Database indexes are divided into Primary Indexe and Secondary Indexe. How do InnoDB and MyISAM utilize B+ trees to implement these two types of indexes, and what are the differences between them?
Question 1: What is the index structure of MyISAM?
In MyISAM, the index structure is separate from the data rows, meaning it uses what is called a non-clustered index. The primary index and secondary index in MyISAM don’t have any significant differences:
- There is a contiguous storage region for row records.
- In a primary index, the leaf nodes store the primary key along with the corresponding row record pointer.
- In a secondary index, the leaf nodes store the indexed column and a pointer to the corresponding row record.
Note: MyISAM tables don’t necessarily require a primary key.
The primary and secondary indexes are two independent B+ trees. When you perform a search using an indexed column, the system first locates the leaf node in the B+ tree, then uses the pointer to find the corresponding row record.
For example, consider the table t(id PK, name KEY, sex, flag); which contains four records:
1, joe, m, A
3, bob, m, A
5, king, m, A
9, shiho, f, B
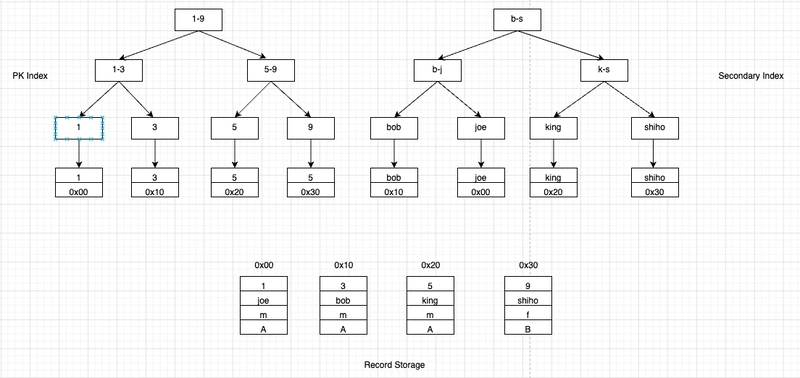
The B+ tree indexing structure looks like this:
- Row records are stored separately.
- id is the PK, with an index tree for id, and the leaf points to the row record.
- name is a KEY, with an index tree for name, and the leaf also points to the row record.
Question 2: What is the index structure of InnoDB?
In InnoDB, the primary index and row records are stored together, which is why it's called a clustered index:
- There is no separate area for storing row records.
- In a primary index, the leaf nodes store the primary key and the row record itself (not just the pointer).
Note: This is why InnoDB’s primary key queries are very fast.
Because of this structure, InnoDB tables must have a clustered index:
- If a table defines a primary key, the primary key becomes the clustered index.
- If there is no primary key, the first non-null unique column is used as the clustered index.
- If there is no unique column, InnoDB creates a hidden row-id as the clustered index.
You can only have one clustered index in InnoDB, because row data can only be physically stored once on the disk.
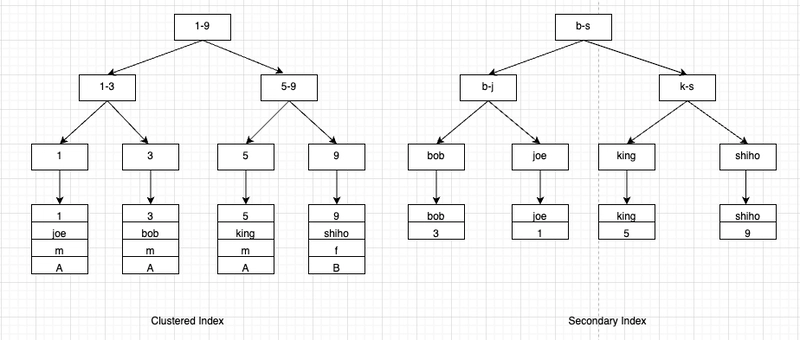
InnoDB’s secondary indexes can be multiple. They differ from the clustered index:
- The leaf nodes of a secondary index store the primary key (not just a pointer).
Question 3: Why does InnoDB recommend using a progressively increasing primary key?
In InnoDB, since row data and indexes are combined, using a progressively increasing primary key avoids index fragmentation during inserts, preventing excessive row movement in the index.
Question 4: Why is it not recommended to use long columns as primary keys in InnoDB?
Let’s consider a scenario where you have a user center that includes fields like ID card number, MD5 hash of ID card, name, birth date, etc. These fields are queried frequently and require transactional support, so you must use the InnoDB storage engine.
What’s the best way to design the data table? A simple design would be:
user(id_code PK, id_md5(index), name(index), birthday(index));
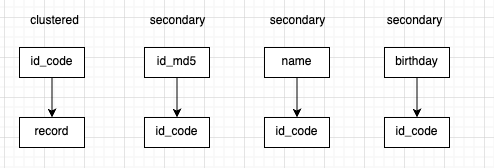
Now, the index tree and record structure looks like this:
- id_code as a clustered index, pointing to the row records.
- Other indexes store id_code values.
Since id_code (ID card number) is a long string, every index needs to store this value. When you have a large dataset and limited memory, MySQL's buffer pool will store fewer indexes and row data, increasing the chance of disk I/O.
Note: This also increases the disk space used by the indexes.
A better solution is to add an auto-increment id column with no business meaning as the primary key:
user(id PK auto inc, id_code(index), id_md5(index), name(index), birthday(index));
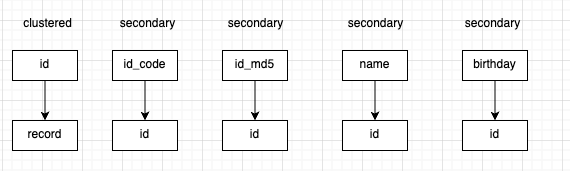
This way, the buffer pool can store more indexes and row data, reducing disk I/O frequency and improving overall performance.
Question 5: What potential problem arises from InnoDB's secondary index storing the primary key value?
When using a secondary index in InnoDB, you might encounter a problem called “covering index”, or “back-to-table queries”.
What are back-to-table queries? Let’s use the earlier example:
t(id PK, name KEY, sex, flag);
- The id column is the clustered index (PK), and the leaf nodes store row records.
- The name column is a secondary index, and its leaf nodes store the primary key (id).
Since the secondary index does not point directly to the row record, we must scan the index twice to get the data:
- First, we locate the primary key value (e.g., id=5) in the secondary index.
- Then, we use the primary key to find the corresponding row record in the clustered index.
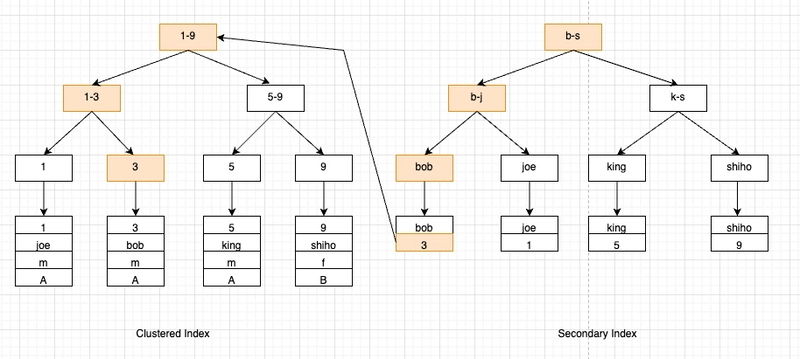
This is known as a back-to-table query. It’s slower than scanning a single index tree. Example query:
SELECT id, name, sex FROM t WHERE name='bob';
The process:
- First, scan the secondary index to get the primary key id=5.
- Then, scan the primary index to retrieve the actual row.
This process is slower than just scanning the index tree once.
Question 6: How to optimize back-to-table queries?
The common solution is to use covering indexes. What is a covering index?
According to the SQL Server documentation:

According to the SQL Server documentation (also applicable to MySQL), a covering index allows you to retrieve all the required data from a single index without needing to go back to the table.
To implement a covering index, you can create a composite index that includes all the columns used in the query. For example, instead of using a single column index on name, you can upgrade it to a composite index:
create index idx_name_sex on t(name, sex);
Now, the query:
select id, name, sex from t where name='bob';
Can be handled by the covering index, avoiding the need to go back to the table, thus improving performance.

Top comments (0)