
CI/CD (Continuous Integration, Continuous Delivery) is the practice of frequently deploying software to environments using automated deployments. Organisations use CI/CD to deploy application updates but they can also use CI/CD to deploy infrastructure updates.
In this post, we will use Terraform and Azure DevOps to build a CI/CD pipeline which will deploy infrastructure updates to environments hosted in Azure.
Terraform
Terraform is an infrastructure as code tool. We can use Terraform to create, change and destroy infrastructure resources. Terraform uses YAML files to define resources. We can check these files into source control and use code review tools to review, share and collaborate on changes before infrastructure is updated.
This post assumes the reader has some basic knowledge of Terraform, including understanding how to plan and apply changes.
Azure DevOps
Azure DevOps is a set of services development teams can use to manage software development projects. We will use Azure Pipelines to manage our build and deployments.
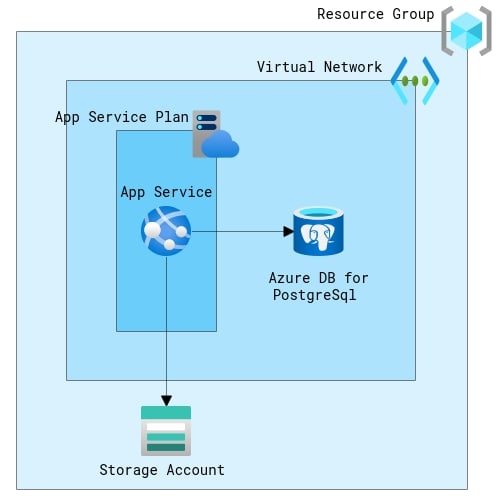
Azure Environments
We will assume the infrastructure is hosting a simple web application which will consist of:
- A monolithic web application
- A backing PostgreSQL database
- A file store
We will use Azure PAAS services to host the application as follows:
- App Services to host the web application
- Azure PostgreSQL to host the database
- Storage Accounts for file storage
Environment Topology
We will define two environments, one for test and one for production. The environment topology is similar in both environments but may vary in resource count and configuration.
Pipeline Design
Build Once
When building a CI/CD pipeline it is advisable to build once and promote the result (a single build artefact or binary) through the pipeline stages (environments). This prevents problems that may arise when software is compiled or packaged multiple times allowing slight differences to be included in the artefacts. Deploying different software to different stages of a pipeline may introduce inconsistencies. These inconsistencies may invalidate test that passed on previous stages.
Users will typically generate a separate Terraform build artefact (a plan) for each environment.
Fortunately, we can use Terraform modules to partially overcome this issue. We will define application “stacks” in reusable modules. These stacks define all the infrastructure required for the application to run. We can then deploy the application infrastructure consistently to each environment and use environment-specific root modules to control environment-specific (SKU, tiers, etc) configurations.
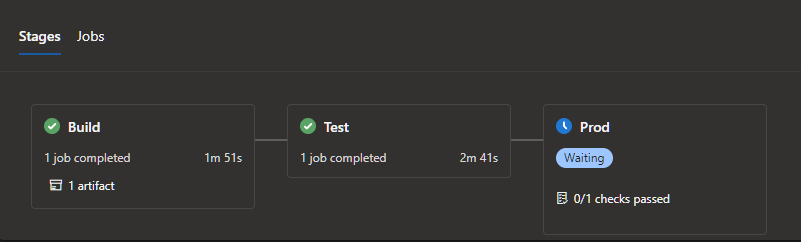
Stages
The pipeline will consist of three stages:

Build
This stage will produce a build artefact that will contain a terraform plan for each environment.
Test
This stage will apply the test plan to the test environment and execute any necessary tests.
Prod
This stage will apply the production plan to the production environment and execute any necessary tests.
The Implementation
This repository contains all code referenced in this post. As we will be interacting with Azure resources the Azure CLI should be installed locally.
Code the Infrastructure
Global Variables
We will use a module to declare global variables.
Backend
Terraform maintains an internal representation of infrastructure it is managing. This representation is persisted to a state file and is used each time terraform generates a plan. We will store this state file in an azure storage account and configure terraform to use this storage account. We will create a module to manage the creation of the backend storage account.
Web App Stack
We will create a module which declares all infrastructure components needed to host the web application. Each environment module references this module.
Modules contain inputs, resources and outputs. Inputs are defined in inputs.tf as follows:
The resources are defined in the main.tf file as follows:
A module can also define outputs which can be used by referencing terraform files.
Environments
Next, we will create the environment modules, one for test and one for production. These are found in infra/azure/terraform/envs.
As we do not want to store the Postgres DB credentials in our terraform files. We will declare two input variables for these. We will pass these variables via command-line arguments as the environment modules are root modules.
We declare the terraform block, azure backend and provider in main.ft:
We then declare the web-app module and any environment-specific resources in a separate file:
Creating and Destroying Infrastructure
Create the backend
The backend is initialised manually as follows:
cd infra/azure/terraform/backend
az login
terraform init
terraform plan
terraform apply
Create an Environment
We can now create the environments. We need to initialise a root environment module, create a plan, apply the plan and then destroy the infrastructure.
To create and then destroy the test environment, execute the following:
cd infra/azure/terraform/envs/test
terraform init -backend-config "access_key=<backend storage account key>”
terraform plan -out test.tfplan -var=azure_subscription_id=<sub id> -var=postgres_admin_login=<admin login> -var=postgres_admin_password=<admin login>
terraform apply test.tfplan
terraform destroy -var=azure_subscription_id=<sub id> -var=postgres_admin_login=<admin login> -var=postgres_admin_password=<admin login>
Please note that all infrastructure created above will incur charges.
Create the Pipeline
Azure Service Connections
The pipeline needs to connect to Azure to manage Azure Resources. To enable this, we have to create an Azure Service Connection. See here for more details.
Pipeline Definition
We can define Azure DevOps Pipelines in YAML. The pipeline has three stages, a build stage and two release stages.
Build Stage
This stage will consist of a single job which executes the following tasks:
- Install terraform
- Initialise the test environment module
- Create the test environment plan
- Initialise production environment module
- Create the production environment plan
- Create build artefact
The build artefact contains the test and production environment plans. Azure DevOps will trigger the release pipeline when the build pipeline successfully creates a build artefact.
Test Stage
This stage will apply the test plan to the test environment. It consists of a single deployment job which will execute the following tasks:
- Download build artifact
- Install terraform
- Apply test plan
Prod Stage
This stage will apply the production plan to the production environment and will require approval to execute. It also consists of a single deployment job which will execute the following tasks:
- Download build artifact
- Install terraform
- Apply test plan
Environments
We will create two environments in Azure DevOps pipelines and will configure the production environment to require approvals.
Variables
The pipeline requires the following variables:
- backend-access-key: The backend storage account access key
- azure-subscription-id: The subscription in which we will create the resources
- test-admin-login/ test-admin-password: Credentials for the test PostgreSQL DB
- prod-admin-login/ prod-admin-password: Credentials for the prod PostgreSQL DB
Pipeline Tests
The release stages should also execute tests to ensure the application is operational after each update. If a test fails then the pipeline should not promote the artefact to the next stage.
Pipeline Triggers
Ideally, each commit should trigger the build pipeline. When the build pipeline successfully creates an artefact, it triggers the release pipeline, which will automatically execute the Test stage and deploy to the Test environment. This will keep the deltas between deployments to the Test environment small and will make it easier to debug errors when they occur. Deployment to the production environment could be automatic, scheduled or manual.
Plans are Diffs
Terraform plans are diffs between the current state of an environment and the desired state. If multiple changes are queued for deployment and an older change is deployed before more recent changes, the more recent changes are invalidated. We should not deploy they more recent changes as they were generated using a now invalid state and we should create a new build which contains any pending changes.
Conclusions
As we have seen, we can use infrastructure as code tools such as Terraform to automate infrastructure deployments. We have used Terraform, Azure DevOps and Azure in this example but we can implement pipelines using other tools such as Ansible or Pulumi. We can also target other cloud providers as these tools support multiple clouds.
Finally, creating CI/CD pipelines for our infrastructure has many benefits:
Testing
We can test most infrastructure changes in test environments before we apply them to production. We can also add functional and non-functional tests to the pipeline to check if the application is operational, secure and performant after each deployment.
Quality Gates
We can use quality gates to prevent invalid updates deploying to production. If a test stage fails to deploy or additional tests fail the production environment will not change. We will create a new build to address the errors encountered in the test environment.
Improved Visibility and Audit Trails
The pipeline acts as a single source of truth and we can use it to understand the state of our environments. We can also easily identify the commit (or commits) that produced a build artefact which can help with debugging and error triage. Finally, most build and release automation systems contain historical logs and change audit trails.
Fewer Errors and Repeatable Results
The pipeline automates all tasks involved in deploying infrastructure updates. This reduces errors that occur during manual deployments and ensures deployments are executed consistently.
It’s all Code
If we can implement the pipeline in code (normally YAML) then we can use software development techniques to improve code quality:
• Revision code using a source control system
• Pull requests and code reviews ensure changes are valid
• Pair programming improves code quality

Top comments (0)