
The growth of Node.js is tremendous. It’s clear why — Node.js helps us move fast, it has a rich packages ecosystem, it’s battle-tested and the usage of JavaScript allows businesses to go truly full-stack and cut the development lifecycle short.
However, with great powers comes great responsibility (as I previously mentioned in my JWT article). After reflecting on the past 8 years of using Node.js, I decided to publish an article covering four common mistakes made by Node.js developers.
Most of these are not Node-specific but rather back-end general. However, I will refer to concrete Node.js examples that are relevant to any developer in the ecosystem.
Mistake #1 — Going live without well-defined log levels

I assume most of us are familiar with the concept of log levels (DEBUG, INFO, WARN, ERROR, etcetera).
I have seen many cases where a product team is rushed to deliver a new microservice and forgets about clearly defining these log levels.
There are two main drawbacks to this:
- It will make it a lot harder for you and your teammates to identify and tackle issues in production if the logs are flooded with irrelevant messages, such as low-level
DEBUGlogs. These are not usually helpful for production workloads. - It will dramatically increase the bill of whatever log ingestion service you use. I have seen this first-hand — going live with a new service and BOOM — a massive bump in expenses. Log ingestion services charge you by throughput and/or storage. 💸
To tackle both points, make sure you use a logger with clearly-defined log levels. There are plenty of great logger libraries for Node.js (winston, pino, morgan) which provide you with a simple API for emitting logs of different types.
Additionally, ensure you are able to configure the log level of your application at runtime via an environment variable (commonly seen is LOG_LEVEL). This way you can adjust the log level according to your needs, whether you are working locally (set in your .env file) or when running workloads on cloud environments (Staging, Production etcetera).
Mistake #2 —Recklessly choosing your Dockerfile’s base image
It is extremely common to deploy Node.js apps as containers and there are many benefits to doing so. When defining your Dockerfile, you declare the base image to use at the top of the file. For example:
FROM node:18
This indicates that your image will be built based on the official Node.js version 18 image. What developers often don’t pay attention to, is the potential negative impact of this.
Let’s stick to the Node 18 example. The above image is based on the Debian operating system. This is a full operating system which adds a lot of overhead for a typical back-end API written in Node.js. The image size will be very large, take a long time to build, cost more to store, and more resources will be used by the container, thus affecting your scalability and performance.
Solving this is quite easy — use an alternative image. It’s very common to see alpine and slim flavours of images. In a nutshell, these are Linux-based operating systems that are very lightweight and don’t contain many of the binaries and libraries preinstalled in a fully-featured operating system.
When browsing the Node.js image tags on Docker Hub, we can see that both alpine and slim flavours are available. By simply making this change:
FROM node:18-alpine
We saved a significant amount of time building the image and minimised the operating system’s overhead, thus optimising the overall performance of our containers. Additionally, the resulting image size is significantly smaller which makes it faster to build and push, and cheaper to store on a remote container registry. Win! 🥳
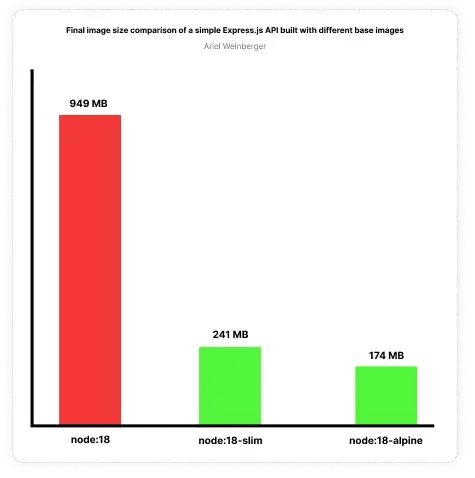
A whopping x5 reduced image size. Now imagine the impact of this in a team that runs multiple CI pipelines for multiple services every day! 🤯
Note that while this works in most cases, sometimes your app’s packages require certain low-level libraries that aren’t included in lightweight images by default. You will need to install them as a RUN statement in your Dockerfile. Still, the benefits are well worth it!
Mistake #3 — Not using asymmetric encryption when signing JSON Web Tokens (JWT)
As I wrote in my article, "JSON Web Tokens (JWT) — the only explanation you will ever need", JSON Web Tokens are truly changing the world.
It’s a fantastic tool to have when developing microservices for achieving distributed authorization.
The mechanism is quite simple — you sign and verify tokens using cryptography.
The simplest form of implementation allows you to use a secret (for example, verySecret123 to sign tokens. You will then use the same secret to verify those tokens. This is a symmetric signature, because the same value is used to sign the token as well as verify it.
If doing this in a distributed architecture, every one of your services will need access to that secret in order to verify tokens. This increases the chance of your secret being stolen, which may result in an attacker signing fake tokens, allowing them to elevate access or impersonate and perform operations on behalf of others. This is often overlooked, and poses a serious security risk! 🚨

The better way to sign JWTs is using an asymmetric algorithm. Instead of using a raw secret value to sign and verify the tokens, you use a keypair (for example, generated via openssl). The result is a private key used to sign tokens, and a public key used to verify tokens.
This method is significantly more secure, as it allows the signing authority (for example your Auth Service) to exclusively possess the private key and use it to sign tokens.
Any other service in your architecture that needs to accept API requests can possess the public key and use it to verify tokens.
This greatly reduces the risk of your private key being stolen and exploited to generate tokens of false identities and/or elevated privileges, by limiting the number of service with access to it.
If you are curious and want to know more, I cover this in detail in my bespoke JSON Web Tokens article.
Mistake #4 — Storing passwords without unique salting
In general, I am strongly against storing passwords on your systems, unless this is your core business (which entails heavy regulations and auditing). It’s all fun and games until it goes wrong. 👎
Regardless, many companies opt-in to store passwords on their own systems. This is also an important topic for back-end developers to be familiar with.
➡️ Before talking about this mistake, a quick primer on password authentication…
Remember that password validation is not an "encryption-decryption" operation. You take a raw password, run it through a hashing algorithm and store it, so that myPassword123 becomes something like 487753b945871b5b05f854060de151d8 which gets stored in a database. Then, upon signing in, you take the user’s input and hash it. You then compare the result hash to that stored in your database, and if it’s a match — you authenticate the user.
➡️ Now we are aligned! There are four levels of security when it comes to storing passwords:
- Storing raw passwords 😭. This is an absolute no-no. In the case of a database breach, and attacker will get access to the raw passwords of all of your users.
- Hashing passwords (no salt) 😖. You take a user’s password and run it through a hashing algorithm as described above, and store it in your database. This will prevent an attacker from getting access to raw passwords which is great. However, since you simply hashed the password, an attacker can utilize a Rainbow Table attack in which they compare hashed passwords against their respective raw passwords, and identify matches. Remember that running myPassword123 through a simple hashing algorithm will always produce the same result!
-
Hashing passwords + global salt 🥴. This method is very similar to the above, except you add a little "salt" to the password before hashing it. So you don’t really hash
myPassword123, but instead you hashmyPassword123+SOME_SALT. This means that a common password such asmyPassword123will look different as a hash in your database, and will protect you from rainbow table attacks. However, if your global salt is exposed, it becomes easier for an attacker to identify common passwords stored in your database. - Hashing passwords + unique salt per password 💪. This is the most robust and standard method of storing passwords today. Every password stored in your database is hashed with a unique salt. This significantly mitigates the chance of an attacker putting their hands on the raw passwords of your users, even in the case of a database breach. Implementing this is very easy, utilising a package such as Bcrypt.
Again, store your users’ passwords responsibly! Use a reliable and certified service to do that if you can, then you can focus on building your core product.
Folks — this is a reminder that you should always use a password manager to auto-generate passwords wherever you sign up. Never re-use the same password. You don’t know how your passwords are handled! ⚠️
Closing Remarks
If you're looking to build a new backend service and want to avoid some of these common mistakes, Amplication can help. Amplication makes it easy to use JWT, handles authentication securely, and is designed to support enterprise needs.
That’s all! I hope you enjoyed this article. Let me know what you think in the comments. If there are any other topics you find interesting, I’d love to know and perhaps even write about it!

Top comments (0)