
Kafka connect
O kafka connect é um serviço do kafka que serve para pegar dados de um serviço e jogar para um outro.
Por exemplo pegar os dados do meu banco de dados e passar para um arquivo txt, ou para um elastic search ou algo desse tipo
O kafka connect é um cluster com diversas maquinas que realizam essas tarefas, essas maquinas são chamadas de worker sendo que cada worker pode lidar com mais de uma tarefa.
Dashboard do kafka
Irei deixar o yml do compose no final do post. Mas uma coisa q ele faz é colocar o control center da confluent na porta 9021 e é isso q vamos abrir.
No menu lateral do dashboard tem a opção de connectors onde ele mostra todos os clusters do kafka connect conectados atualmente, de inicio não vai ter nenhum, ainda temos que fazer essa conexão, quando subir o docker-compose vai perceber que ele vai criar duas pastas no seu diretório atual data e es01 essas pastas vão ser usadas para manter as configurações. Porem além delas também vamos criar uma pasta connectors com um arquivo elasticsearch.properties, nesse arquivo vamos definir algumas configurações como o nome do desse conector, a classe dele, os tópicos que esse conector vai ouvir, a url de conexão, o tipo dos documentos e o conversor de valores para que os dados cheguem como json
name=elasticsearch-sink
connector.class=io.confluent.connect.elasticsearch.ElasticsearchSinkConnector
topics=route.new-direction,route.new-position
connection.url=http://es01:9200
type.name=_doc
value.converter=org.apache.kafka.connect.json.JsonConverter
value.converter.schemas.enable=false
schema.ignore=true
key.ignore=true
transforms=InsertField
transforms.InsertField.type=org.apache.kafka.connect.transforms.InsertField$Value
transforms.InsertField.timestamp.field=timestamp
Com esse arquivo criado podemos voltar ao dashboard na parte de conectores e adicionar um novo conector fazendo o upload dele. Se tudo der certo (caso algo dê errado escrevi o que aconteceu de errado comigo e como solucionei no final do post) na parte de connectors ele vai exibir um connector como running

Se formos agora no Kibana, que está na porta 5601 podemos abrir o menu lateral e ir em Stack Management 
Nessa pagina temos o Index Management que vai nos mostrar já os dois tópicos que selecionamos pra ele escutar. E temos também o Index Patterns.
Onde vamos criar um novo index-patern com base nos nossos tópicos, se eles já tiverem recebido uma mensagem com o kibana rodando quando criarmos o pattern ele já vai vai vir com os campos desse tópico
Agora se formos no menu lateral do kibana e clickar na parte de analytics ele já vai passar a mostrar todas as mensagem que recebemos em cada tópico

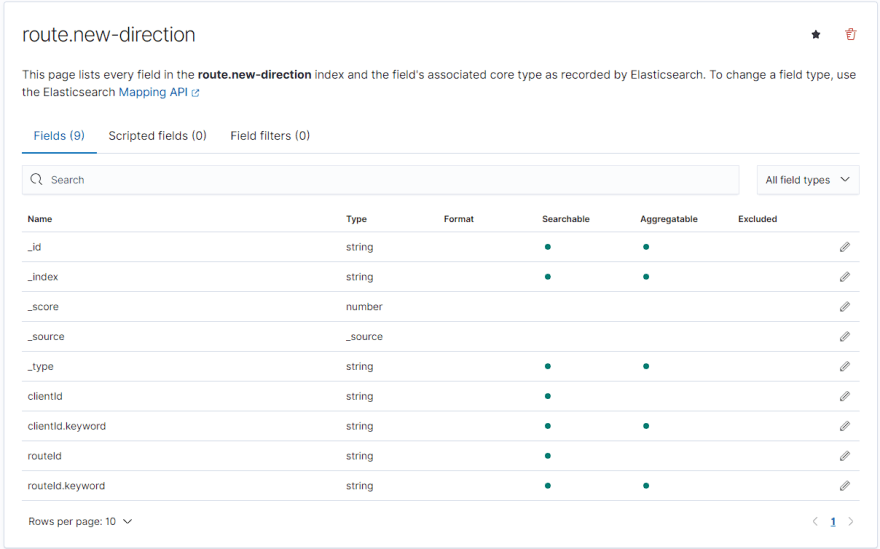
Adicionando os tipos dos campos
Para ficar com os index melhor formatados apaguei os que foram gerados automaticamente e fui na parte de devTools do menu do kibana, lá escrevi os seguintes comandos.
PUT route.new-position
{
"mappings": {
"properties": {
"clientId": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"routeId": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"timestamp": {
"type": "date"
},
"finished": {
"type": "boolean"
},
"position": {
"type": "geo_point"
}
}
}
}
PUT route.new-direction
{
"mappings": {
"properties": {
"clientId": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"routeId": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"timestamp": {
"type": "date"
}
}
}
}
Agora o position vai ser lido como uma localização ao invés de numero como estava antes e podemos visualizar ele no mapa
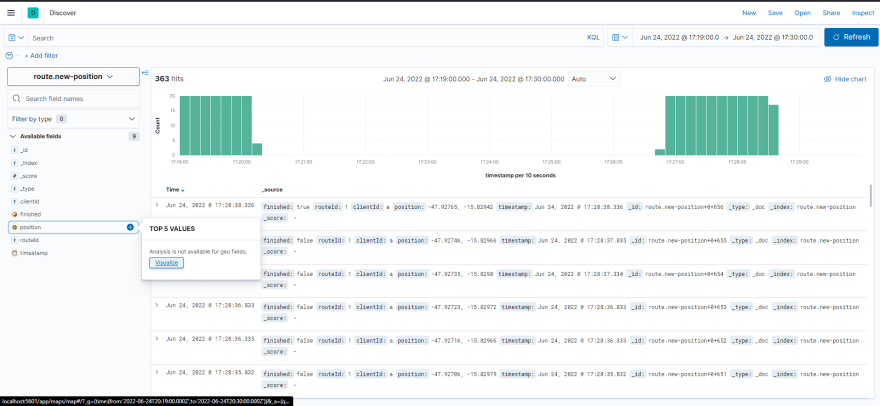
clickando em visualize vamos para o mapa onde podemos visualizar esses positions no mapa

Criando visualizações
Na opção de visualizações vamos criar uma nova visualização do tipo Lens

Dentro da parte de visualizações podemos adicionar os dados que queremos e exibir-los da forma desejada

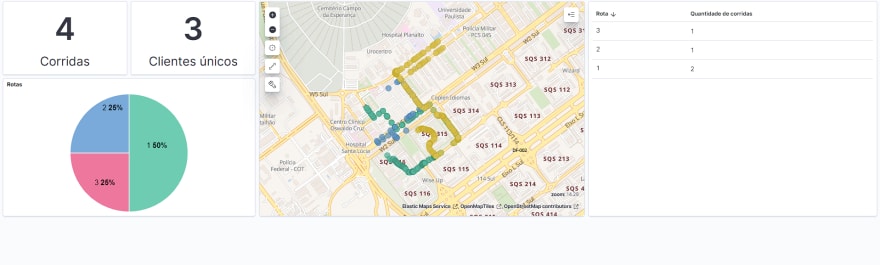
Então por exemplo, coloquei o contador de records do tópico new-direction, mudei seu tipo para métrica e coloquei o nome de corridas e então salvei.
Criei também a visualização de mapa e por fim criei um dashboard com todas essas informações
Docker-compose
Aqui o docker compose que usei para aprender, lembre de trocar o ip para o seu próprio, caso não saiba qual o ip pode rodar esse comando
docker run -it --rm alpine nslookup host.docker.internal que o docker te informa qual o ip
version: "3"
services:
zookeeper:
image: confluentinc/cp-zookeeper:latest
environment:
ZOOKEEPER_CLIENT_PORT: 2181
extra_hosts:
- "host.docker.internal:192.168.65.2"
kafka:
image: confluentinc/cp-kafka:latest
depends_on:
- zookeeper
ports:
- "9092:9092"
- "9094:9094"
environment:
KAFKA_BROKER_ID: 1
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_INTER_BROKER_LISTENER_NAME: INTERNAL
KAFKA_LISTENERS: INTERNAL://:9092,OUTSIDE://:9094
KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka:9092,OUTSIDE://host.docker.internal:9094
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT,OUTSIDE:PLAINTEXT
extra_hosts:
- "host.docker.internal:192.168.65.2"
kafka-topics-generator:
image: confluentinc/cp-kafka:latest
depends_on:
- kafka
command: >
bash -c
"sleep 5s &&
kafka-topics --create --topic=route.new-direction --if-not-exists --bootstrap-server=kafka:9092 &&
kafka-topics --create --topic=route.new-position --if-not-exists --bootstrap-server=kafka:9092"
control-center:
image: confluentinc/cp-enterprise-control-center:6.0.1
hostname: control-center
depends_on:
- kafka
ports:
- "9021:9021"
environment:
CONTROL_CENTER_BOOTSTRAP_SERVERS: 'kafka:9092'
CONTROL_CENTER_REPLICATION_FACTOR: 1
CONTROL_CENTER_CONNECT_CLUSTER: http://kafka-connect:8083
PORT: 9021
extra_hosts:
- "host.docker.internal:192.168.65.2"
kafka-connect:
image: confluentinc/cp-kafka-connect-base:6.0.0
container_name: kafka-connect
depends_on:
- zookeeper
- kafka
ports:
- 8083:8083
environment:
CONNECT_BOOTSTRAP_SERVERS: "kafka:9092"
CONNECT_REST_PORT: 8083
CONNECT_GROUP_ID: kafka-connect
CONNECT_CONFIG_STORAGE_TOPIC: _connect-configs
CONNECT_OFFSET_STORAGE_TOPIC: _connect-offsets
CONNECT_STATUS_STORAGE_TOPIC: _connect-status
CONNECT_KEY_CONVERTER: org.apache.kafka.connect.storage.StringConverter
CONNECT_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_INTERNAL_KEY_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_INTERNAL_VALUE_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_REST_ADVERTISED_HOST_NAME: "kafka-connect"
CONNECT_LOG4J_ROOT_LOGLEVEL: "INFO"
CONNECT_LOG4J_LOGGERS: "org.apache.kafka.connect.runtime.rest=WARN,org.reflections=ERROR"
CONNECT_LOG4J_APPENDER_STDOUT_LAYOUT_CONVERSIONPATTERN: "[%d] %p %X{connector.context}%m (%c:%L)%n"
CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: "1"
CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: "1"
CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: "1"
# # Optional settings to include to support Confluent Control Center
# CONNECT_PRODUCER_INTERCEPTOR_CLASSES: "io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor"
# CONNECT_CONSUMER_INTERCEPTOR_CLASSES: "io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor"
# ---------------
CONNECT_PLUGIN_PATH: /usr/share/java,/usr/share/confluent-hub-components,/data/connect-jars
# If you want to use the Confluent Hub installer to d/l component, but make them available
# when running this offline, spin up the stack once and then run :
# docker cp kafka-connect:/usr/share/confluent-hub-components ./data/connect-jars
volumes:
- $PWD/data:/data
# In the command section, $ are replaced with $$ to avoid the error 'Invalid interpolation format for "command" option'
command:
- bash
- -c
- |
echo "Installing Connector"
confluent-hub install --no-prompt confluentinc/kafka-connect-elasticsearch:10.0.1
#
echo "Launching Kafka Connect worker"
/etc/confluent/docker/run &
#
sleep infinity
extra_hosts:
- "host.docker.internal:192.168.65.2"
es01:
image: docker.elastic.co/elasticsearch/elasticsearch:7.11.2
container_name: es01
environment:
- node.name=es01
- cluster.name=es-docker-cluster
- cluster.initial_master_nodes=es01
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- ./es01:/usr/share/elasticsearch/data
ports:
- 9200:9200
extra_hosts:
- "host.docker.internal:192.168.65.2"
kibana:
image: docker.elastic.co/kibana/kibana:7.11.2
container_name: kib01
ports:
- 5601:5601
environment:
ELASTICSEARCH_URL: http://es01:9200
ELASTICSEARCH_HOSTS: '["http://es01:9200"]'
extra_hosts:
- "host.docker.internal:192.168.65.2"
Problemas que encontrei
Ao tentar rodar o docker-compose depois de criar o es01 precisei alterar as permissoes dessa pasta pois ela não estava deixando o docker do elastic criar os arquivos dentro dela
sudo chown -R 1000:1000 es01Ao subir o elasticsearch ele reclama do meu vm.max_map_count, tive que redefinir essa variavel no meu sistema rodando o comando:
sysctl -w vm.max_map_count=262144, porem isso só dura a sessão atual, se quiser uma solução mais duradoura nessa pagina encontrei tambem
https://stackoverflow.com/questions/51445846/elasticsearch-max-virtual-memory-areas-vm-max-map-count-65530-is-too-low-inc

Top comments (0)