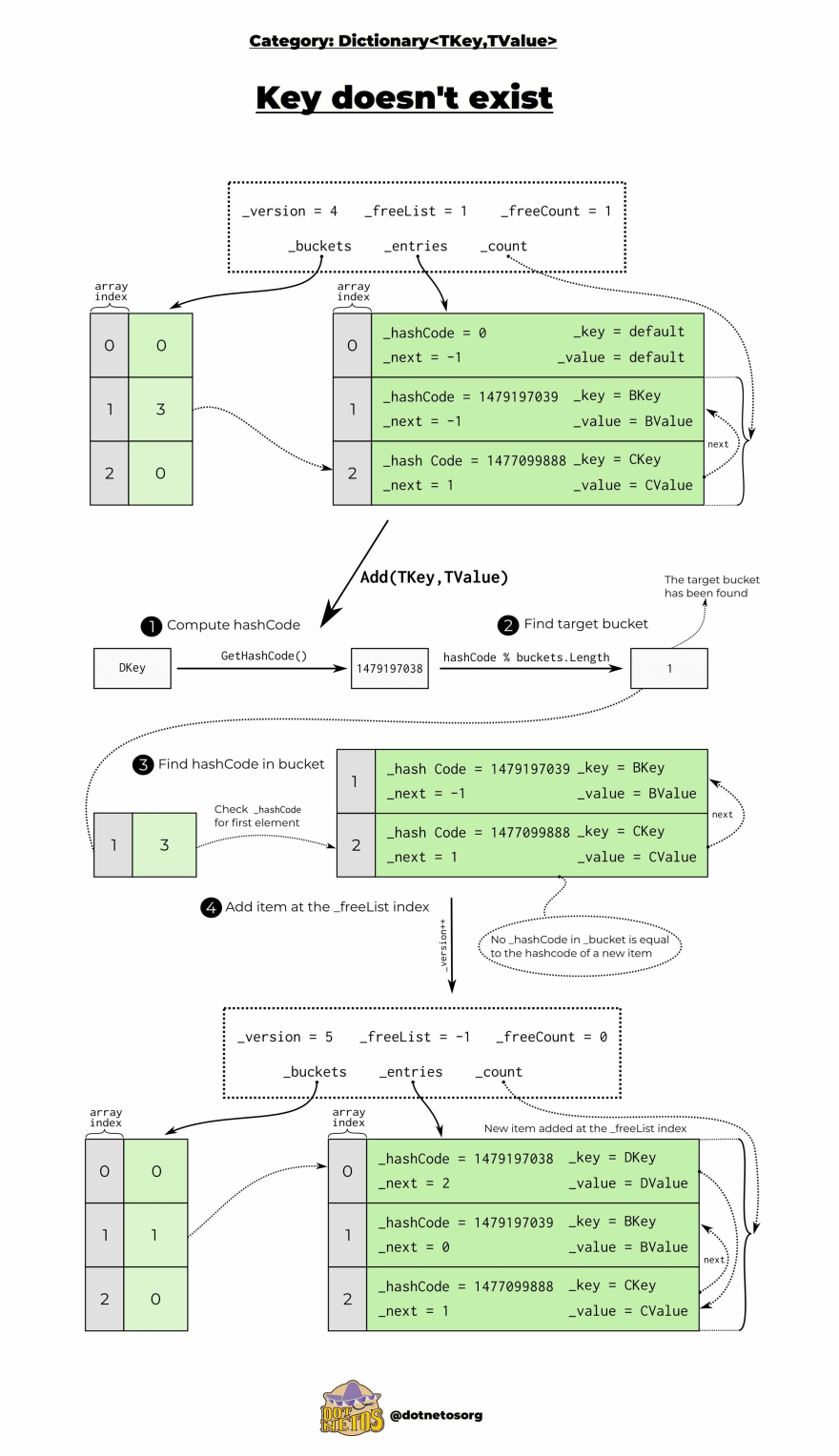
In the previous section, we mentioned that the key must be unique. Now let's look at an example in which we want to add a new Entry to our list. When the key doesn't exist and we have one free space not at the end of the array. The first operation in this case is to compute hashcode and find a suitable bucket using the formula: hashCode % buckets.Length. When we find this bucket, we compare hashCode of the new element we want to add to the array with the hashCode of the first Entry, then move on to the next one (pointed to by next) and repeat the comparison.
If none of the existing hashCodes are the same then we add a new element to the first empty space. Our version grows and the value of bucket points to the last added element. If the modulo result points to a bucket that already contains an item (we call this situation a hash collision), after adding a new element its index from the entries array is set to the value of bucket and the next field is set to point to the previous item, resulting in a chain of items.☝️
Adding an item when the key exist
Let's look at the case where we want to change the value of an existing Entry. In the first steps, nothing changes from the previous example - we calculate the hashCode and find the appropriate bucket. After that, the hashCodes of the elements in the buckets are compared. When we have verified that the hashCode of the new Entry is the same as the existing one, keys comparision occurs. If the keys are the same, value is overwritten and the version is incremented by 1. It's so simple and interesting at the same time! ✨

Resize
Let's look at another interesting situation. If we want to add an element to the dictionary and there is no more space in it, before this operation we should resize the array. The first step is to create an empty enlarged array whose size is equal to the nearest Prime Number of doubled the initial size of the array. We use Prime Numbers to minimalize probability of hash collisions. The next step is to copy the entries and calculate the hashcode for the new element and find the right bucket. Then, as in the previous examples, add the element to the first free spot of the entries array.👇

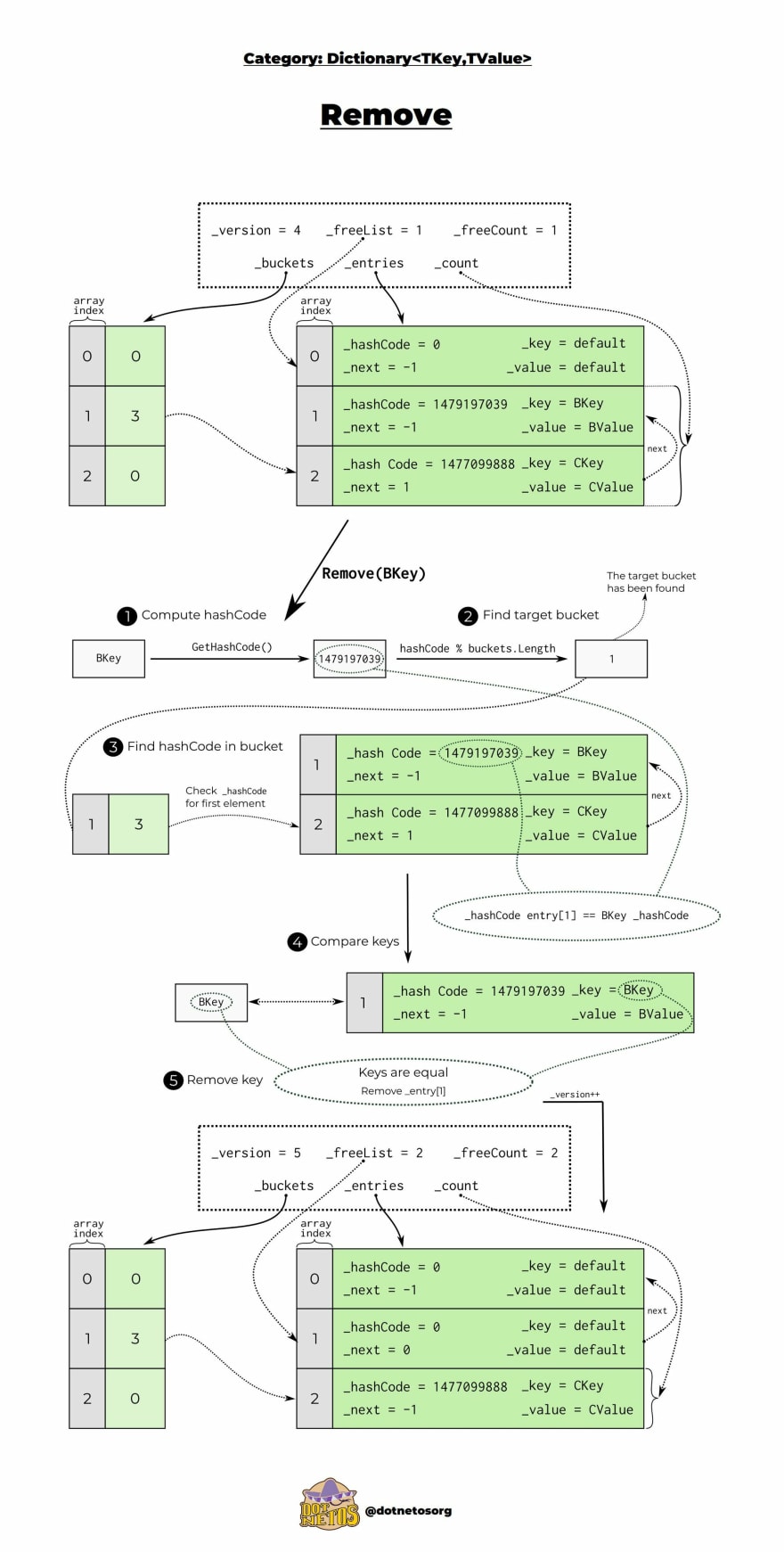
Remove
We've already learned how adding elements to the dictionary looks like, it's high time to know the implementation details of removing them. The initial steps remain the same - the hashCode is calculated and the appropriate bucket is found. Then a comparison of hashCodes takes place and a check is made to see if the keys are the same.
After that, the key is removed and the version grows. When an element from the array is removed, the space it occupies goes into the chain freelist. The Dictionary stores the index of the next element using the next property of the Entry structure. This way we know, in case we want to add a new element after deletion, which space it will occupy first - entry[1] and when adding one more element in turn - entry[0].👇
If you enjoyed this post and want to keep learning more, check out our social channels💜
Twitter
Discord
Instagram
Sources
https://github.com/microsoft/referencesource/blob/master/mscorlib/system/collections/generic/dictionary.cs
https://docs.microsoft.com/pl-pl/dotnet/api/system.collections.generic.dictionary-2?view=net-6.0

Top comments (0)