
Hi everyone 👋,
In this article, I'll explain how we found a solution for our SEO problems in Superpeer and explain all the tools we use in details.
First things first, if you want to dive deep into the problem where it comes from, please read the section below before continuing.
JavaScript web pages make SEO an already tricky field, much more complicated. SEO is one of the more technical fields within the digital marketing space. It’s like the popular circus act where the juggler spins three plates on poles. Technical SEO is like doing that on a tightrope. JavaScript SEO is lighting the tightrope, the plates, and yourself on fire. It’s a tricky balancing act. Not only does your website need to be formatted in a way that makes it easy for search engines to process it, but it needs to perform better and load faster than the competition. However, the nice thing about technical SEO is that you have direct control over one of the ranking factors. How do you make your JavaScript website easy for Google to read and understand while giving your visitors a good web experience at the same time? The answer: Dynamic rendering. Google uses an automated program, known as a bot, to index and catalogue every web page on the Internet. Google’s stated purpose is to provide the user with the best possible result for a given query. To accomplish this, it seeks to understand what content is on a given web page and assess its relative importance to other web pages about the same topic. Most modern web development is done with three main programming languages: HTML, CSS, and JavaScript. Google processes HTML in two steps: crawl and index. First, Googlebot crawls the HTML on a page. It reads the text and outgoing links on a page and parses out the keywords that help determine what the web page is about. Then, Googlebot indexes the page. Google, and other search engines, prefer content that’s rendered in static HTML. With JavaScript, this process is more complicated. Rendering JavaScript comes in three stages: Google has to process JavaScript multiple times in order for it to fully understand the content in it. This process is known as rendering. When Google encounters JavaScript on a web page, it puts it into a queue and comes back to it once it has the resources to render it. HTML is standard in web development. Search engines can render HTML-based content easily. By comparison, it’s more difficult for search engines to process Javascript. It’s resource-intensive. What this means is that web pages based on JavaScript eat up your crawl budget. Google states that its web crawler can process JavaScript. However, this hasn’t yet been proven. It requires more resources from Google to crawl, index, and render your JavaScript pages. Other search engines such as Bing and DuckDuckGo are unable to parse JavaScript at all. Because search engines have to use more resources to render your JavaScript pages, it’s likely many elements of your page won’t get indexed at all. Google and other search engines could skip over your metadata and canonical tags, for example, which are critical for SEO. The thing is, Javascript provides a good user experience. It’s the reason why you’re able to make flashy websites that make your users go, “Wow, that was so cool!” How do you make a modern web experience without sacrificing your SEO? Most developers accomplish this with server-side rendering. 😅 Most JavaScript frameworks such as Angular, Vue, and React default to client-side rendering. They wait to fully load your web page’s content until they can do so within the browser on the user’s end. In other words, they render the content for humans rather than on the server for search engines to see it. Client-side rendering is cheaper than other alternatives. It also reduces the strain on your servers without adding more work for your developers. However, it carries the chance of a poor user experience. For example, it adds seconds of load time to your web pages, which can lead to a high bounce rate. Client-side rendering affects bots as well. Googlebot uses a two-wave indexing system. It crawls and indexes the static HTML first and then crawls the JavaScript content once it has the resources. This means your JavaScript content might be missed in the indexing process. That isn’t good. You need Google to see that content if you want to rank higher than your competitors and to be found by your customers. So what’s the alternative? For most development teams, it’s server-side rendering: configuring your JavaScript so that content is rendered on your website’s own server rather than on the client-side browser. This renders your JavaScript content in advance, making it readable for bots. SSR has performance benefits as well. Both bots and humans get faster experiences, and there’s no risk of partial indexing or missing content. If server-side rendering were easy, then every website would do it, and JavaScript SEO wouldn’t be a problem. But, server-side rendering isn’t easy. SSR is expensive, time-consuming, and difficult to execute. You need a competent web development team to put it in place.## What is the main problem?
What is the main problem?
What Happens When Google Visits Your Webpage
The Problem With JavaScript SEO
What’s the Difference Between Client-side and Server-side Rendering?
So, Why Doesn’t Everyone Just Use Server-Side Rendering?
end
How did we found solutions to all of these problems in Superpeer?
Superpeer uses Vue.js in the frontend part like most modern companies, and since it works completely in SPA structure, we have experienced these problems.
We thought it would take a lot of time to make changes in the existing code base structure to convert it to a hybrid system like SSR to find solutions to the SEO problem.
Forget all things; we don't want to make architecture level changes in our code for SEO or SSR because superpeer is actively working in production, and we make super-fast feature deployment almost every week, which is very risky for us. Therefore we wanted to solve these problems by trying different ways.
As a result of all these experiences, we thought that Cloudflare Workers would solve our problems, and after a certain R&D process, we decided to proceed with Cloudflare Workers on this adventure.
Apart from our SEO issues, we were hosting the Superpeer's frontend on Netlify. Netlify has many advantages as well as disadvantages. We were experiencing some caching problems, especially in production deployments, and that things take many disadvantages for us. During R&D time, we were very happy when we saw Cloudflare Workers serving a static site.
Let's deep dive into each process that we have done in Superpeer Cloudflare Workers process.
Serve Superpeer frontend on Cloudflare Workers Sites
Cloudflare Workers have the ability to serve a static site. After getting acquainted with this ability, we decided to transfer our frontend serving into here. After building a frontend application before the deployment stage, we deploy to our built dist directory with the wrangler CLI of Cloudflare Workers.
Wrangler is a superpower CLI, and it helps to make a lot of things in a single command script. To work with this, you need to create a configuration file, as seen below.

How did Cloudflare workers help to work index.html page like SSR?
As you may know, all SPA frameworks need a starting point to render, and this is index.html in all of them.
In Superpeer frontend structure, the Vue.js searches for the #app div HTML tag in index.html for the rendering process.
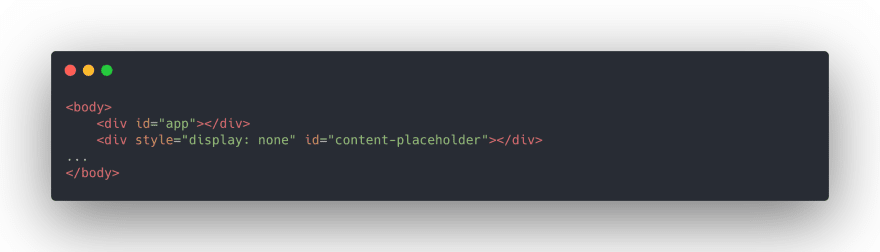
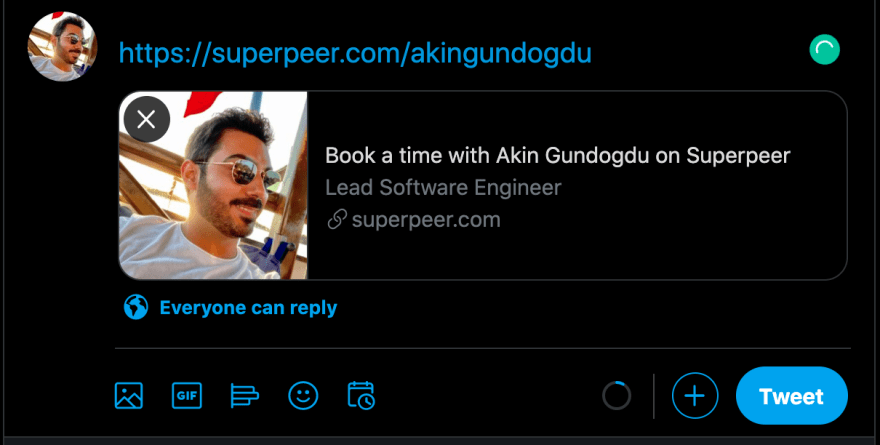
As you can see in the picture above, we have defined the div element with #content-placeholder id in the body tags, and we make a request to the backend API from the Cloudflare Workers index.js file to fetch the HTML that we need to be rendered for SEO. This method allows our pages to work like SSR.
If you go to www.superpeer.com/akingundogdu address and view page source, you can see rendered HTML.

Open Graph meta tags implementation
Open Graph meta tags are snippets of code that control how URLs are displayed when shared on social media.
They’re part of Facebook’s Open Graph protocol and are also used by other social media sites, including LinkedIn and Twitter (if Twitter Cards are absent).
You can find them in the <head> section of a webpage. Any tags og: before a property name are Open Graph tags. If you want to get more knowledge about that, you can read it here.
We have added the necessary meta tags to our index.html page, as shown in the picture below.

In the Cloudflare Workers index.js file, we replaced the related meta tags with the data we fetched from the backend API.


Let’s deep dive Cloudflare Workers index.js file.
All that we have explained above are working in Cloudflare Workers index.js file. In this chapter, I’ll be explaining how Cloudflare Workers manage these process starting from the coming first request on the www.superpeer.com.
Since we serve our frontend on Cloudflare Workers, we don’t need to do anything extra for our HTML, CSS, Font, etc. files and also Cloudflare Workers runs automatically for each request coming to www.superpeer.com domain.
How does shouldFetch variable decided path
If you go to www.superpeer.com/akingundogdu address, you will see that many files have been requested.

If we don’t control and separate these incoming requests, we’ll make too many backend API requests, and it would cause unnecessary delays in response times. To solve that, we separate these requests using the regex, as you have seen in the picture below, to decrease backend API requests.
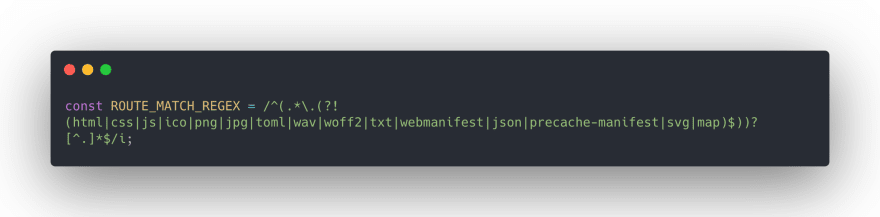
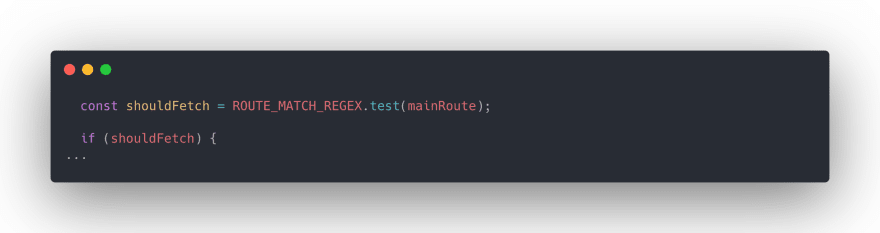
If the client makes a request to www.superpeer.com/akingundogdu address, shouldFetch variable return the true, if www.superpeer.com/xxxx.js|css request comes, shouldFetch variable return the false.
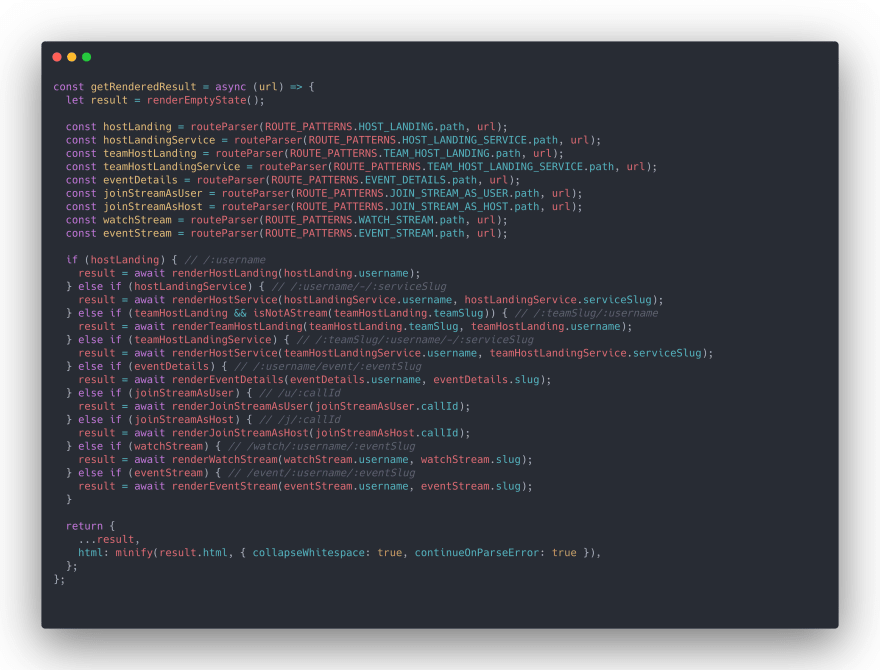
How Cloudflare Workers fetch necessary data from backend API?
To get the necessary data, Cloudflare Workers makes a request flash.superpeer.com with the URL.

On the backend side, the incoming URL is parsed, the necessary parameters in the URL are taken, and the required business logic is adapted page by page and the desired data and HTML return as a JSON response.

After the worker fetched the data it needs from the backend API, it renders the HTML content to be served from the Cloudflare Workers KV and replaces the meta tags in the index.html file using the handleReplacement function.
Also, the HTMLRewriter of Cloudflare Workers, handles replacing the HTML process quickly with the transform method without string processing.

Why do we use Cloudflare Workers KV for?
We use KV to cache all coming requests based on URLs. As an example, when the request to www.superpeer.com/akingundogdu address, if it is in the KV by route, it directly returns the cached result as a response. This mechanism has a positive effect on response performances and backend API requests.
The picture below shows the SUPERPEER_KV key-value store namespace, which is specially set for the production environment.

Using the Cloudflare Workers environment structure as the cache key, we generate a unique id for each deployment and dynamically set it to the environment variable name. RELEASE_ID.
Example for cache key @RELEASE_ID_www.superpeer.com/akingundogdu@
In this way, all of our caches are automatically invalidated every time we do a new deployment. In the picture below, you can see the latest RELEASE_ID assigned as the ENV variable.

You can see the cached HTML sources stored in SUPERPEER_KV according to these keys.

In the picture below, you can see all the codes explaining the entire Cloudflare Workers process.

How Superpeer work after using Cloudflare Workers?
There are many types of pages in the superpeer, and these pages can be shared on many platforms. We solved our problems by creating different special templates for these pages.
You can see all results by template types


Thank you very much for reading so far! ❤️
If you have any questions, don’t hesitate to contact the following platforms.
Thanks, 👋
Platforms: Linkedin, Twitter, Superpeer
Referenced Sources:
https://www.youtube.com/watch?v=WFlDSL7Nrzw
https://www.youtube.com/watch?v=KMEgJRqYzzg
https://www.youtube.com/watch?v=QcXmGQqtUn0
https://www.youtube.com/watch?v=5dkzFrJ044o
https://www.youtube.com/watch?v=48NWaLkDcME
https://www.youtube.com/watch?v=4lGzIZqVN8Q
https://www.smashingmagazine.com/
https://www.cloudflare.com/
https://prerender.io/
https://developers.cloudflare.com/

Oldest comments (0)