(You want to read this post in Korean? Check out here!)
In my last post, I learned about how the Internet sends information at a high level. The Internet uses a method called ‘packet switching’, which means breaking down data into smaller segments (packets) and sending each of them via different routes’. This packet switching method is used as it contributes to the reliability and the efficiency of communication on the Internet.
I also learned more about a packet. The structure of a packet is described by a very popular protocol, ‘Internet Protocol’ or IP. As such, we interchangeably call a packet an IP packet. The IP packet has three segments – a set of headers, payload, and footer. Among them, a set of headers has the most important data for communication on the Internet, such as addresses of the sender and the receiver.
Today I am going to focus more on IP addresses – how an IP address looks like, what information that an IP address contains, and what fields in an IP header are related to an IP address.
Part 3-2: Can we talk more about the IP address?
An IP address is a unique identification of each device on the Internet. All devices on the Internet have unique IP addresses and this fact allows the Internet to accurately exchange data between two entities. Then how does an IP address look like?
An IP address is just a bunch of numbers in a human’s eye. On the Internet, an IP address is a string of bits as every data is represented in bits there. Like how the format of our postal address has a certain hierarchy (ex: street, address, state, country), the numbers in an IP address are organized in a hierarchy.
This hierarchical structure of an IP address is slightly different depending on which version of IP is used. There are two major versions of IP: IPv4 and IPv6.
(1) What is IPv4? And what is an IPv4 address?
IPv4 is the fourth version of IP and this is the version that was selected as a formal standard version of the IP for the first time in the early 1980s. Previous versions of IP were experimental and had design issues to be used at scale.
IPv4 describes the address of a device as a 32 bits long integer value. An IPv4 address is written in a dot-decimal notation, which consists of four 8 bits(octets) as such total of four 4 bytes. Each octet is expressed in a decimal number and is separated by a period.

The bytes of the IPv4 address are further classified into two parts: the network part and the host part
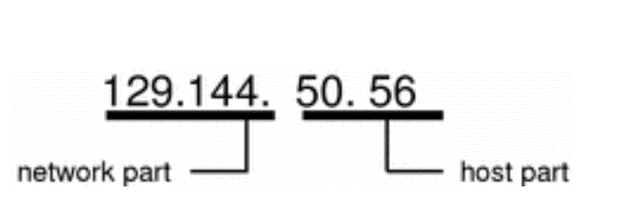
(A) What information does an IPv4 address contain?
(a) Network Part
Let’s take a look into each part to understand what information that each part contains. The network part specifies the unique number assigned to a network. This part is used to route your packets to a network that the destination server is located in. Though the image above mentions the first two bytes of the IPv4 address represent the network information, the size can vary depending on what type of class that your network is in.
(a)-1: What is the network class/network address class?
This network address class concept comes from the network addressing architecture calls ‘Classful Network’. This architecture divides the IPv4 address space into five address classes (Class A, Class B, Class C, Class D, and Class E).
This concept was introduced due to the expansion of the network. Initially, using the first 8 bits was enough to indicate all existing networks as there were only a few large networks and it was before local area networks were popular. Yet as time passed by, people realized that they need another way to address the scalability issue with the network address. As such, the idea of expanding the definition of the network part to include more bits came up.
This idea allowed the expression of more networks while ensuring compatibility with the existing large networks which were using 8 bits to express the network part. Depending on the type of the network class, the network part has more than 8 bits. But this classful network architecture was discontinued as this design was not efficiently using bits to meet the demand of IP addresses. As such this architecture was discontinued and was substituted by another architecture called Classless Inter-Domain Routing (CIDR) in 1993. Though the architecture is discontinued, the concept of address class is still used.
Let’s take a quick look at different address classes starting with Class E before we learn more about the second part of the IPv4 address, the host part.
Class Eis reserved for future or experimental purposes only for research and development (R&D) or study. (Figure 3)Class Dis reserved for Multicasting. Multicasting is a method of sending packets to a group of interested receivers in a single transmission. There can be one sender and a group of receivers (one to many) or many receivers and a group of receivers (many to many). The opposite concept is Unicasting where there are one sender and one receiver in the data transmission process. And Class A, B, and C are reserved for unicasting. (Figure 3)-
Class Cnetwork addresses are for small organizations. Because the class C network address is for a small organization, which means not many nodes exist in the organization, the class C IPv4 address uses the first 3 bytes to represent the network address and the last byte to represent node addresses. This means there can be up to almost 16.7 million (2^24) networks but each network can have only 256(2^8) nodes. In summary, a Class C IPv4 address contains the information below. (Figure 3)Net.Net.Net.Node
-
Class Bnetwork addresses are for medium-sized organizations. A Class B network address uses the first two bytes for the network, and the last remaining part for the host. A Class B IPv4 address contains the network and the host information in the below format. (Figure 3)Net.Net. Node.Node
-
Class Anetwork addresses are for large organizations. A Class A network address uses the first byte for the network and the remaining 3 bytes for nodes. As such, each network can have about 16.7 million number (2^24). We can read a class A network address like below. (Figure 3)Net.Node.Node.Node
(If you want to learn more about the address class, please check the ‘address class’ section in references)
 (Figure 3)
(Figure 3)
(b) Host Part
Okay, as we learned about what kind of information the network part contains, let’s look at the host part. The host part uniquely identifies a particular machine on a specific network. Let’s say you have five different machines connected to your network. Each of the devices will have the same value for the network part, but it has a different value for the host part.
(2) What is IPv6? What is an IPv6 address?
Since its creation, the IPv4 address served its purpose well; it uniquely identified each device on the Internet. But as the Internet usage expanded unprecedentedly, the number of addresses that IPv4 can generate started to run out. The number of discrete IPv4 address values is about 4.3 billion. Yet, people started to see more and more devices being rapidly added to the Internet and realized that 4.3 billion unique address values would not be sufficient. (Officially, all IPv4 addresses were used on November 25th, 2019).
As such, IETF (Internet Engineering Task Force) initiated the development of a suite of protocols, now known as IPv6, around 1992.
(A) IPv6 Address Representation & Abbreviation
Then how does IPv6 define the format of a source/destination address? The IPv6 address is 128 bits in length and consists of eight 16 bits. Each of 16 bits is expressed in a hexadecimal number and there is a total of 8 groups, each of which is separated by a colon.

(IPv6 address example)
But as you can see from the above example, the IPv6 address can be quite long and the length can decrease the readability. To solve this issue, we can abbreviate it. The key point here to omit repetitive 0s. If there are leading zeros, like 0001, in the above example, you can remove three zeros in front of 1.
3FFE:0000:0000:1:0200:F8FF:FE75:50DF
Also, you can use a two-colon(::) notation to represent contiguous 16-bit fields of zeros. For instance, the above example can be shortened one more time after removing any leading zeros in each section.
3FFE::1:0200:F8FF:FE75:50DF
Usually, when only one group consists of zeros and if it is not the last group, a single zero is used instead of a two-colon. When the last group is all zeros, you can use a two colon. For instance, let’s say there is an IPv6 address that looks like this.
2001:0db8:3c4d:0015:0000:d234::3eee:0000
This can be shortened as
2001:0db8:3c4d:0015:0:d234::3eee::
(B) What information does an IPv6 address contain?
As we learned about how an IPv6 address is represented, let’s learn about what information this address contains. Similar to an IPv4 address, the IPv6 address is also split into two components: a network component and a host(node) component.
This time the first 64 bits are the network part, and the lower 64 bits are the node part.

(a) Network Part
The network part contains information about the network. As I briefly mentioned above, the classful networking architecture was deprecated around 1993 due to its inefficient usage of bits. In other words, this architecture was discontinued as it was not suitable to meet the demand of scalability that the Internet needs. As the whole point of IPv6 is to give a unique address to all devices that exist and will exist in the world, IPv6 didn’t use the classful networking architecture. As such the networking part does not contain the address class information.
Instead, the upper 64 bits contain a global network address that is used for routing over the Internet and the id of a subnet on an internal network which is controlled by the admin of the internal network. The first 48 bits are for the global network address and the remaining 16 bits are to hold the id of a subnet.
(b) Host Part
The host part, the lower 64 bits, contains the address of a physical device(node), MAC address.

As IPv6 uses 128 bits to represent an address, this protocol can generate about 340 undecillion (2^128) unique addresses. How big this number is? Apparently, this is more than enough for every grain of sand on Earth to have its own IP address.
Currently, IPv4 is more commonly used, but the adoption of IPv6 is increasing fast. We are still in the middle of the migration process, and this process is going to take a while (expected to take one or two more decades). Most of the recently created devices support both IPv4 and IPv6.
Summary
In this post, I deep dived into the IP address – different versions of IP (IPv4 and IPv6), how each IP version defines the structure of an address, and what information that an IP address contains. If you remember my last post, I shared an image of an IP packet (below image) and mentioned that the header contains all fields that are related to an address.

Can you now guess what fields are related to IP address?
Yes, the first one, Version, Source IP Address and Destination IP address are the ones. Version contains 4 or 6 depending on which version of IP protocol was used in a packet, and source & destination IP address fields contain the address of a sender and of a receiver respectively.
In my next post, I am going to connect what we just learned about IP address with a bigger picture of how the Internet sends and receives data.
Next Topic
- Part 3-3:
- What is Domain Name System (DNS) and how is it used on the Internet?
- How does a router use an IP address?
- What are the problems with IP?
References:
- IP Address
-
IPv4 Address
-
Address Space
- https://www.tutorialspoint.com/ipv4/ipv4_address_classes.htm
- http://www.steves-internet-guide.com/ipv4-basics/
- https://www.tutorialspoint.com/ipv4/ipv4_address_classes.htm
- https://en.wikipedia.org/wiki/Classful_network
- https://en.wikipedia.org/wiki/Classless_Inter-Domain_Routing
- https://www.dummies.com/programming/networking/cisco/network-basics-ip-network-classes/
-
IPv6 address
- http://www.steves-internet-guide.com/ipv6-guide/
- https://docs.oracle.com/cd/E18752_01/html/816-4554/ipv6-overview-10.html#:~:text=to%20the%20sender.-,Parts%20of%20the%20IPv6%20Address,the%20x's%20represent%20hexadecimal%20numbers.
- https://www.juniper.net/documentation/en_US/junos/topics/concept/interface-security-logical-property-ipv6-addressing-understanding.html

Top comments (0)