This post is sponsored by SugarKubes, a container marketplace for developers. Check out some of our latest demos.
When deploying deep learning models, especially in the embedded systems space, you often don’t have a GPU available due to cost or other considerations. Though this is rapidly changing with specialized boards like the Google Coral, or the movidius stick, the majority of edge devices do not have any kind of hardware on board to handle a deep neural net. Enter OpenVino to save the day.
Openvino
A newer option that might work for your product at a price point a lot lower than adding a GPU to your board is Intel’s OpenVino. On modern i-series chips and recent Xeons, they have the ability to run deep neural nets with the GPU on the chip. And it’s super fast! How fast you ask?
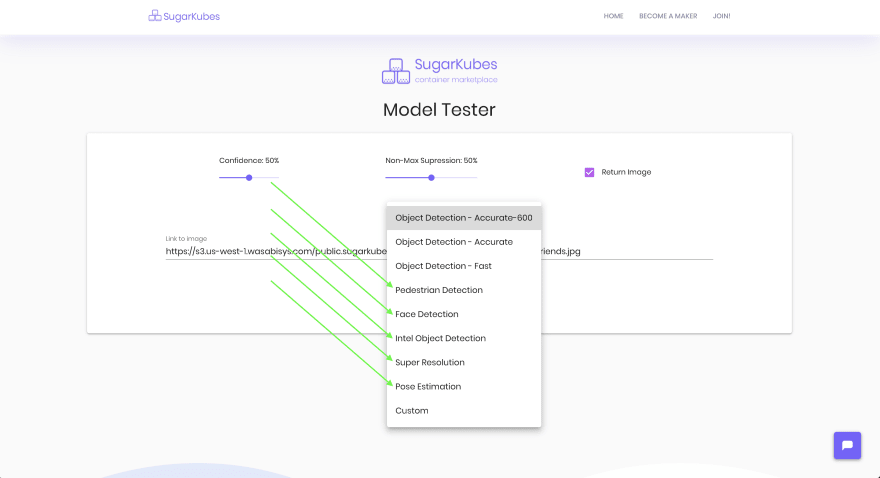
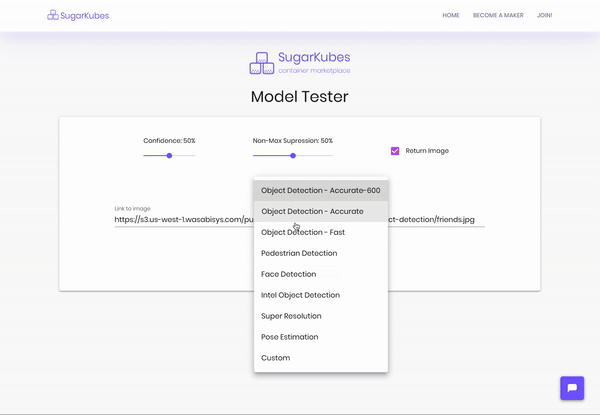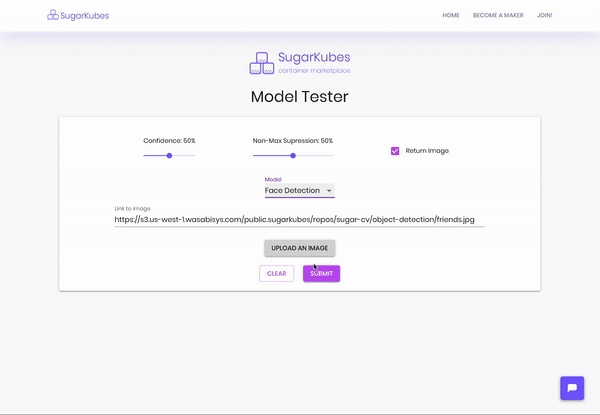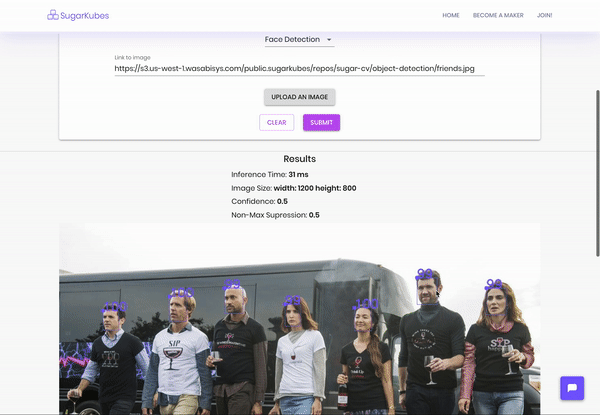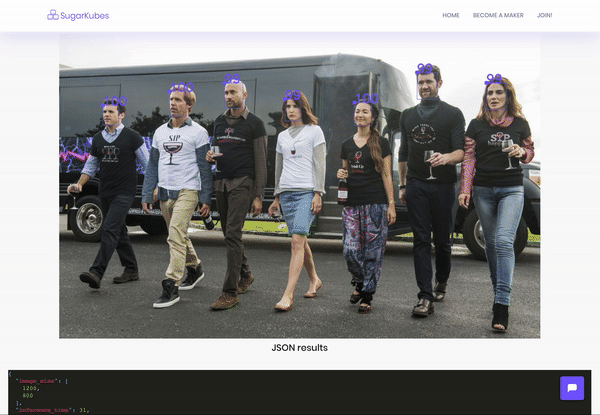
Take a look for yourself. The dropdown items with arrows next to them are Openvino models you can demo. Note the inference times, they’re super quick. The rest of the delay is network and image processing (you can stop returning the image for faster inferences).
OpenVino on EC2
How fast? I’m glad you asked. Let’s spin up an instance on AWS and see how fast we can get some of these models to run.
EC2 instances come with Intel Xeon processors (or partials). So I will be spinning up a T2.Medium. You can run Openvino models on them with decent processing times straight from the cloud! Or it can also be a great embedded solution if you’re lucky enough to have an x86 board with an Intel processor like the NUC series.
Fire up a new EC2 instance and hop in!
I'll be on a T2.Medium
ssh ubuntu@whatever
In order to run the model, we’re going to install Docker and log in to the SugarKubes hub. If you want to just check out the demo, you can do so here. I’ve also created an OpenVino base image so you can more quickly build and deploy OpenVino models yourself, it’s available on Github andDocker Hub.
sudo apt update
sudo apt install docker.io
log in to the sugar registry
docker login registry.sugarkubes.io
Run the pedestrian detection container! Don't forget to open up the ports to the outside world!
docker run --rm -dti \
-p 9090:9090 \
-p 9001:9001 \
registry.sugarkubes.io/sugar-cv/intel-pedestrian-detection:latest
And that’s it! We now have a deep learning pedestrian detector running in the cloud on a simple EC2 instance. The difference? The inference time for this model is <50MS on a CPU. That’s crazy. P.S. this container is stateless, so throw it on to an autoscaling group or a Kubernetes cluster and you shouldn’t ever have to touch it again.
The Intel OpenVino models available on SugarKubes
OpenVino on GKE, GC, GCR
OpenVino on GKE as well as GC Compute Instances will work fine. They have Xeon Skylake processors available!
I’m obsessed with Google’s new Cloud Run. You can point it at a container and it will manage autoscaling up and down and automatically serves over https. It’s amazing, however, I couldn’t get OpenVino models to run on it, and they don’t provide a way to hop in the containers that I’ve been able to see. As the service goes out of beta hopefully it will be possible to run OpenVino models because that would be 🔥.
Hope you’ve enjoyed the post! If you’re interested in learning more about the containers available onSugarKubes, please consider joining our mailing list.
If you’re interested in getting free containers, invite 10 people and get access to a container of your choice, up to $100!

Top comments (0)