Question 1: Why Do We Need Indexes in a Database?
Imagine a library with 10 million books, and you need to find The Road to Architect. If you check each book one by one, how long would that take? Instead, librarians have a system:
- History books are on the first floor, literature on the second, IT books on the third…
- IT books are further divided into software and hardware…
- Software books are sorted alphabetically…
This way, finding a book becomes much faster. Similarly, when a database stores 10 million records and you need to find name="Architect", scanning one by one would be painfully slow. That's why we use indexes to speed up lookups.
Question 2: Hash vs. Tree-Why Use a Tree Structure for Indexes?
There are two common data structures used to speed up lookups:
- Hashing (e.g., HashMap)-Average time complexity for search/insert/update/delete is O(1).
- Tree structures (e.g., balanced binary search trees)-Average time complexity for operations is O(log(n)).
Clearly, a hash-based index is faster than a tree-based index. So why do databases still prefer tree-based indexes?
It all comes down to SQL query requirements.
- If you only need single record lookups, like SELECT * FROM t WHERE name="Architect";, hash indexes are indeed the best choice.
- However, for sorted queries, such as: GROUP BY, ORDER BY and Range comparisons (<, >)
A hash index becomes inefficient, degrading to O(n) complexity. On the other hand, tree structures retain O(log(n)) efficiency due to their ordered nature.
Key takeaway: Database indexes must be designed to meet query patterns, not just raw performance metrics.
Also, note that InnoDB doesn't support manually created hash indexes. Instead, it has an adaptive hash index, which is managed automatically by the database engine.
Question 3: Why Do Databases Use B+ Trees for Indexes?
To understand why, let's first look at some tree structures.
- Binary Search Tree (BST)
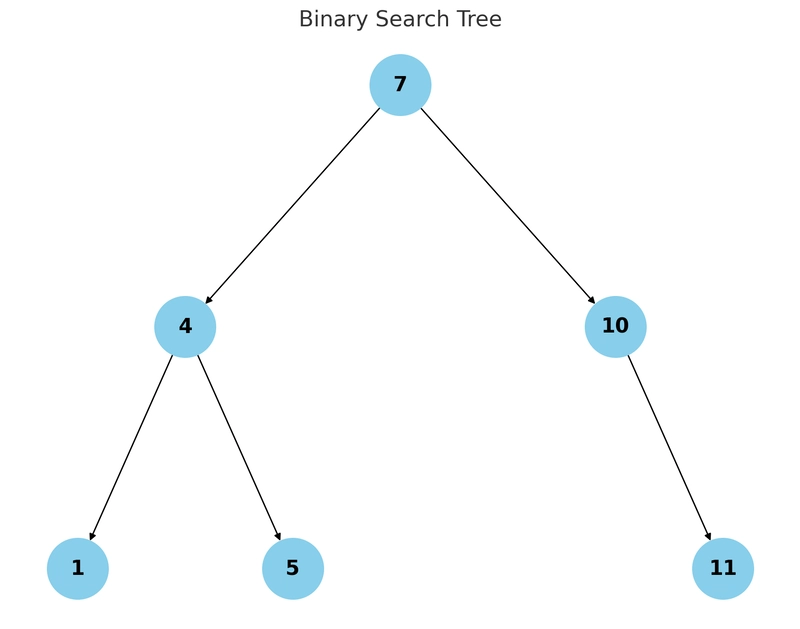
A BST is a simple and well-known data structure, but it's not suitable for database indexing because:
- As the dataset grows, the tree height increases, making searches slower.
- Each node stores only one record, leading to excessive disk I/O.
- B-Tree
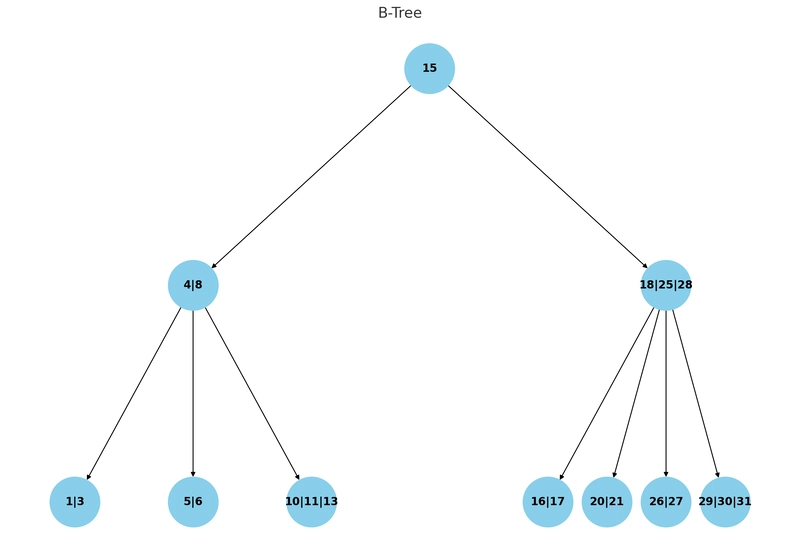
B-Tree improve on BST:
- Instead of binary splits, they use m-way branching.
- Both leaf and non-leaf nodes store data.
- You can retrieve all records using in-order traversal.
The key advantage of B-Trees is their efficient use of the locality principle:
- Memory is fast, but disk reads are slow.
- Disk prefetching means data is read in pages (e.g., 4KB per page in OS, 16KB in MySQL).
- Locality principle: If a program accesses data, it's likely to access nearby data soon.
Since B-Trees store multiple records per node, they reduce the number of disk I/O operations, making lookups faster.
- B+Tree
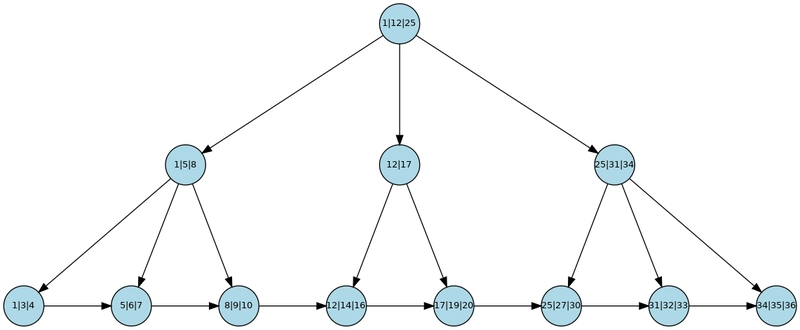
The B+ Tree is an enhancement of the B-Tree:
- Non-leaf nodes do not store actual data-only keys.
- All data is stored in leaf nodes at the same level.
- Leaf nodes are linked, allowing for fast range queries without in-order traversal.
Why is B+ Tree better?
- Faster range queries-Find min and max, then traverse the linked list.
- More compact indexing-Non-leaf nodes store only keys, making the index more memory-efficient.
- Lower tree height-With m-way branching, B+ Trees have much lower depth than BSTs.
How Does B+ Tree Reduce Tree Depth?
Let's estimate:
- Assume each node is 4KB.
- A key size is 8 bytes, so one node can store 500 keys.
- The tree has an m-way branching factor of ~1000.
| Tree Level | Nodes | Total Keys | Approx Size |
|---|---|---|---|
| 1 | 1 | Row 1 500 | 4KB |
| 2 | 1000 | 500000 | 4MB |
| 3 | 1000000 | 500M | 4GB |
With just 3 levels, a B+ Tree can handle 500 million records while keeping the index small (~4GB). This makes it an excellent choice for large databases.
Summary
- Indexes accelerate database queries.
- Hash indexes (O(1)) are faster for lookups, but tree indexes (O(log(n))) are better for range queries.
- InnoDB does not support manual hash indexes but uses adaptive hash indexing.
- Disk prefetching and locality principles make B-Trees highly efficient for database indexing.
- B+ Trees outperform B-Trees because they:
- Have faster range queries due to leaf node links.
- Store actual data only in leaf nodes, optimizing memory usage.
- Have lower depth, enabling faster lookups and less disk I/O.
The B+ Tree is the standard for database indexing because it balances efficiency, scalability, and query flexibility.

Top comments (0)