
This is part two of a three part series in which we'll seek to understand:
What areas in New York are most popular, have the best public transit connectivity, and offer the best amenities for their asking price?
If you haven't already, check out part one here to get caught up.
Looking ahead
In this article we'll cover the following:
- Using Terraform to provision the infrastructure for a serverless web crawler
- Setup a recursive serverless function
- Connecting to datastores and external systems
- Schedule a daily run for the crawl job
- Deploying the system to AWS
Recap
Thus far, we've put together and tested locally a configuration file that defines how the scraper will extract apartment listings from Craigslist. That configuration should look something like this:
// ./src/job.js
const { Client } = require('pg')
const moment = require('moment')
// non-configuration truncated for brevity
// see here for full file: https://github.com/achannarasappa/locust-examples/blob/master/apartment-listings/src/job.js
module.exports = {
extract: async ($, page) => transformListing({
'title': await $('.postingtitletext #titletextonly'),
'price': await $('.postingtitletext .price'),
'housing': await $('.postingtitletext .housing'),
'location': await $('.postingtitletext small'),
'datetime': await page.$eval('.postinginfo time', (el) => el.getAttribute('datetime')).catch(() => null),
'images': await page.$$eval('#thumbs .thumb', (elements) => elements.map((el) => el.getAttribute('href'))).catch(() => null),
'attributes': await page.$$eval('.mapAndAttrs p.attrgroup:not(:nth-of-type(1)) span', (elements) => elements.map((el) => el.textContent)).catch(() => null),
'google_maps_link': await page.$eval('.mapaddress a', (el) => el.getAttribute('href')).catch(() => null),
'description': await $('#postingbody'),
}),
after: async (jobResult, snapshot, stop) => {
if (isListingUrl(jobResult.response.url)) {
await saveListing(jobResult.data)
}
if (snapshot.queue.done.length >= 25)
await stop()
return jobResult;
},
start: () => null,
url: 'https://newyork.craigslist.org/search/apa',
config: {
name: 'apartment-listings',
concurrencyLimit: 2,
depthLimit: 100,
delay: 3000,
},
filter: (links) => links.filter(link => isIndexUrl(link) || isListingUrl(link)),
connection: {
redis: {
port: 6379,
host: 'localhost'
},
chrome: {
browserWSEndpoint: `ws://localhost:3000`,
},
}
};
The next steps are to design the system, set up the infrastructure, and deploy the code.
System Design
Let's define some non-functional requirements and considerations to guide the design:
- No pre-existing infrastructure or systems - a greenfield build
- Listings change frequently so the crawl should be run on a regular interval
- Locust requires a Redis and Chrome instance for it's queue and HTTP requests respectively
- Network access
- Serverless run context will need network access to the data store for listings
- Serverless run context will need network access to the Redis and Chrome instances for Locust
- Chrome will need access to the internet to execute HTTP requests
- A database schema will need to be defined for the data store before it is usable
With these in mind, the system diagram would look like this:
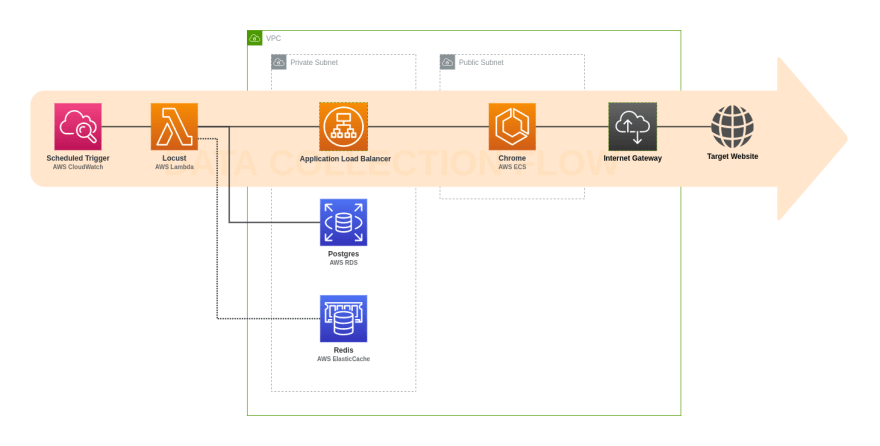
Note: the database will be in the public subnet to simplify initial setup
Infrastructure setup
To setup and manage infrastructure, we'll use Terraform to define our infrastructure as configuration. The some of the Terraform resources needed for this setup are low level and not part of the core problem so we'll pull in a few Terraform modules that provide higher order abstractions for these common resource collections. These are:
- AWS VPC - terraform-aws-modules/vpc/aws
- AWS RDS - terraform-aws-modules/rds/aws
- Locust internal resources - github.com/achannarasappa/locust-aws-terraform
Compute (AWS Lambda)

First we'll start by setting up the Locust job in an AWS Lambda function:
# ./infra/main.tf
provider "aws" {
profile = "default"
region = "us-east-1"
}
resource "aws_lambda_function" "apartment_listings_crawler" {
function_name = "apartment-listings"
filename = "./src.zip"
source_code_hash = filebase64sha256("./src.zip")
handler = "src/handler.start"
runtime = "nodejs10.x"
}
Note here that a handler of src/handler.start is referenced along with a file bundle ./src.zip. src/handler.start is the AWS Lambda function handler that is called when the function is triggered. Since with each Locust job run, the next job's data is pulled from Redis queue, no arguments are needed from the handler and the handler ends up being fairly straightforward:
// ./src/handler.js
const { execute } = require('@achannarasappa/locust');
const job = require('./job.js')
module.exports.start = () => execute(job);
Next, the source along with dependencies will need to be bundled into ./src.zip:
npm install && zip -r ./infra/src.zip ./src package*.json node_modules
Since source_code_hash has been set to filebase64sha256 of the zip file, a rebundle will result in a diff in Terraform and the new file bundle will be pushed up.
From this point, the lambda can be provisioned to AWS with terraform apply but it won't be all that useful since it still lacks connection information and network access to other resources in addition to basic permissions to run. We will come back to this Terraform block later to add those pieces once they've been setup elsewhere.
Networking (VPC)
In order to provision many of the resources needed for this system, a VPC is required. The terraform-aws-modules/vpc/aws module can be used to setup a VPC along with some common resources associated with networking:
# ./infra/main.tf
module "vpc" {
source = "terraform-aws-modules/vpc/aws"
name = "apartment-listings"
cidr = "10.0.0.0/16"
azs = ["us-east-1c", "us-east-1d"]
private_subnets = ["10.0.1.0/24", "10.0.2.0/24"]
public_subnets = ["10.0.101.0/24", "10.0.102.0/24"]
# enable public access to database for initial setup
create_database_subnet_group = true
create_database_subnet_route_table = true
create_database_internet_gateway_route = true
enable_dns_hostnames = true
enable_dns_support = true
}
With the VPC setup, we can start adding resources to it starting with the database
Storage (AWS RDS)

For the database, we'll need to provision a Postgres instance to AWS RDS along with set up the schema. The configuration for a minimal database will be as follows:
# ./infra/main.tf
module "db" {
source = "terraform-aws-modules/rds/aws"
version = "~> 2.0"
identifier = "apartment-listings-postgres"
engine = "postgres"
engine_version = "10.10"
instance_class = "db.t3.micro"
allocated_storage = 5
storage_encrypted = false
name = var.postgres_database
username = var.postgres_user
password = var.postgres_password
port = var.postgres_port
publicly_accessible = true
vpc_security_group_ids = []
maintenance_window = "Mon:00:00-Mon:03:00"
backup_window = "03:00-06:00"
backup_retention_period = 0
family = "postgres10"
major_engine_version = "10.10"
enabled_cloudwatch_logs_exports = ["postgresql", "upgrade"]
subnet_ids = module.vpc.public_subnets
deletion_protection = false
}
Note here that the RDS instance is marked as publicly accessible and part of a public subnet so that we can perform the one time setup of the database schema. There are also no vpc_security_group_ids defined yet which will need to be added later.
resource "aws_security_group" "local-database-access" {
vpc_id = "${module.vpc.vpc_id}"
ingress {
protocol = "-1"
self = true
from_port = tonumber(var.postgres_port)
to_port = tonumber(var.postgres_port)
cidr_blocks = ["${chomp(data.http.myip.body)}/32"]
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
}
data "http" "myip" {
url = "http://ipv4.icanhazip.com"
}
resource "null_resource" "db_setup" {
provisioner "local-exec" {
command = "PGPASSWORD=${var.postgres_password} psql -h ${module.db.this_db_instance_address} -p ${var.postgres_port} -f ../db/schema/setup.sql ${var.postgres_database} ${var.postgres_user}"
}
}
The aws_security_group_rule will add a firewall rule that allows access from the machine being used to provision this system while the null_resource named db_setup will execute an ad-hoc sql query using psql that will create the table and schema in the database (this will run locally so psql will need to be installed on the local machine). The db resource will also need to be updated with the newly created security group for local access:
vpc_security_group_ids = ["${aws_security_group.local-database-access}"]
With the infra defined for the database, the we'll need sql statements that sets up the database:
CREATE TABLE listing.home (
id integer NOT NULL,
title character varying,
price numeric,
location character varying,
bedroom_count numeric,
size character varying,
date_posted timestamp with time zone,
attributes jsonb,
images jsonb,
description character varying,
latitude character varying,
longitude character varying
);
Looking back at the ./src/job.js file, the properties here correspond 1:1 with the output of the transformListing function.
Now all the pieces are in place to provision the database. Also note that there are several variables defined in the preceding terraform blocks that will need to defined in variables.tf:
variable "postgres_user" {
default = "postgres"
}
variable "postgres_password" {
}
variable "postgres_database" {
default = "postgres"
}
variable "postgres_port" {
default = "5432"
}
Scheduling runs (AWS Cloudwatch)

In order to have the crawl execute on an interval, a cron-like solution will be needed that interfaces well with AWS Lambda. One way to achieve that is through a scheduled CloudWatch event:
resource "aws_cloudwatch_event_rule" "apartment_listings_crawler" {
name = "apartment_listings_crawler"
description = "Crawls apartment listings on a schedule"
schedule_expression = "rate(1 day)"
}
resource "aws_cloudwatch_event_target" "apartment_listings_crawler" {
rule = "${aws_cloudwatch_event_rule.apartment_listings_crawler.name}"
arn = "${aws_lambda_function.apartment_listings_crawler.arn}"
}
This will trigger the Lambda once per day which will start a crawler job that will continue until a stop condition is met spawning additional Lambdas bounded by the parameters in the job definition file.
An additional resource-based permission is needed to allow CloudWatch events to trigger Lambdas:
resource "aws_lambda_permission" "apartment_listings_crawler" {
action = "lambda:InvokeFunction"
function_name = "${aws_lambda_function.apartment_listings_crawler.function_name}"
principal = "events.amazonaws.com"
source_arn = aws_cloudwatch_event_rule.apartment_listings_crawler.arn
}
Locust internal resources

The last remaining set of resources to add are the chrome instance which Locust will use to execute HTTP requests in a browser context and the Redis instance which will power Locust's job queue. These are all defined within the Terraform module github.com/achannarasappa/locust-aws-terraform. Inputs for this module are:
-
vpc_id - VPC id from
apartment-listingsVPC defined earlier -
private_subnet_ids - list of private subnet ids from
apartment-listingsVPC defined earlier -
public_subnet_ids - list of public subnet ids from
apartment-listingsVPC defined earlier
And outputs are:
- redis_hostname - hostname of the Redis instance which will need to be passed to the AWS Lambda running Locust
- chrome_hostname - hostname of the Chrome instance which will need to be passed to the AWS Lambda running Locust
- security_group_id - AWS security group that the Redis and Chrome instances are a part of
- iam_role_arn - AWS IAM role with the proper permissions to access Chrome, Redis, and run Locust
We'll need to revisit the Lambda configuration to add the hostnames, role ARN, and security group with the outputs from this module in the next section. The security group can also be reused by the db module to allow access from the Lambda to Postgres:
module "db" {
...
vpc_security_group_ids = ["${module.locust.security_group_id}"]
...
}
Tying everything together

Earlier we set up a placeholder Lambda function that was missing a few key pieces that we now have:
- IAM role
- VPC subnets
- Security groups with dependent resources
- Hostnames for Redis and Chrome plus connection information for Postgres
Now that other resources have been setup, the aws_lambda_function can be updated with this information:
resource "aws_lambda_function" "apartment_listings_crawler" {
...
role = "${module.locust.iam_role_arn}"
vpc_config {
subnet_ids = concat(module.vpc.public_subnets, module.vpc.private_subnets)
security_group_ids = ["${module.locust.security_group_id}"]
}
environment {
variables = {
CHROME_HOST = "${module.locust.chrome_hostname}"
REDIS_HOST = "${module.locust.redis_hostname}"
POSTGRES_HOST = "${module.db.this_db_instance_address}"
POSTGRES_USER = "${var.postgres_user}"
POSTGRES_PASSWORD = "${var.postgres_password}"
POSTGRES_DATABASE = "${var.postgres_database}"
POSTGRES_PORT = "${var.postgres_port}"
}
}
}
Connection information for dependencies are passed into the Lambda run context to tell Locust where to connect. The security groups, subnets, and IAM role allow the Lambda to make outbound connections to Postgres, Chrome, and Redis.
Now that connection information for AWS is being passed into the Locust run context, the various localhost references in ./src/job.js can be updated to use those environment variables.
- In the connection to Postgres (
saveListings function):
const client = new Client({
host: process.env.POSTGRES_HOST || 'localhost',
database: process.env.POSTGRES_DATABASE || 'postgres',
user: process.env.POSTGRES_USER || 'postgres',
password: process.env.POSTGRES_PASSWORD || 'postgres',
port: process.env.POSTGRES_PORT || 5432,
})
- In the connection object for Redis and Chrome:
module.exports = {
// ...
connection: {
redis: {
port: 6379,
host: process.env.REDIS_HOST || 'localhost'
},
chrome: {
browserWSEndpoint: `ws://${process.env.CHROME_HOST || 'localhost'}:3000`,
},
}
// ...
}
With all of the connection details setup, the last step is to replace the dummy start function with a function that will trigger a new job run. This will allow Locust to recursively trigger itself until a stop condition is met. In this case, we need to initiate a new Lambda function:
const AWS = require('aws-sdk');
const lambda = new AWS.Lambda({ apiVersion: '2015-03-31' });
module.exports = {
// ...
start: () => lambda.invoke({
FunctionName: 'apartment-listings',
InvocationType: 'Event',
}).promise()
.catch((err) => console.log(err, err.stack)),
// ...
}
Deploying to AWS
The final setup is to provision the infrastructure and push the bundled source for the crawler. With the source_code_hash = filebase64sha256("./src.zip") in resource block for aws_lambda_function, the bundle ./src.zip will be pushed along with a terraform apply so no distinct step is needed for that.
Bundle the source:
rm -f ./infra/src.zip && npm install && zip -r ./infra/src.zip ./src package*.json node_modules
Double check thar terraform and psql are installed locally then apply the changes with terraform:
cd ./infra && terraform apply -auto-approve
The provisioning will take about 10 minutes then the system should be up and running. The CloudWatch will automatically trigger the job once a day so no additional ad-hoc commands are need to run the crawler.
If you'd like to trigger the crawler immediately, this command can be used:
aws lambda invoke \
--invocation-type Event \
--function-name apartment_listings_crawler \
--region us-east-1 \
--profile default \
out.txt
Refer to the Locust operational guide for tips on how to manage Locust and debug issues.
Conclusion
Thus far in the series, we've learned how to build a serverless crawler with Locust in part 1 including:
- Analyzing how web data is related on a particular website and how this can be used by a crawler to discover page on the fly
- Identifying relevant elements of a web page and how to extract them using Web APIs
- Filtering out noise and optimizing crawler efficiency
- Controlling crawler behaviors and setting stop conditions
- Persisting to a datastore
- Cleaning data before persistence
In this article, we've covered how to deploy the crawler to AWS including:
- Using Terraform to provision the infrastructure for a serverless web crawler
- Setup a recursive serverless function
- Connecting to datastores and external systems
- Schedule a daily run for the crawl job
- Deploying the system to AWS
In the next article in the series, we'll take a look at the data that's been gathered by the crawler to come to a data driven answer to the original question of where are the best areas to live in New York City.

Top comments (0)