
Hello, fellow readers. I hope you are having an amazing time seeing all the things happening in the tech world (except the layoffs :( ). I hope you might have had the chance to read my last blog; if you didn't, please give it a go. You can find the link below:
Previous Blog: https://dev.to/anuttamanand/docker-10-the-basics-2a1g
Today, we are going to talk about how we communicate on the internet. We will dive a little bit into the basics and then sail into how to scale and what parts can be scaled using our Docker and container systems. Let's go..!!
The Magical Two Words (Not "Love You" but "Client-Server")
Every machine on the internet, whether it's a server, your computer, or a laptop, communicates with each other through a special address known as an IP Address (Internet Protocol Address). If multiple devices are connected to a WiFi network and you want to distinguish between them or perhaps block one of them, one method is to check their IP and perform the respective task.
A machine is identified by its IP address. However, when we type something in our browser like https://google.com, it goes to a server. But is it only the IP that is locating Google's machine and serving the content? The answer lies in the good old processes. If you have ever worked on developing a backend server application like Django, Node.js, etc., you might have noticed that there's always a Port assigned when you run the server. This port might conflict sometimes if it is being used by another process.
To send a request, you need two things: an IP and a port. Think of it like this: if your request reaches the server, what happens next? Where should it go? The port in the URL defines this and informs the computer that you want to reach a specific process, like port 8000 where your server might be running. The server then handles the request based on this port number.
So, the IP serves as our machine identifier, and the port serves as our process identifier. Together, they are used in a Client-Server Architecture to facilitate requests. In this architecture, the client, like a browser, requests something, and the server, the process handling that request, communicates with the client. This communication between the client and server occurs through sockets.
The 3 Tier Architecture
In our previous discussion, we explored the client-server architecture, a fundamental two-tier system where two devices communicate with each other: the client (often a browser) and the server. However, when we introduce a database into this setup, it transforms into a three-tier architecture. In this scenario, the interaction between the browser and server remains as the client-server relationship. Simultaneously, a new layer is added: the interaction between the server and the database forms another client-server relationship. Here, the server acts as the client, querying the database server, which serves as the server in this context. This three-tier architecture enhances the complexity and functionality of the system, enabling seamless communication and data management between different components.
Scalability
On the server side, there are various crucial components such as the database, caching server, message queue, load balancer, and many more. But how do we ensure that our system can handle an increasing number of users and their requests seamlessly? This is where scalability comes into play.
What is Scalability?
Imagine you have a server that serves requests from clients. There's a limit to the number of requests it can handle per unit of time, say 100 requests per second. However, if the concurrent users increase significantly, let's say to 1000, you need a solution to serve all these requests while keeping your application smooth and responsive. One approach might be to use a queue and store requests in it, resolving them one at a time. However, even a queue has limitations in terms of the number of requests it can store, which doesn't provide a sufficient solution to enhance performance.
Here's where Scalability comes in. In simple terms, scalability refers to increasing your computing power to handle a larger number of requests effectively.
Scalability has two types:
- Vertical Scalability
- Horizontal Scalability
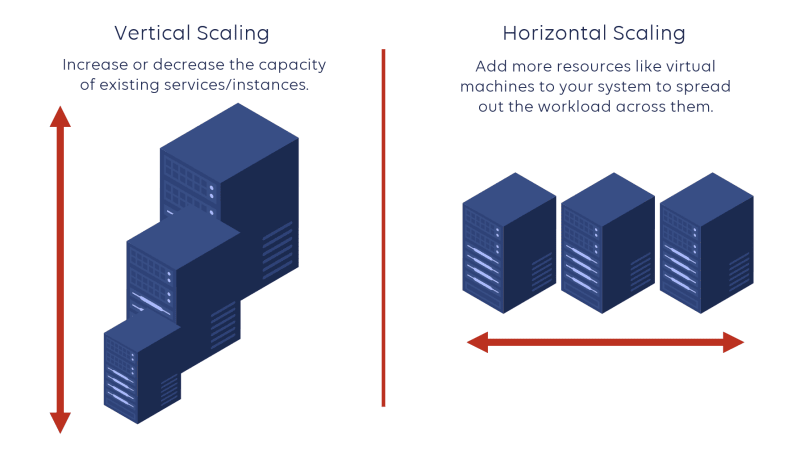
Vertical Scalability: Enhancing Power, One Machine at a Time
In vertical scalability, the focus is on a single machine, and the strategy involves increasing the machine's capabilities by upgrading its components, such as RAM and CPU cores. A classic example of this approach is seen in AWS EC2 instances, which offer a variety of configurations tailored to specific needs.
However, there's a catch: as you augment the resources of a single machine, the costs soar. Depending on the use case, budget constraints become a significant consideration. Moreover, there's a practical limit to how much a single machine can be upgraded. Eventually, the pursuit of more power becomes financially impractical or technically unfeasible. Consider this scenario: you need a machine with 24 GB of RAM, but the available options jump from 16 GB to 32 GB. Opting for the 32 GB machine means paying for 8 GB of unused resources. The solution to this is Horizontal Scaling.
Horizontal Scaling: Expanding Horizons, One Server at a Time
Horizontal scaling, the ingenious solution to the limitations of vertical scalability, involves distributing requests across multiple machines, denoted as S1, S2... Sn, based on the demand. Picture this: you have ten machines, each equipped with 8GB of RAM, adapting dynamically to your requirements.
Load Balancer: The Traffic Manager
The Load Balancer steps in with a simple "Hello!"
Understanding Load Balancers
A Load Balancer is the unsung hero that stands between our client and server. Instead of reaching out directly to the server, the client first talks to the Load Balancer, sharing its requests and details (like IP addresses and more).
How It Works
The Load Balancer uses clever algorithms like Round Robin to divide incoming requests among multiple servers. For instance, if there are 3 servers (S1, S2, S3), the requests are distributed sequentially: R1 goes to S1, R2 goes to S2, R3 goes to S3, and then back to S1 with R4. It's a straightforward and fair system, ensuring each server shares the workload.
With its algorithms and precision, the Load Balancer ensures smooth traffic flow. It avoids congestion, keeps servers in check, and guarantees a seamless online experience. It's the silent force behind the scenes, making sure your digital interactions remain fast and uninterrupted.

A question arises now that if a server cannot handle that many requests, then how will a load balancer handle all and distribute them. The answer to this is how we measure the load on the machine. A server's main responsibility is running the application logic, so most of its resources are consumed in that whereas a Load Balancer's job is only to accept requests and forward them, so it can use all of its resources for that purpose and can handle a greater number of requests.
Stateless V/s Stateful
I hope you have a good understanding of the basics of client-server communication and why we need to scale systems. We already talked about the difference between vertical and horizontal scaling, so what's more to scaling? Let's first understand what we mean by state.
When we talk about a two-tier system, i.e., client and server, we send a request to a server. The server performs some logic calculations and sends us a response. But will this system work if we are sending and receiving money? We are not storing who sent how much money to whom. That's where we connect databases to our backend. When we make a request, we have a previous record of transactions. That's broadly what stateful systems are defined as. In a three-tier system, our server is stateless, but our database is stateful.
Scaling Stateless Systems
In stateless systems, the aim is to avoid persisting any data from the client. When multiple clients send requests, we don't inherently know which request is from which client until cross-referenced through our database (which is a characteristic of stateful systems). To handle this, we can create numerous replicas of our stateless application and connect them to a load balancer. The load balancer ensures that all requests are evenly distributed among these replicas.
Consider a practical example: let's say we have a calculator web app where clients send arithmetic calculations, and the server processes and returns the output. If we deploy the same application on 5 servers and send identical requests to all 5, we will receive the same response. In a stateless application, any server can handle the request. This inherent flexibility allows stateless systems to scale effortlessly, making them highly adaptable to varying workloads and client demands.
Scaling Stateful Systems
For anyone familiar with databases, indexing rows based on specific criteria is common practice to quickly find desired records. However, as the number of records grows, searching through millions of rows becomes time-consuming and challenging. But how does this indexing methodology apply to stateful systems?
Consider a scenario involving a bank database where distributing the request load is essential. One approach is to create 'n' replicas of the database. However, managing synchronization across these replicas becomes a significant challenge. When one replica is updated, that information must be transferred to all other replicas. While this method can work for smaller services, it becomes inefficient for applications processing thousands of requests per second. The time taken for each database to sync with others significantly increases response times. While this method helps reduce read times, it's not effective when it comes to writing to a database.
A widely adopted alternative is Sharding. Instead of creating replicas, sharding involves dividing all database records into multiple databases managed separately. For instance, you can have separate databases for different customers, with each database handling the requests for its specific customer. This way, when a request comes from a particular customer, the system can directly query the corresponding database (e.g., DB1 for Customer 1). Sharding enables efficient data management, optimizing both read and write operations, and is a popular choice for scaling stateful systems effectively.

Failure Handling
Imagine a scenario where everything is functioning seamlessly. Requests flow through the load balancer, forwarding them to servers, ensuring a smooth user experience. But suddenly, one of our servers crashes, ceasing to respond to incoming requests. Now, we are left with Sn - 1 servers, potentially overburdening the remaining servers and increasing the response time.
This example illustrates a common failure scenario that can occur during the normal operation of our system. To address this in a stateless system, we follow a straightforward approach: we retire the faulty server and create a new one with identical configurations (essentially creating a new "replica").
Once the new replica is up and running, the load balancer directs new requests to it. The system seamlessly resumes its operation, distributing requests across the available servers just as before. This quick replacement strategy ensures that the system can adapt swiftly to failures, maintaining a responsive and reliable user experience.
Summary
In this blog, we talked about how client server interacts with each other. We also looked into stateless and stateful systems and how we apply different scaling methodologies depending upon use case.
In the next blog, we will do hands on for docker and will look into each of its component and how they all work under the hood.
Thanks for reading! Waiting for your comments. Please like and share.
You can follow me on :
- X (formerly Twitter): https://twitter.com/AnuttamAna56189
- LinkedIn: linkedin.com/in/anuttam-anand
Always open for DMs :)

Top comments (0)