Hi everyone 👋
I recently watched a section of the course The Complete Git Guide by Bogdan Stashchuk, where he explains the internals of how git versions our project files and I think it really helped me to understand this tool. So that's why I want to share with you this knowledge in this blog post.
Git commands used in this tutorial
- git ls-files -s: List the objects that are on the staging area
- git cat-file -p: Get the contents of a git object
- git cat-file -t: Get the type of a git object
Diagram of our git repository
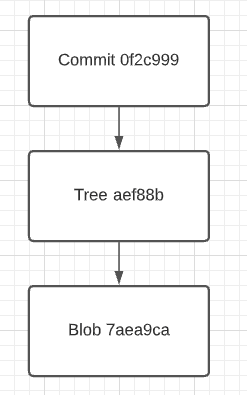
Diagram after committing a new file

Object types in git
Before going straight into details on how git saves the version of our files, let's first understand the 4 object types of git:
- Blobs: this are like files. A blob is composed by the type of object, the size of the object, a delimiter, and the contents of the file.
- Trees: this are like directories. A tree is composed by a list of blobs and trees that the project has.
- Commits: the commits are like special snapshot of a repository.
- Tags: We will not cover this object type in this post.
Git stores all of this objects in the .git/objects directory of every repository as files compressed in binary format.

How does git version a single file?
Each time we make a commit of some changes on a repository, git automatically creates the necessary blobs, trees and commits to save the version of our files.
To demonstrate you this, Let's create a new git repository.

Now, if we take look into our .git/objects directory, we'll see that there are any objects in the repo. (Ignore the info and pack directories)

Next, to see some objects, let's add a new file and stage the changes.

The action of adding changes to the staging area, created a new blob object. To see this new object we can either run git ls-files -s command.
![]()
If we take a closer look to the output of this command we will find that we have hash for this object. This hash serves as a unique identifier for this version of the file, and we actually get can the contents of this file just by appending this hash to the git cat-file -p <hash> command.

Also we can get the type of the object by using the -t flag.
![]()
We can even take another look into .git/objects and we'll see a new file and folder has been created for this blob object.


What about trees and commits?
We have seen how git creates a version of the file just by adding a new file to the staging area.
Now, to see how git creates a new tree and associate this to a commit.
To do so we only need to run git commit.

We can see from the output that a new hash for the commit has been created. That means we can use git cat-file -p to examine the contents of this new commit object.

Now we see that git created not only a new object for our repository, but also a new tree. Let's now get the contents of this tree.
![]()
There we can see a list of all blobs and trees that has this project version. For now, we can only see one blob object is listed, but as we continue adding more files, we will see more in that list.
It is important to note that every time we make a change to the current state of the project and commit those changes, git will automatically create a new commit and tree with new hashes and may create new blob objects if there were files modified or added.

Top comments (0)