
Machine learning (ML) has become a cornerstone of modern technology, driving innovations in fields like healthcare, finance, and e-commerce. Python, with its simplicity and extensive libraries, has emerged as the go-to language for machine learning. Among the many Python libraries available, Scikit-Learn stands out as one of the most powerful and user-friendly tools for building machine learning models. Whether you're a beginner or an experienced developer, Scikit-Learn provides a robust framework to implement ML algorithms with ease. In this guide, we’ll walk you through the basics of Scikit-Learn, complete with coding examples, to help you get started with machine learning in Python.
Table of Contents
- What is Scikit-Learn?
- Setting Up Your Environment
- Understanding the Scikit-Learn Workflow
- Loading and Preparing Data
- Building Your First Machine Learning Model
- Evaluating Model Performance
- Improving Your Model
- Conclusion
What is Scikit-Learn?
Scikit-Learn is an open-source Python library that provides simple and efficient tools for data mining and data analysis. It is built on top of other popular Python libraries like NumPy, SciPy, and Matplotlib. Scikit-Learn supports a wide range of machine learning algorithms, including:
- Supervised Learning: Regression, Classification
- Unsupervised Learning: Clustering, Dimensionality Reduction
- Model Selection and Evaluation: Cross-validation, Hyperparameter Tuning
Its consistent API and extensive documentation make it an excellent choice for beginners and professionals alike.
Setting Up Your Environment
Before diving into Scikit-Learn, you need to set up your Python environment. You can install Scikit-Learn using pip:

Additionally, you’ll need other libraries like NumPy, Pandas, and Matplotlib for data manipulation and visualization:

Understanding the Scikit-Learn Workflow
The typical workflow for building a machine learning model in Scikit-Learn involves the following steps:
- Loading and Preparing Data: Import datasets and preprocess them.
- Splitting Data: Divide the dataset into training and testing sets.
- Choosing a Model: Select an appropriate algorithm.
- Training the Model: Fit the model to the training data.
- Making Predictions: Use the model to predict outcomes on test data.
- Evaluating Performance: Assess the model’s accuracy and effectiveness.
- Improving the Model: Tune hyperparameters and optimize performance.
Let’s explore each step in detail with coding examples.
Loading and Preparing Data
Scikit-Learn provides built-in datasets for practice. Let’s use the famous Iris dataset, which contains information about different species of iris flowers.
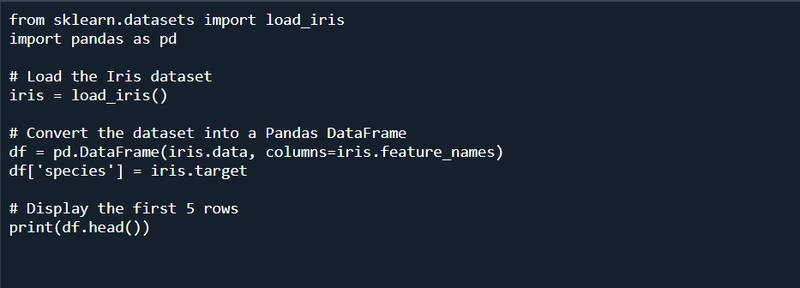
Data Preprocessing
Before training a model, it’s essential to preprocess the data. This includes handling missing values, scaling features, and encoding categorical variables. For simplicity, let’s split the dataset into features (X) and labels (y):

Building Your First Machine Learning Model
Let’s start with a simple k-Nearest Neighbors (k-NN) classifier, which is a popular algorithm for classification tasks.
Splitting the Data
First, split the dataset into training and testing sets:

Training the Model
Next, train the k-NN model:
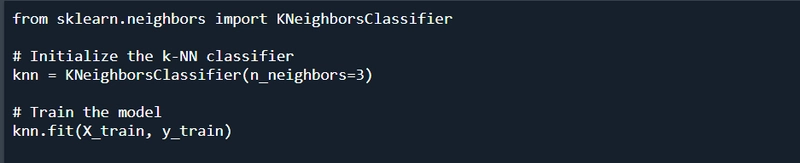
Making Predictions
Use the trained model to make predictions on the test data:

Evaluating Model Performance
To assess the model’s performance, use metrics like accuracy, precision, recall, and F1-score. Scikit-Learn provides tools to calculate these metrics.
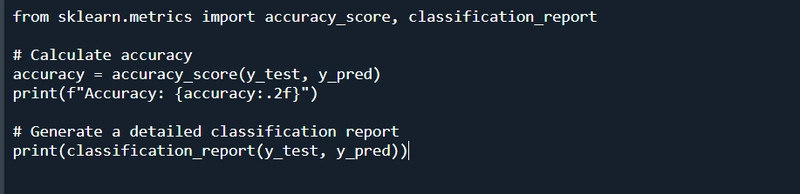
Improving Your Model
To improve the model’s performance, you can:
- Tune Hyperparameters: Use techniques like Grid Search or Random Search to find the best parameters.
- Feature Engineering: Select or create relevant features to improve model accuracy.
- Try Different Algorithms: Experiment with other algorithms like Decision Trees, Support Vector Machines, or Random Forests.
Example: Hyperparameter Tuning with Grid Search
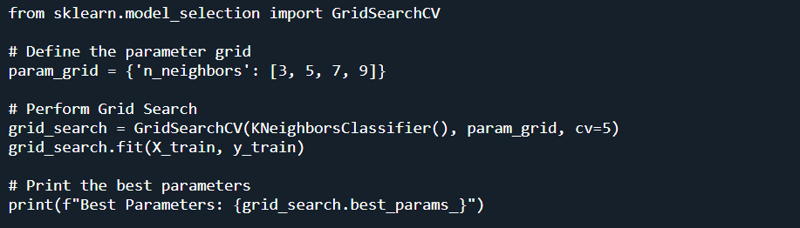
Conclusion
Scikit-Learn is a powerful and beginner-friendly library that simplifies the process of building machine learning models in Python. By following the steps outlined in this guide, you can load data, preprocess it, train models, and evaluate their performance. As you gain more experience, you can explore advanced techniques like hyperparameter tuning and feature engineering to build even more accurate models.
Whether you're a mobile app developer looking to integrate machine learning into your applications or a data enthusiast exploring the world of AI, Scikit-Learn provides the tools you need to get started. With its extensive documentation and active community, mastering Scikit-Learn is a valuable skill that can open doors to exciting opportunities in the field of machine learning.

Top comments (1)
Good share!