
Scraping websites for data is a typical use case for developers. Whether it's a side project or you're building a startup, there are many reasons to scrape the web.
For example, if you want to start a price comparison website, you'll need to scrape prices from various e-commerce sites. Maybe you want to build an AI that could identify products and look up their price on Amazon. The possibilities are endless.
But have you ever noticed how slow it is to get all the pages? Would you scrape all the products one after the other? There must be a better solution, right? Right?!
Scraping websites can be time-consuming because you have to deal with waiting for responses from the server and rate-limiting. That's why we will show you how to speed up your web scraping projects by using concurrency in Python.
Prerequisites
For the code to work, you will need python3 installed. Some systems have it pre-installed. After that, install all the necessary libraries by running pip install.
pip install requests beautifulsoup4 aiohttp numpy
If you know the basics behind concurrency, skip the theory part and jump directly into the action.
Concurrency
Concurrency is a term that deals with the ability to run multiple computing tasks simultaneously.
When you make requests to websites sequentially, you send out one request at a time, waiting for it to return, and then sending out the following one.
However, you can send out many requests at once with concurrency, and work on them all as they return. The speed increases from this method are incredible. Compared to sequential requests, concurrent ones will be much faster regardless of whether they are running in parallel (multiple CPUs) or not - more on this later.
To understand the benefits of concurrency, we need to understand the difference between processing tasks sequentially and concurrently. For example, let's say we have five tasks that take 10 seconds each to complete.
When processing them sequentially, the time it takes to complete all five is 50 seconds. However, it takes only 10 seconds for all five tasks to complete when processing them concurrently.
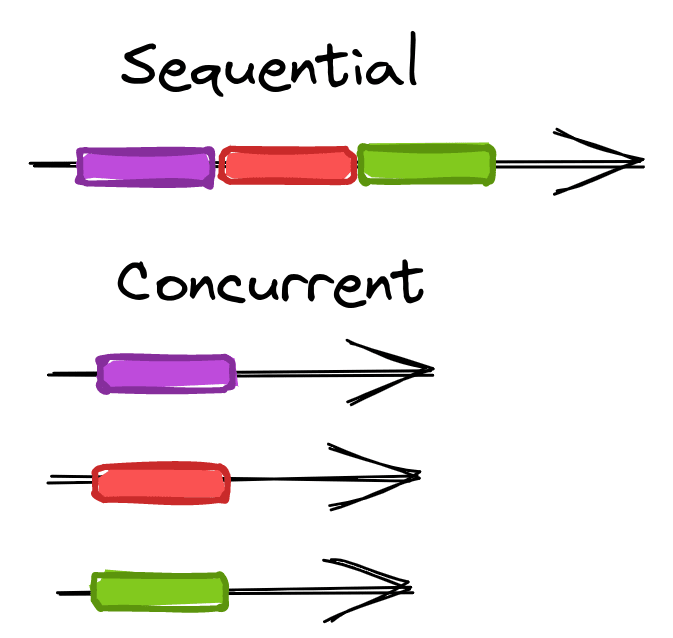
In addition to increasing speed, concurrency allows us to do more work in less time by distributing our web scraping workload among several processes.
There are several ways to parallelize requests, such as multiprocessing and asyncio. From a web scraping perspective, we can use these libraries to parallelize requests to different websites or other pages on the same website. In this article, we will focus on asyncio, a Python module providing infrastructure for writing single-threaded concurrent code using coroutines.
Since concurrency implies more convoluted systems and code, consider if the pros outweigh the cons for your use case.
Benefits of Concurrency
- More work done in less time.
- Idle network time invested in other requests.
Dangers of Concurrency
- Harder to develop and debug.
- Race conditions.
- The need to check and use thread-safe functions.
- Block probabilities grow if not handled carefully.
- Concurrency comes with a system overhead, set a reasonable concurrency level.
- Involuntary DDoS if too many requests against a small site.

Why asyncio?
To decide what technology to use, we must understand the difference between asyncio and multiprocessing. And also I/O-bound and CPU-bound.
asyncio "is a library to write concurrent code using the async/await syntax". It runs on a single processor.
multiprocessing "is a package that supports spawning processes using an API [...] allowing the programmer to fully leverage multiple processors on a given machine". Each process will start its own Python interpreter in a different CPU.
I/O-bound means that the program will run slower due to input/output operations. In our case, mostly network requests.
CPU-bound means that the program will run slower due to central processor use - for example, math calculations.
Why does this affect the library we will use for concurrency? Because a big part of the cost for concurrency is creating and maintaining threads/processes. For CPU-bound problems, having many processes in different CPUs will pay off. But that might not be the case for I/O-bound scenarios.
Since scraping is mostly I/O-bound, we picked asyncio. But in case of doubt (or just for fun), you can replicate the idea using multiprocessing and compare the results.

Sequential Version
We'll start by scraping scrapeme.live as an example, a fake Pokémon e-commerce prepared for testing.
First, we will start with the sequential version of the scraper. Several snippets are part of all cases, so those will remain the same.
By visiting the page, we see that there are 48 pages. Since it is a testing environment, that won't change anytime soon. Our first constants will be the base URL and a range for the pages.
base_url = "https://scrapeme.live/shop/page"
pages = range(1, 49) # max page (48) + 1
Now, extract the basics from a product. For that, use requests.get to get the HTML and then BeautifulSoup to parse it. We will loop over each product and get some basic info from them. All the selectors come from a manual review of the content (using DevTools), but we won't go into detail here for brevity.
import requests
from bs4 import BeautifulSoup
def extract_details(page):
# concatenate page number to base URL
response = requests.get(f"{base_url}/{page}/")
soup = BeautifulSoup(response.text, "html.parser")
pokemon_list = []
for pokemon in soup.select(".product"): # loop each product
pokemon_list.append({
"id": pokemon.find(class_="add_to_cart_button").get("data-product_id"),
"name": pokemon.find("h2").text.strip(),
"price": pokemon.find(class_="price").text.strip(),
"url": pokemon.find(class_="woocommerce-loop-product__link").get("href"),
})
return pokemon_list
The extract_details function will take a page number and concatenate that to create a URL with the base seen earlier. After getting the content and creating an array of products, return them. That means the returned values will be a list of dictionaries. It is an essential detail for later.
We need to run the function above for each page, get all the results, and store them.
import csv
# modified to avoid running all the pages unintentionally
pages = range(1, 3)
def store_results(list_of_lists):
pokemon_list = sum(list_of_lists, []) # flatten lists
with open("pokemon.csv", "w") as pokemon_file:
# get dictionary keys for the CSV header
fieldnames = pokemon_list[0].keys()
file_writer = csv.DictWriter(pokemon_file, fieldnames=fieldnames)
file_writer.writeheader()
file_writer.writerows(pokemon_list)
list_of_lists = [
extract_details(page)
for page in pages
]
store_results(list_of_lists)
Running the code above will get two product pages, extract products (32 total), and store them in a CSV file called pokemon.csv. The store_results function does not affect the scraping in sequential or concurrent mode. You can skip it.
Since the results are lists, we must flatten them to allow writerows to do its job. That's why we named the variable list_of_lists (even if it's a bit weird), only to remind everyone that it's not flat.
Example of the output CSV file:

If you were to run the script for every page (48) total, it would generate a CSV with 755 products and spend around 30 seconds.
time python script.py
real 0m31,806s
user 0m1,936s
sys 0m0,073s
Introducing asyncio
We know we can do better. If we perform all the requests at the same time, it should take much less, right? Maybe as long as the slowest request?
Concurrency should indeed run faster, but it also involves some overhead. So it is not a linear mathematical improvement. But improve we will.
For that, we will use the mentioned asyncio. It allows us to run several tasks on the same thread in an event loop (like Javascript does). It will run a function and switch the context to a different one when allowed. In our case, HTTP requests allow that switch.
We will start seeing an example that will sleep for a second. And the script should take a second to run. Notice that we cannot call main directly. We need to let asyncio know that it's an async function that needs executing.
import asyncio
async def main():
print("Hello ...")
await asyncio.sleep(1)
print("... World!")
asyncio.run(main())
time python script.py
Hello ...
... World!
real 0m1,054s
user 0m0,045s
sys 0m0,008s
Simple code in parallel
Next, we will expand an example case to run a hundred functions. Each of them will sleep for a second and print a text. It would take around one hundred seconds if we were to run them sequentially. With asyncio, it will take just one!
That's the power behind concurrency. As said earlier, for pure I/O-bound tasks, it will perform much faster - sleeping is not, but it counts for the example.
We need to create a helper function that will sleep for a second and print a message. Then, we edit main to call that function a hundred times and store each call in a tasks list. The last and crucial part is to execute and wait for all the tasks to finish. That's what asyncio.gather does.
import asyncio
async def demo_function(i):
await asyncio.sleep(1)
print(f"Hello {i}")
async def main():
tasks = [
demo_function(i)
for i in range(0, 100)
]
await asyncio.gather(*tasks)
asyncio.run(main())
As expected, a hundred messages and one second to execute. Perfect!
time python script.py
Hello 0
...
Hello 99
real 0m1,065s
user 0m0,063s
sys 0m0,000s
Scraping with asyncio
We need to apply that knowledge to scraping. The approach to follow will be to request concurrently and return product lists. Once all requests finish, store them. It might be better to save data after each request or in batches to avoid data losses for real-world cases.
Our first attempt won't have a concurrency limit, so be careful when using it. In the case of running it with thousands of URLs... well, it would perform all those requests almost at the same time. Which could cause a tremendous load on the server and probably fry your computer.
requests does not support async out-of-the-box, so we will use aiohttp to avoid complications. requests can do the job, and there is no substantial performance difference. But the code is more readable using aiohttp.
import asyncio
import aiohttp
from bs4 import BeautifulSoup
async def extract_details(page, session):
# similar to requests.get but with a different syntax
async with session.get(f"{base_url}/{page}/") as response:
# notice that we must await the .text() function
soup = BeautifulSoup(await response.text(), "html.parser")
# [...] same as before
return pokemon_list
async def main():
# create an aiohttp session and pass it to each function execution
async with aiohttp.ClientSession() as session:
tasks = [
extract_details(page, session)
for page in pages
]
list_of_lists = await asyncio.gather(*tasks)
store_results(list_of_lists)
asyncio.run(main())
The CSV file should have every product (755) just as before. Since we perform all the page calls at the same time, the results will not arrive in order. If we were to add the results to the file inside extract_details they might be unordered. Since we wait for all tasks to finish and then process them, the order will not be a problem.
time python script.py
real 0m11,442s
user 0m1,332s
sys 0m0,060s
We did it! 3x faster is nice, but... shouldn't it be 40x? It's not that simple. Many things can affect the performance (Network, CPU, RAM, and so on).
And in this demo page, we've noticed that response time slows down when we perform several calls. It might be by design. Some servers/providers can limit the number of concurrent requests to avoid too much traffic from the same IP. It is not a block but more of a queue. You will get served, but after waiting a bit.
To see real speed-up, you can test against a delay page. It is another testing page that will wait for 2 seconds and then return a response.
base_url = "https://httpbin.org/delay/2"
#...
async def extract_details(page, session):
async with session.get(base_url) as response:
#...
Removed all the extracting and storing logic, just calling the delay URL 48 times. And it runs in under 3 seconds.
time python script.py
real 0m2,865s
user 0m0,245s
sys 0m0,031s
Limiting Concurrency with Semaphore
As said earlier, we should limit the number of concurrent requests, especially against a single domain.
asyncio comes with Semaphore, an object that will acquire and release a lock. Its inner functionality will block some of the calls until the lock is acquired, thus creating a maximum concurrency.
We need to create the semaphore with the maximum we want. And then await on the extracting function until it is available using async with sem.
max_concurrency = 3
sem = asyncio.Semaphore(max_concurrency)
async def extract_details(page, session):
async with sem: # semaphore limits num of simultaneous downloads
async with session.get(f"{base_url}/{page}/") as response:
# ...
async def main():
# ...
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
It gets the job done, and it is relatively easy to implement! Here is the output with max concurrency set to 3.
time python script.py
real 0m13,062s
user 0m1,455s
sys 0m0,047s
It shows that the version with unlimited concurrency is not operating at its full speed 🤦. If we increment the limit to 10, the total time is similar to the unbound script.
Limiting concurrency with TCPConnector
aiohttp offers an alternative solution that offers further configuration. We can create the client session passing in a custom TCPConnector.
We can build it by using two parameters that suit our needs:
-
limit- "total number of simultaneous connections". -
limit_per_host- "limit simultaneous connections to the same endpoint" (same host, port, andis_ssl).
max_concurrency = 10
max_concurrency_per_host = 3
async def main():
connector = aiohttp.TCPConnector(limit=max_concurrency, limit_per_host=max_concurrency_per_host)
async with aiohttp.ClientSession(connector=connector) as session:
# ...
asyncio.run(main())
Also easy to implement and maintain! Here is the output with max concurrency set to 3 per host.
time python script.py
real 0m16,188s
user 0m1,311s
sys 0m0,065s
The advantage over Semaphore is the option to limit the total amount of concurrent calls and requests per domain. We could use the same session to scrape different sites, and each one of those would have its own limit.
The downside is that it looks a bit slower. Run some tests with more pages and actual data for a real-case scenario.
multiprocessing
Scraping is I/O-bound like we saw earlier. But what if we needed to mix it with some CPU-intensive computations? To test that case, we'll use a function that will count_a_lot (to one hundred million) after each scraped page. It is a simple (and silly) way to force a CPU to be busy for some time.
def count_a_lot():
count_to = 100_000_000
counter = 0
while counter < count_to:
counter = counter + 1
async def extract_details(page, session):
async with session.get(f"{base_url}/{page}/") as response:
# ...
count_a_lot()
return pokemon_list
For the asyncio version, just run it as before. It might take a long time ⏳.
time python script.py
real 2m37,827s
user 2m35,586s
sys 0m0,244s
Now, brace for the hard part.
Adding multiprocessing is a bit harder. We need to create a ProcessPoolExecutor, which "uses a pool of processes to execute calls asynchronously". It will handle the creation and control of each process in a different CPU.
But it won't distribute the load. For that, we will use NumPy's array_split, which will slice the pages range into equal chunks according to the number of CPUs.
The rest of the main function is similar to the asyncio version but changes some syntax to match the multiprocessing style.
The essential difference is that we cannot call extract_details directly. We could, but we'll try to obtain the maximum power by mixing multiprocessing with asyncio.
from concurrent.futures import ProcessPoolExecutor
from multiprocessing import cpu_count
import numpy as np
num_cores = cpu_count() # number of CPU cores
def main():
executor = ProcessPoolExecutor(max_workers=num_cores)
tasks = [
executor.submit(asyncio_wrapper, pages_for_task)
for pages_for_task in np.array_split(pages, num_cores)
]
doneTasks, _ = concurrent.futures.wait(tasks)
results = [
item.result()
for item in doneTasks
]
store_results(results)
main()
Long story short, each CPU process will have a few pages to scrape. There are 48 pages, and assuming your machine has 8 CPUs, each process will request six pages (6 * 8 = 48).
And those six pages will run concurrently! After that, the calculations will have to wait since they are CPU-intensive. But we have many CPUs, so they should run faster than the pure asyncio version.
async def extract_details_task(pages_for_task):
async with aiohttp.ClientSession() as session:
tasks = [
extract_details(page, session)
for page in pages_for_task
]
list_of_lists = await asyncio.gather(*tasks)
return sum(list_of_lists, [])
def asyncio_wrapper(pages_for_task):
return asyncio.run(extract_details_task(pages_for_task))
This ☝️ is where the magic happens. Each CPU process will start an asyncio with a subset of the pages (e.g., from 1 to 6 for the first one).
And then, each one of those will call several URLs, using the already known extract_details function.
Take a moment to assimilate that. The whole process goes like this:
- Create the executor.
- Split the pages.
- Start
asyncioper each process. - Create an
aiohttpsession and create the tasks of a subset of pages. - Extract data for each page.
- Consolidate and store the results.
And here are the execution times. We haven't mentioned it, but the user time here plays a notable role. For the script running only asyncio:
time python script.py
real 2m37,827s
user 2m35,586s
sys 0m0,244s
The version with asyncio and multiple processes:
time python script.py
real 0m38,048s
user 3m3,147s
sys 0m0,532s
Did you spot the difference? The first one took more than two minutes, and the second one 40 seconds. But in total CPU time (user time) the second one was over three minutes! That is a bit more due to system overhead and all that.
That shows that the parallel processing "wastes" more time (in total) but finishes before. Then it is up to you to decide which method to choose. Take also into account that it is more complicated to develop and debug 😅.
Conclusion
We've seen that asyncio might be enough for scraping since most of the running time goes to networking. Which is I/O-bound and works well with concurrent processing in a single core.
That situation changes if the gathered data requires some CPU-intensive work. We've seen a silly example with counting, but you get the point.
For most cases, asyncio with aiohttp - better suited than requests for async work - gets the job done. Add a custom connector to limit the number of requests per domain and total concurrent ones. With those three pieces, you can start building a scraper that can scale.
An important piece is to allow new URLs/tasks (something like a Queue), but that's for another day. Stay tuned!
Did you find the content helpful? Please, spread the word and share it. 👈
Originally published at https://www.zenrows.com

Top comments (0)