
This article will show how column propagation can represent an easy approach to improving query performance when dealing with a hierarchical data structure.
We'll do this with a real-world scenario based on a data-driven project involving a live data website developed for a startup operating in the sports industry. You'll learn everything you need to know about column propagation as a solution to the performance issues inherent in hierarchical SQL table structures. Let's begin.
The context
My team and I recently worked on a website for soccer fans having millions of pages. The idea of that website is to be the definitive resource for soccer supporters, especially when it comes to betting. The database and application architecture are not particularly complex. This is because a scheduler takes care of periodically recalculating complex data and storing it in tables so that the queries will not have to involve SQL aggregations. So, the real challenges lie in non-functional requirements, such as performance and page load time.
Application domain
There are several data providers available in the sports industry, and each of them offers its clients a different set of data. Specifically, there are four types of data in the soccer industry:
- Biographical data: height, width, age, teams they played for, trophies won, personal awards won, and soccer players and coaches.
- Historical data: results of games played in the past and the events that occurred in those games, such as goals, assists, yellow cards, red cards, passes, etc.
- Current and future data: results of games played in the current season and the events that occurred in those games, as well as tables of future games.
- Live data: real-time results and live events of games in progress.
Our website involves all these kinds of data, with special attention to historical data for SEO reasons and live data to support betting.
Hierarchical table structure
I cannot share the entire data structure with you because of an NDA I signed. At the same time, understanding the structure of soccer seasons is enough to understand this real-world scenario.
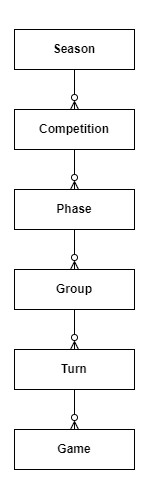
In detail, soccer providers generally organize data on games in a season as follows:
- Season: has a start and end date and generally lasts one calendar year
- Competition: the league a game belongs to. An instance of competition lives inside a season. Learn more about how soccer competitions work here.
- Phase: the stage associated with the competition (e.g., qualifying stage, knockout stage, final stage). Each competition has its own rules, and many only have one phase.
- Group: the group associated with the phase (e.g., group A, group B, group C, …). Some competitions, such as the World Cup, involve different groups, each with its team. Most competitions only have one general group for all teams.
- Turn: corresponds to one day of competition from a logical point of view. It usually lasts one week and covers the games played by all the teams that are part of a group (e.g., MLS has 17 home games and 17 away games; therefore, it has 34 turns).
- Game: a match between two soccer teams.
As shown below in the ER schema, these 5 table represents a hierarchical data structure:
Technologies, specs, and performance requirements
We developed the backend in Node.js and TypeScript with Express 4.17.2 and Sequelize 6.10 as ORM (Object Relational Mapping). The frontend is a Next.js 12 application developed in TypeScript. As for the database, we decided to opt for a Postgres server hosted by AWS.
The website runs on AWS Elastic Beanstalk with 12 instances for the frontend and eight instances for the backend and currently has from 1k to 5k daily viewers. Our client's goal is to reach 60k daily views within a year. Therefore, the website must be ready to host millions of monthly users without performance drops.
The website should score 80+ in performance, SEO, and accessibility in Google Lighthouse tests. Plus, the load time should always be less than 2 seconds and ideally in the order of a few hundreds of milliseconds. The real challenge lies here, since the website consists of more than 2 million pages, and pre-rendering them all will take weeks. Also, the content shown in most of the pages is not static. Thus, we opted for an incremental static regeneration approach. When a visitor hits a page no one ever visited, Next.js generates it with the data retrieved from the APIs exposed by the backend. Then, Next.js caches the page for 30 or 60 seconds, depending on the importance of the page.
So, the backend must be lighting fast in providing the server-side generation process with the required data.
Why querying hierarchical tables is slow
Let’s now look at why a hierarchical table structure can represent a challenge for performance.
JOIN queries are slow
A common scenario in a hierarchical data structure is that you want to filter leaves based on parameters associated with objects higher up in the hierarchy. For example, you may want to retrieve all games played in a particular season. In this case, since the leaf table Game is not directly connected to Season, you must perform a query involving as many JOIN as there are elements in the hierarchy.
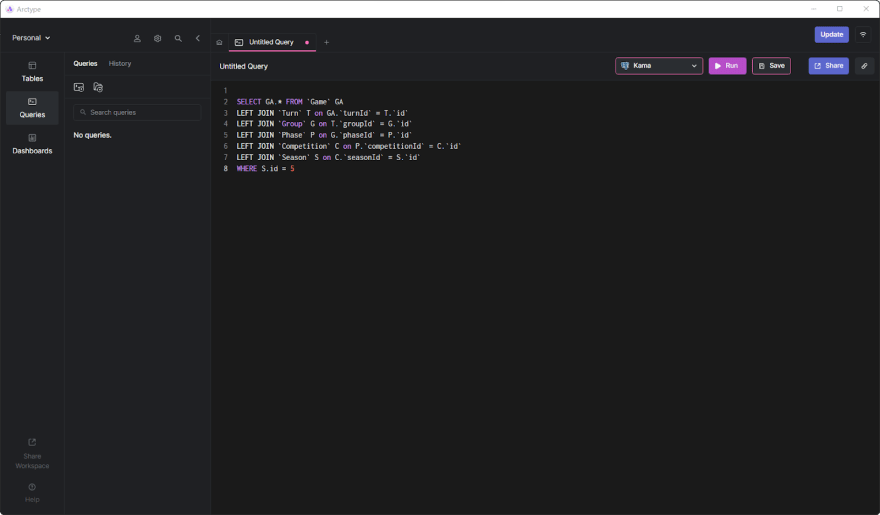
So, you might end up writing this query:
SELECT GA.* FROM `Game` GA
LEFT JOIN `Turn` T on GA.`turnId` = T.`id`
LEFT JOIN `Group` G on T.`groupId` = G.`id`
LEFT JOIN `Phase` P on G.`phaseId` = P.`id`
LEFT JOIN `Competition` C on P.`competitionId` = C.`id`
LEFT JOIN `Season` S on C.`seasonId` = S.`id`
WHERE S.id = 5
Such a query is slow. Each JOIN performs a Cartesian product operation, which takes time and may result in thousands of records. So, the longer your hierarchical data structure is, the worse it is regarding performance.
Also, if you want to retrieve all data and not just the columns in the Game table, you will have to deal with thousands of rows with hundreds of columns due to the nature of the Cartesian product. This can become messy, but this is where ORM comes into play.
ORM data decoupling and transformation takes time
When querying a database through an ORM, you are typically interested in retrieving data in its application-level representation. Raw database level representation may not be useful at the application level. So, when most advanced ORMs perform a query, they retrieve the desired data from the database and transform it into its application-level representation. This process involves two steps: data decoupling and data transformation.
Behind the scenes, the raw data from the JOIN queries is first decoupled and then transformed into the respective representation at the application level. So, when dealing with all data, the thousands of records with hundreds of columns becomes a small set of data, each having the attributes defined in the data model classes. So, the array containing the raw data extracted from the database will become a set of Game objects. Each Game object will have a turn field containing its respective Turn instance. Then, the Turn object will have a group field storing its respective Group object, and so on.
Generating this transformed data is an overhead you are willing to accept. Dealing with messy, raw data is challenging and leads to code smells. On the other hand, this process happening behind the scene takes time, and you cannot overlook it. This is especially true when the raw records are thousands of rows since dealing with arrays storing thousands of elements is always tricky.
In other words, common JOIN queries on hierarchical table structure are slow at both the database and application layers.
Column propagation as a solution
The solution is propagating columns from parents to their children in a hierarchical structure to avoid this performance issue. Let’s learn why.
Why you should propagate columns on hierarchical databases
When analyzing the JOIN query above, it is evident that the problem lies in applying a filter on the leaf table Game. You have to go through the whole hierarchy. But since Game is the most important element in the hierarchy, why not add the seasonId, competitionId, phaseId, and groupId columns directly to it? This is what column propagation is about!
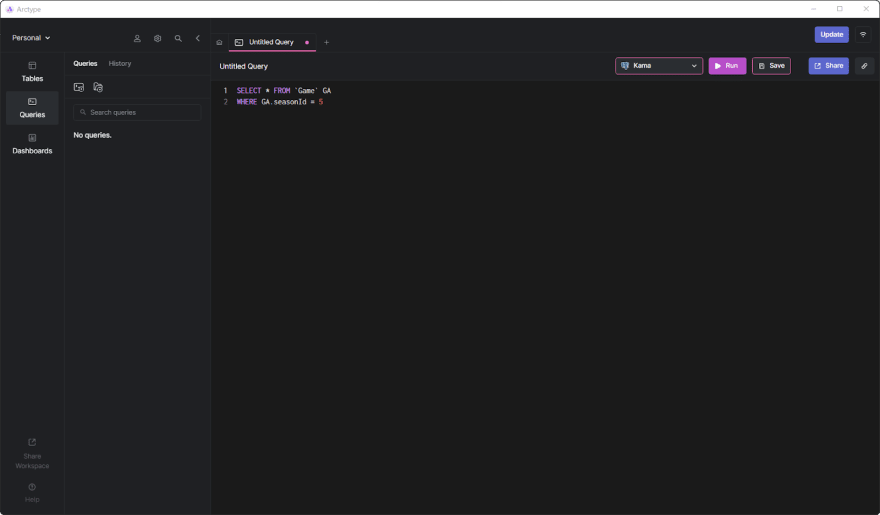
By propagating the external key columns directly to the children, you can avoid all the JOINs. You could now replace the query presented above with the following one:
SELECT * FROM `Game` GA
WHERE GA.seasonId = 5
As you can imagine, this query is much faster than the original one. Also, it returns directly what interests you. So, you can now overlook the ORM data decoupling and transformation process.
Notice that column propagation involves data duplication, and you should use it sparingly and judiciously. But before delving into how to implement it elegantly, let’s see which columns you should propagate.
How to choose the column to propagate
You should propagate down each column of the entities that are higher in the hierarchy that might be useful when it comes to filtering. For example, this involves external keys. Also, you might want to propagate enum columns used to filter data or generate columns with aggregate data coming from the parents to avoid JOINs.
Top 3 approaches to column propagation
When my team opted for the column propagation approach, we considered three different implementation approaches. Let’s analyze them all.
1. Creating a materialized view
The first idea we had to implement column propagations in a hierarchy table structure was to create a materialized view with the desired columns. A materialized view stores the result of a query, and it generally represents a subset of the rows and/or columns of a complex query such as the JOIN query presented above.
When it comes to materialized queries, you can define when to generate the view. Then, your database takes care of storing it on the disk and making it available as if it were a normal table. Even though the generation query might be slow, you can launch it only sparingly. So, materialized views represent a fast solution.
On the other hand, materialized views are not the best approach when dealing with live data. This is because a materialized view might not be up-to-date. The data it stores depends on when you decide to generate the view or refresh it. Also, materialized views involving large data take a lot of disk space, which may represent a problem and cost you money in storage.
2. Defining a virtual view
Another possible solution is using a virtual view. Again, a virtual view is a table that stores the result of a query. The difference with a materialized view is that this time your database does not store the results from the query on the disk but keeps it in memory. So, a virtual view is always up to date, solving the problem with live data.
On the other hand, the database has to execute the generation query every time you access the view. So, if the generation query takes time, then the entire process involving the view cannot but be slow. Virtual views are a powerful tool, but we had to look for another solution considering our performance goals.
3. Using Triggers
SQL triggers allow you to automatically launch a query when a particular event happens in the database. In other words, triggers give you the ability to synchronize data across the database. So, by defining the desired columns in the hierarchy tables and letting the custom-defined triggers update them, you can easily implement column propagation.
As you can imagine, triggers add performance overhead. This is because every time the events they wait for happen, your database executes them. But performing a query takes time and memory. So, triggers come with a cost. On the other hand, this cost is generally negligible, especially when compared with the drawbacks coming with virtual or materialized views.
The problem with triggers is that defining them might take some time. At the same time, you can tackle this task only once and update them if required. So, triggers allow you to easily and elegantly implement column propagation. Also, since we adopted column propagation and implemented it with triggers, we have managed to meet the performance requirements defined by the customer by a wide margin.
Final thoughts
Hierarchy structures are common in databases, and if not approached correctly, they might lead to performance issues and inefficiencies in your application. This is because they require long JOIN queries and ORM data processing that are slow and time-consuming. Luckily, you can avoid all this by propagating columns from parents to children in the hierarchy. I hope this real-world case study helps you build better and faster applications!

Top comments (0)