
by Igor Plekhov, Developers Support Team Lead at Skyeng company.
We have 350+ users and 400+ repositories at Github. There can be more than one admin in each repository. And they do whatever they want. Of course, afterwards, any of them can be unaware of what the other has done. When we, the Infrastructure team, got tired of suffering and managing all those things manually, we decided to go to centralized management; Infrastructure as Code.

And as a platform, we chose Terraform.
“I have blocks with letters S, H, I…”
In theory, everything seemed smooth. Terraform is a popular tool. It will be easy to find people who have experience using it.. It has state and TF makes resources to conform - we can be sure at any time that the working configuration is equal to what we’ve written. No need to browse through the web user interface anymore - look into the config and you are in.
We ran into Github’s rate limits. First of all, TF reads everything and changes what it has after that. With our size, it took about 20 minutes. And we had to wait an hour for the next possible change as we got into limits on the number of API calls.
To solve the problem with the rate limits, we broke down all the stuff into six parts:
1.Organization members
2.Repositories
3.Teams
4.Team members
5.Team repositories
6.Collaborators
From now on, typical operations are carried out in two steps. To add a new developer, run Terraform with different parameters: 1 and 4. To add a new repository, run 2 and 5. It turned out to take quite a long time. Run TF once, come back in a few minutes, run it once more. Then come back again - to reply to the request’s author: everything done. Or it was not done if there was an error somewhere in the config. One time we have been given a pull request where, in several places, a Russian с was used instead of an English c. They look like two peas in a pod, yet they are different. It took a couple of hours to hunt it down.
Horrible syntax. Description of anything is quite a mouthful. Here is an example:


As such things are usually copy-and-pasted, and then *something is being changed, it’s quite simple to change that *something incompletely or to remove something excessive. Put a dash instead of an underscore - and nobody will notice it. Any error costs minutes of waiting. Imagine a debug with minutes between steps...
It’s impossible to reference resources by names, it’s only allowed by identifiers. Resources - repositories - are described in a file, while variables with their ID in another. Users and teams alike. Also, a repository’s parameters are in different places, as well as a list of teams who have access to it. And collaborators are somewhere in a third location. When a typical question arises - who has access to this repo? - try to gather everything together.
The approach “look into the config and you are in” does not work. “Teams’ repositories” is a relation of many-to-many. Everything is in a single file of thousands of lines. How do you sort such a list? By repositories? By teams? The answer is: there is no way. New records are added to the end or in the middle at random. Collecting everyone who has access to a particular repo is a distinct task.
In a few months after deployment of TF, it was especially interesting to get to know that some repositories were still made manually. And now when demanded to give someone access to them, we cannot do that as Terraform knows nothing about it! Sure, this issue can be solved: remove repo and make it again with TF, or reinitialize TF itself. But...

Why the hell it’s so hard!
Adding a user to an organization is just one API call. Give rights to a team on a repo - the same. Finally, Terraform started to crash on the management of teams with the words like it’s about to remove 800 resources, then add 801 of them, and for some reason it cannot do that. Then we commenced by thinking about how it would be in an ideal world.
- Changes are applied pointedly.
- Simple syntax, comprehensible without any manuals. No excessive words like resource, value and identifiers like 123456 - which nobody knows where to get them from.
- All the parameters of an entity - e.g. repository - lay in one place.
- One repo / team / organization - one file.
Converted to YAML
Organization

Team

Repository

Wished to find a turnkey solution, but have not succeeded - then had to write it out
Maybe TF is a clever thing. But in our case, it turned out to be a Procrustean bed. We went to make our own solution with Ansible, which we use heavily to manage our infrastructure.
It sorts typical tasks out in mere seconds. It takes only a few API calls, a few dozens for big projects. It’s easy to use in CI/CD. All parameters are collected in a single file, so all changes are local, they are easily trackable. Now it’s a real thing - look in a config file and you are in. Everything you need is at your fingertips. Link to code is at the very end and now a pair of examples.
Now, we can make a new repository like this:

To do something with a team like this:
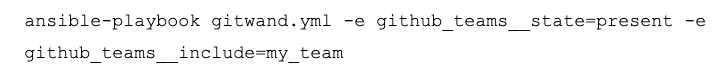
If it’s necessary to update all the teams, we simply omit the parameter:
![]()
And a sudden cherry on top of the cake. We have LDAP, and whenever it’s possible, we use it for authentication. There the username of a person consists of their full name. And this is much better than a nickname invented in a stormy youth, understandable only by its owner. Now we can use people’s real names while managing Github too.
If you’d like to try our solution
It can be found here.

Top comments (0)