
You might have heard about SQL and NoSQL databases (they are, after all, the most popular available), but have you heard about a Graph Database? 🤔
Let us look closer into this and explore why you should consider this novel approach.
When we talk about Graphs, we’re talking about very densely connected data with many relationships (Ex: Social network connections and recommendation engines). A graph database is simply a form of the infamous graph data structure almost always questioned during technical interviews.
Graph databases store “nodes” and “relationships” instead of tables and documents.
Imagine sketching ideas on a whiteboard and joining them together forming some kind of mind map. You have the flexibility of thinking about how you would use it. Graph databases have the same influence — that data is stored similar to how your mind map would look like; densely connected relationships, albeit not having a strict predefined model to follow.
Why Graph databases?
Why would we need to use a graph database? After all, almost all applications that we build use either an SQL or NoSQL database.
The most important reason is that it makes the reasoning of data much more understandable — especially when the data is densely connected.

Simply displaying an image that shows why to use a graph database will not suffice, hence, I will compare a simple use case using actual code.
Imagine this scenario this SQL:
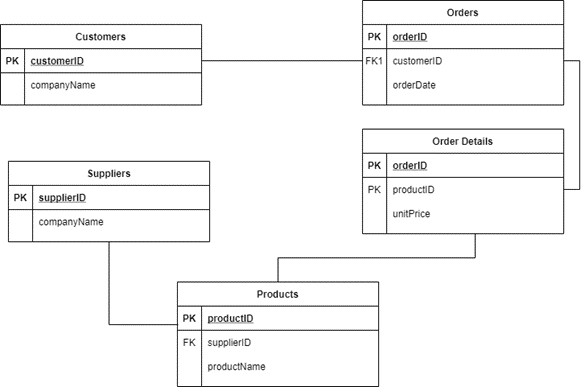
Our goal is to find the name of companies that purchased the product “Mac”.
A solution would be as follows:
SELECT distinct c.CompanyName
FROM customers AS C
JOIN orders AS o ON (c.CustomerID = o.CustomerID)
JOIN orderdetails AS od ON (o.OrderID = od.OrderID)
JOIN products as p ON (od.ProductID = p.ProductID)
WHERE p.ProductName = ‘Mac’
It obviously is pretty straightforward, however, when we put this exact same scenario into a graph database, things start getting more understandable.
The exact same scenario in a Graph Database design:
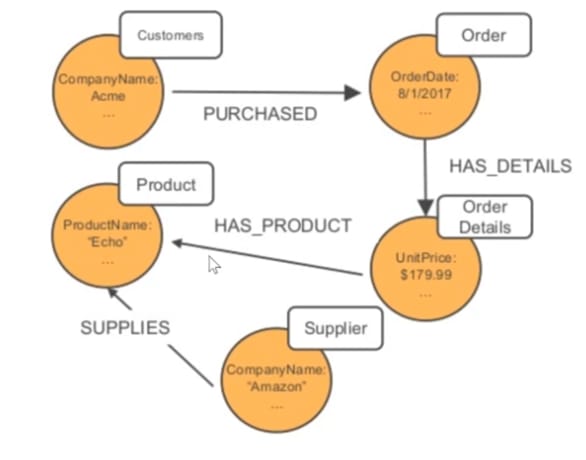
The design, in this case, is easier to read and understand since the thought process required to build proper models is not present.
A solution, using Gremlin is as follows:
g.V().hasLabel(‘Product’).has(‘productName’, ‘Mac’)
.in(‘HAS_PRODUCT’)
.in(‘HAS_DETAILS’)
.in(‘PURCHASED’)
.values(‘CompanyName’).dedup()
Querying, in this case, is much simpler since all you require to do is traverse the graph without having to worry about joins.
Popular Graph Databases
Currently in the industry there are a couple of popular options of graph databases, some of which are:
- Neo4j — an ACID-compliant transactional database with native graph storage and processing.
- ArangoDB —a scalable, fully managed graph database, document store and search engine in one place.
- Amazon Neptune — a fast, reliable, fully managed graph database service
All in all, graph databases can be an excellent solution if you require highly connected data with a large number of relationships — although this topic by itself can be daunting since it requires knowledge of how the graph data structure works.
Keep growing! 😁

Top comments (0)