
Facebook, one of the world's largest social media platforms, handles billions of requests per second and stores trillions of key-value pairs. To manage this scale, Meta uses Memcached, a simple Key-Value cache that stores data in memory. Since users consume a lot of content than they create caching had significant advantages. It reduced latency, reduced load on database servers, and much more. In this blog, we'll explore Meta's strategy for scaling their Memcached clusters to handle their high demand and discuss optimizations in these areas to improve performance and storage.
Optimizing clusters and regions of Memcache servers.
Optimizing a single Memcached server
Optimizing Clusters to Reduce Latency for Memcached
When scaling to thousands of servers per cluster, we run into some interesting problems
Increased latency due to the distributed nature in which the data is stored. Since each web server has to get the data from multiple cache servers, the latency increases.
Thundering Herd can occur when there is a cache miss and can severely affect the database servers.
Cascading failures can happen when one Memcached server goes offline and it puts additional strain on other servers
Users might get stale data if the cache invalidation method is not optimal.
So let's discuss how to solve each issue in detail
Reducing Latency by using TCP for Set and Delete, and UDP for Get Requests
-
For GET requests, we use UDP.
- Unlike TCP, UDP is connectionless (No connection needs to be established between the source and destination before you transmit data), so it reduces latency and overhead.
- Also, for GET requests, web servers can directly connect to the Memcached server (instead of connecting through the proxy). This further reduces the overhead.
- NOTE: We can use UDP for GET requests because GET requests do not change the state of the cache. So even if the request fails (which might happen because UDP is unreliable) it won't cause data inconsistency.
-
FOR SET and DELETE requests, we use TCP
- Since UDP is unreliable, we use TCP to perform these operations. Also, these requests are routed through the proxy.
Parallelizing and Batching Requests to reduce latency
To reduce latency, we need to minimize the number of round trips for fetching the data. To do so, we can parallelize the requests. But some data are dependent on other data i.e., we need to fetch the 'parent' data and use it to fetch the 'child' data (look at the example below). So, a Directed Acyclic Graph can be constructed. Now, for the data points that do not have any dependencies, we can send parallel requests to fetch them.
Ex:

Preventing Congestion
Sending a lot of requests parallelly can cause congestion. This can slow down responses, increase load on the Memcached servers, and in the worst case the server can crash. To prevent this from happening, the number of outstanding requests must be controlled. To do so, web servers use a sliding window.
In a web server, there is a sliding window for each Memcached server. If the request was successful, the sliding window size increases, but if the request failed it shrinks.
When the window size is very small, the web server has to wait more before sending a request and when the window size is very large the number of parallel requests can cause congestion. So the balance between these two extremes is where we prevent congestion and minimize latency.
Optimizing Clusters to Reduce Load on Servers
Reducing Load (on Databases) using Leases
This is one of my favorite techniques in this entire blog. This mechanism not only reduces load (and thereby prevents thundering herds) but also addresses the issue of stale data and is quite intuitive. But before discussing the solution let's understand in what scenario will the load on database servers increase.
Suppose 1000 web servers requested a key, but it is missing. Now all 100 web servers make requests to the database server. Now the database server has to 1000 servers at once which can cause it to crash. We call this scenario Thundering Herd.
Stale data can be added to the cache due to race conditions. Have a look at the illustration below to understand how it happens
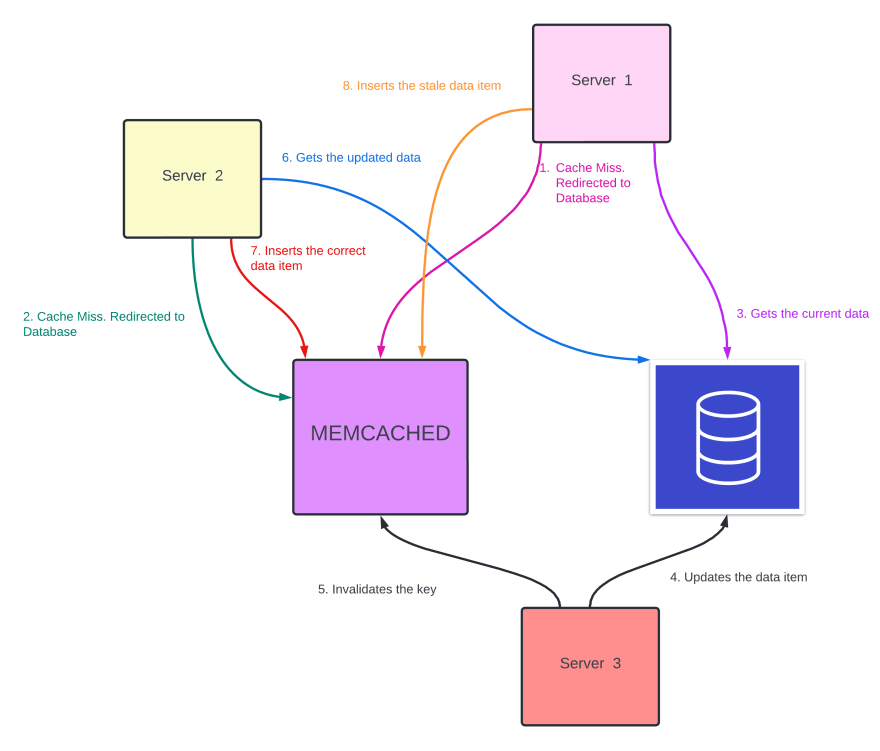
A lease is a 64-bit token that is associated with a key. When there is a cache miss, a lease is assigned to the web server that experienced the cache miss.
The Memcache server regulates the rate at which it assigns a lease token (usually 10 seconds). So, within 10 seconds if any other web server requests for the key, they get a special responsibility to wait for a short amount of time. This prevents Thundering Herd because instead of sending requests to the database, now the web servers wait for the cache to be updated with the required value.
Only those servers can update the cache that has the lease token. If the data value is updated in the database, then the key is invalidated in the cache and so is the lease token. In that case, a new token is assigned to the servers that experience cache miss. So we can be ensured that only the latest value is added to the cache. Therefore it also solves the stale data issue.
Assigning different Pools for different types of data
Different types of data have different access patterns, memory footprints, and quality of service requirements. They can negatively affect each other so they are assigned different server pools.
E.g. A small pool of Memcached servers can be assigned for the keys that are accessed frequently but a cache miss is cheap (A smaller pool means less time is required to search the key) and a large pool for keys that are accessed infrequently but a cache miss is expensive.
Distributing Read Requests across the Replicas
We can create replicas of the Memcached servers within the same pool and replicate the keys. Now when we get read requests, we can distribute them across all the replicas. This reduces the load from the main Memcached server.
Preventing Cascading Failure
In a distributed system, servers going offline is a norm rather than an exception. To mitigate outages a small set of servers known as Gutter is used. It is just a Memcached server that is only used when any other Memcached server is offline. When the server sends a request to the Memcached server but does not receive any response, it assumes the server is offline and sends the request to the Gutter Pool.
There is another approach, where the key is rehashed and assigned to another server. This is not preferred because it can cause a cascading failure.
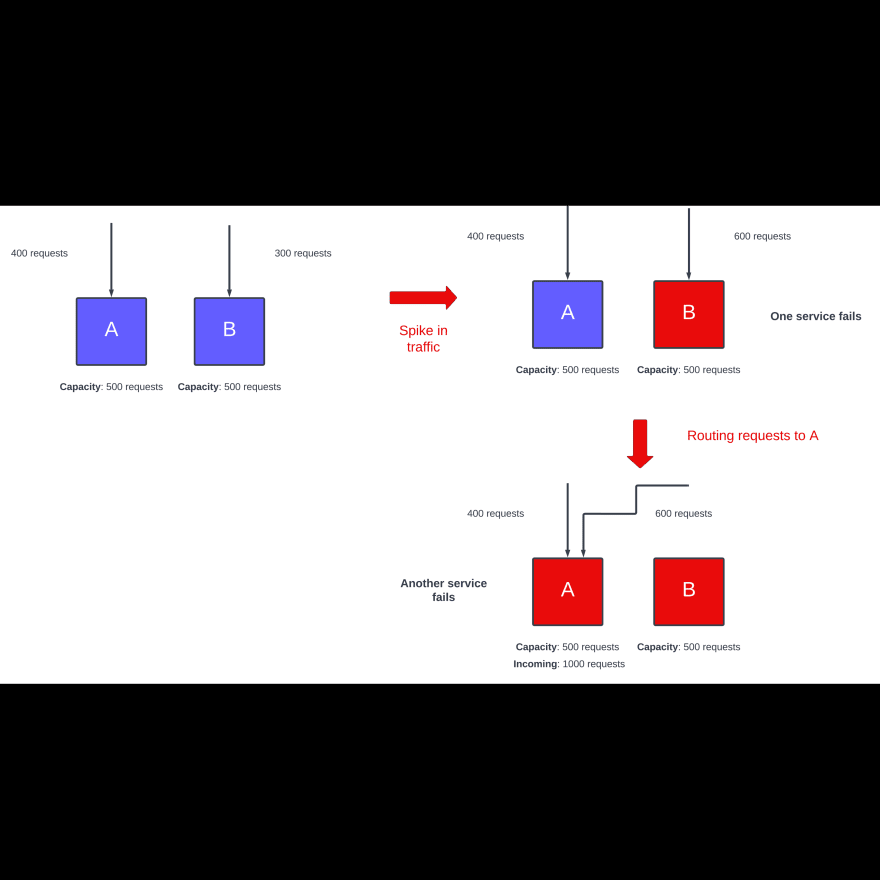
Image credits: https://interviewready.io/blog/ratelimiting
For instance, if a highly requested key is assigned to another server, then it might overload that server and crash it. Now, again it'll be assigned to a different server and repeat the same thing as above.
It'll continue until many servers crash due to overload, so using Gutter servers is a better option.
Improving Performance by using regions of Memcached servers
There is an upper limit to how many servers we can add to a cluster before the congestion worsens. Therefore it is better to split the web and Memcached servers into multiple frontend clusters. These clusters, along with a storage cluster that contains the databases, define a region.
Making regions of Memcached servers has many benefits like reduced latency because the servers are near the end users. It also mitigates the effects of large-scale power outages, natural calamities, etc. This makes the system more reliable and available.
Removing stale data from Memcached servers in different regions
A single key-value pair may be replicated to multiple Memcached servers in different regions. So, when the data is updated in the database, we have to invalidate the data from those servers. To do so, the following procedure is followed
SQL statements that modify the state have the required Memcached keys embedded in them.
Each database server also has an invalidation daemon called McSqueal. It analyzes the SQL statement, extracts the keys, and broadcasts the updates to different regions.
McSqueal also batches requests to reduce the number of data packets. These packets are then unpacked by the Memcached proxy (Mcrouter).
Optimizing a single Memcached server
A single server can easily become the bottleneck, so it is important to optimize the Memcached server.
Using Adaptive Slab Allocator for Better Memory Management
Allocating and Deallocating memory randomly causes Memory Fragmentation.
Memory fragmentation is when the sum of the available space in a memory heap is large enough to satisfy a memory allocation request but the size of any individual fragment (or contiguous fragments) is too small to satisfy that memory allocation request

It increases the read time as the memory gets more and more fragmented. To prevent this, Memcachedpre- allocates a large chunk and divides it into slab classes. The size of slab classes starts from 64 bytes up to 1MB. It stores the data in the smallest possible slab that can fit the data item.
Each slab class maintains a list of available memory and requests for more memory when this free list is empty.
Now, it is worth noting that there might be some wastage of memory inside a slab if the data item is smaller than the slab size (it is called internal fragmentation). But it does not degrade the performance as much as external fragmentation.
Choosing the right eviction policy
Memcached uses LRU (Least Recently Used) eviction policy. Each Slab class has its own LRU data structure (generally we use a linked list). When it cannot allocate any more memory in a slab, the least recently used (in other words, the oldest items) is evicted from the slab class.
This approach has one issue - The eviction rate across slab classes is unbalanced. This can cause performance issues as one slab is constantly evicting and adding data items, while other slabs are not being used. To prevent this, it is important to identify the slabs where the eviction rate is high and the evicted keys can be assigned to other slabs.
So, if a slab class is evicting a data item and it was used at least 20% (this a threshold) more recently than the average of least recently used items in other slab classes, then the data item is moved to any other class.
Reducing Memory Usage by removing short-lived keys
Memcached evicts an item
When the expiration time of the item has exceeded while serving a GET request.
Or, when the item has reached the end of LRU
In short, it removes the data items lazily. Short-lived keys that see a single burst of activity waste memory, until they reach the end of LRU.
To solve this issue, a hybrid method is used to lazily evict most keys and quickly evict short-lived keys when they expire. All the short-lived items are placed in a circular buffer of a linked list. We have a head pointer that iterates over the circular buffer and advances by one each second. Each second, all of the items in the bucket at the head pointer are evicted and the head pointer advances by one.
Using Multi-threading to boost performance
The Memcached server is multi-threaded to boost performance.
To prevent race conditions, a global lock is used to protect the data structures.
If a single port is used to connect to web servers, then it can easily bottleneck the whole server, so each thread is given its own UDP port.
In conclusion, Meta's strategy for scaling their Memcached clusters to handle their high demand involves optimizing clusters and regions of Memcached servers as well as optimizing a single Memcached server. They use techniques such as using TCP for Set and Delete requests, UDP for Get requests to reduce latency, parallelizing and batching requests to minimize round trips, and preventing congestion using a sliding window mechanism. They also use leases to reduce the load on databases and prevent thundering herds, and implement cache invalidation methods to address stale data issues.
These optimizations not only help reduce latency and load on servers, but also prevent cascading failures, thundering herds, and stale data issues, resulting in improved performance and storage for Meta's Memcached clusters. With these strategies in place, Meta can handle billions of requests per second and store trillions of key-value pairs, efficiently serving content to their users and maintaining a seamless user experience on their social media platform.
References
Memcached White Paper: https://www.usenix.org/system/files/conference/nsdi13/nsdi13-final170_update.pdf
Memcached architecture crash course: https://www.youtube.com/watch?v=NCePGsRZFus

Top comments (0)