The late 2000s saw a new type of database emerge to address a rapidly increasing number of opportunities and problems related to storing vast amounts of data.
These non-relational databases were grouped under the term NoSQL and offer flexible schemas, better scaling, and fast queries but do not support ACID transactions.
It did not take long for someone to come up with a proposed fix, and in 2011 a 451 Group analyst named Matthew Aslett coined the term 'NewSQL.' A new type of relational database was born to provide the scalability of NoSQL while maintaining the traditional ACID guarantees.
After 10 years and countless articles about how "now is the time," we are left wondering why NewSQL never really caught on. This article will discuss the technical details, why NewSQL makes a lot of sense theoretically, and what we can learn from its practical failure.
The Rise of NoSQL
To delve into what NewSQL is—and was supposed to be—we must first briefly recap the history of NoSQL, which, in turn, is best understood as an alternative to relational databases.
Based on the tuple-relational calculus first introduced by Edgar F. Codd in 1970 in his seminal paper “A Relational Model of Data for Large Shared Data Banks,” the relational database arranges data into different rows and columns, associating a specific key for each row.
Almost all relational database systems use Structured Query Language (SQL), which was first introduced when Donald Chamberlin and Raymond Boyce published “SEQUEL: A Structured English Query Language.” After that, there was no stopping the boom of relational databases, which are dominant to this day. For a more detailed history of the 50-year reign of SQL, check out one of my prior blog posts.
SQL databases tend to be more rigid and controlled systems and offer only limited ability to translate complex data such as unstructured documents. Which meant that—with the internet rapidly gaining extreme popularity in the mid-1990s— relational databases simply could not keep up with the flow of information demanded by users, as well as the larger variety of data types necessary.
NoSQL was developed to fill this newfound need to process large amounts of unstructured data quickly. The acronym itself was first used in 1998 by Carlo Strozzi for his open-source “relational” database and reused by both Eric Evans and Johan Oskarsson to describe their non-relational databases. The most common interpretation of the term is “Not only SQL,” to emphasize the fact some systems might still support SQL-like query languages.
Not only can NoSQL systems handle both structured and unstructured data, but they can also process unstructured Big Data quickly due to their distributed nature. The non-relational system is quicker, uses an ad-hoc approach for organizing data, and processes large amounts of different data. These capabilities lead organizations such as Twitter, Facebook, LinkedIn, and Google to adopt NoSQL as part of their tech stack.
The Many Flavors of NoSQL
NoSQL is a flexible term used to describe many specialized data store designs that tend to be flexible themselves. Those data stores are usually optimized for specific purposes but can be categorized into a few main types.
NoSQL Key-Value Databases

A Key-Value Store, also called a Key-Value Database, is a data storage system that uses a simple key-value method to store data. These databases contain a simple string (the key) that is always unique and an arbitrarily large data field (the value). They are easy to design designed for storage, retrieval, and managing “associative arrays.”
Document Databases using NoSQL

A Document Store is a non-relational database designed for storage, retrieval, and managing “document-oriented information,” which is also referred to as semi-structured data. Document Databases save all information for a given item as a single instance in a database, making it easy to map items into the database. A document can be a PDF, a document, or an XML or JSON file.
Time-series NoSQL Databases

A time-series database is a database system designed to store and retrieve timestamped data. It is "optimized for fast, high-availability storage and retrieval of time series data in fields such as operations monitoring, application metrics, Internet of Things sensor data, and real-time analytics."
NoSQL Graph Databases

Graph databases store data in the form of nodes, using flexible graphical representation to manage data. Each node is connected to another, and the connection is called an “edge” and represents a relationship between two nodes. These databases are optimized to store relationships between data objects (such as followers on Twitter or common lawyers in Panama).
Wide-Column Databases Implementing NoSQL

Wide-column stores use the typical tables, columns, and rows, but unlike standard relational databases, formatting and names can vary from row to row inside the same table. They use persistent, sparse matrix, multi-dimensional mapping meant for massive scalability.
Search-engine NoSQL Databases

Search-engine databases are non-relational databases dedicated to searching data content through indexes to categorize similar characteristics among data and facilitate search capability. Many of them are open-source, and they are often kept alongside other non-relational databases.
AI Databases

AI databases are a fast-emerging database approach dedicated to creating better machine-learning and deep-learning models and then train them faster and more efficiently. They sometimes use graphics processing units to deploy a distributed, memory-first database management system.
What Are ACID and BASE Consistency Models?
Both relational and non-relational models come with strengths and weaknesses. The relational model comes with a built-in, foolproof way of guaranteeing relationships between records through primary and foreign keys. This makes them very effective at joins and helps to ensure business logic and trustworthiness at the database layer. Data is stored across several tables, which provides redundancy and security, but limits flexibility.
Trying to provide a full list of pros and cons for NoSQL databases would be not only prohibitively complicated but also point-less since each kind of NoSQL database has its specialized use case. Rather than try to make an incomplete or confusing list of all possible variations it makes more sense to focus on the most significant downfall of the non-relational model: ACID Guarantees.
This downfall is also the one that NewSQL tries to address in their database models. To understand why it is such a big deal, let's look at a little bit of theory.
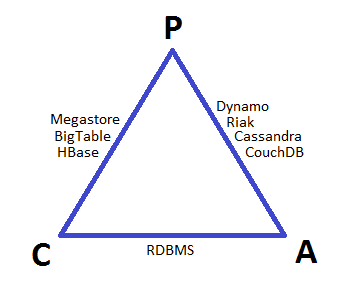
The CAP Theorem
The CAP Theorem states that a distributed data store “cannot” simultaneously offer more than “two of three” established guarantees. Eric Brewer published the CAP Principle in 1999, and a formal proof of his concept was published by Nancy Lynch and Seth Gilbert of MIT followed in 2002.
The CAP acronym stands for the three guarantees that cannot be met simultaneously:
- Consistency: The data is always consistent (even after an operation has been executed.
- Availability: The system is always available (no downtime)
- Partition Tolerance: Even if communication among the servers is no longer reliable, the system will continue to function.
Two Models of Consistency
In light of the restrictions posed by the CAP principle, two popular consistency models developed, which are in turn also acronyms.
ACID stands for Atomicity, Consistency, Isolation, and Durability, while BASE stands for Basically Available.
ACID guarantees a safe environment for processing data. This means data is consistent and stable and may use multiple memory locations.
BASE is an alternative to that model and focuses on availability for scaling purposes. It provides less assurance than ACID but lends itself to the use cases of NoSQL databases.
This brings us to the crucial problem NewSQL is trying to address.
NewSQL's Founding Principle: "Why not both?"

10 years ago, Matthew Aslett asked what could be done about providing the scalability of NoSQL without giving up ACID guarantees and decided to call these sorts of solutions NewSQL.
He later admitted that the creation of this new database category was “kind of accidental” and that "if we knew the term would take off, we would have put more thought into exactly what it was ahead of time.” The goal was to describe a group of products trying to do something new with a relational SQL database model and, therefore, certainly fit at the time.
While the phraseology seems outdated now (none of the NewSQL databases are very new anymore), they share a set of characteristics that have remained the same over the years. Utilizing in-memory storage, partitioning, sharing, and concurrency controls are used by almost all of them, even though implementations differ from vendor to vendor. The thing that connects these applications is the central idea that "takes the best bits of the relational database and applies it to distributed architecture.”
Therefore, NewSQL systems tend to focus on providing high levels of scalability while remaining **ACID-compliant **without relying on large-scale computational architectures (like cloud technology).
While there is some leeway in describing exactly which vendors are "officially" part of the NewSQL ecosphere, the most common examples include vendors like:
- Amazon Aurora
- Altibase
- Apache Trafodion
- Google Cloud Spanner
- Clustrix
- NuoDB
- HarperDB
- VoltDB
- MemSQL
- CockroachDB
Each of these applications has its benefits and strengths, but in general, it is hard to find something fundamentally wrong with the NewSQL ethos. It's certainly possible to provide NoSQL-like scaling while also maintaining ACID guarantees, and this raises the big question.
Why did NewSQL fail?
A decade after the term was first coined, it has become obvious that NewSQL tools probably won't be the future of database technologies. You might feel that this statement is a bit too harsh, but I actually think it is rather fair and even conservative.
While there certainly are individual NewSQL vendors that have established a niche in the market and are boasting moderate success, the category is losing the little market share it had quickly. This becomes evident when looking at the most popular databases in the market.

Even if you believe that I am a bit too sensationalist in declaring the NewSQL category a failure, you would still need to explain why not one of these databases has achieved mass adoption. After all, shouldn't a solution that offers the best of relational and non-relational database systems have some sort of appeal to developers? What could it be that is keeping them from using their theoretically superior products?
One hypothesis could be that these databases are still too new. This seems unlikely since they are almost as old as most NoSQL databases. Another reason could be NewSQL databases actually don't deliver what they promise. Considering that at least some vendors (like VoltDB) seem to have had limited success, I feel like the main goal of NewSQL is certainly achievable.
So what is it that is holding them back? The rise of cloud computing and lack of specialization seems to be the most likely culprits.
Cloud Adoption: NewSQL Killer?
NewSQL just happened to compete to save the same problem as cloud technology. With the rise of the internet, many enterprise systems that handle high-profile data (e.g., financial and order processing systems) became too large for conventional relational databases. Some of these were converted to non-relational systems, but others had to still meet transactional and consistency requirements that were not possible with NoSQL technology and BASIC consistency.
To solve this, organizations were forced to either purchase more powerful computers or develop costly middleware that distributes requests over conventional DBMS. That exact use case is where NewSQL was supposed to shine and take the market by storm. It just so happens that a fourth option was gaining massive popularity. Cloud computing allows organizations to scale standard relational models without having to buy extra computers or build custom solutions.
Ideal Use Cases for NewSQL? Almost None.
There is a good reason why there are so many different kinds of databases. If individual categories tend to break down further and further into custom build solutions to specific use cases. This is because data is incredibly varied, and it often pays to deploy different kinds of technology for different kinds of data.
The best NewSQL databases know this and managed to fill very specific use cases. The less successful ones are still impressive kinds of technology but don't solve any single problem better than a more specialized SQL or NoSQL database.
The Story of NewSQL: All that glitters is not gold
Terrabytes of unstructured data flowing through the world wide web at the speed of light caused many problems. NoSQL databases promised to solve a lot of these problems but could only do so by sacrificing consistency.
NewSQL tried to step in and offer a solution that could do both. I've shared my thoughts on what limited its adoption; cloud adoption and a lack of specialized solutions.

Top comments (1)
These systems often pose as a drop-in replacement for their SQL counterpart. Is it a bad idea to just replace my postgres DSN string with a cockroachDB address as of today?